7.8.2 项目:垂直领域微调
垂直领域微调项目最容易流于一句空话:
- “做一个行业专家模型”
真正有作品集价值的项目,通常更像:
把一个范围明确、边界清楚、评估可做的领域问答任务,做成一个 before/after 对比很清楚的系统。
这一节会把这条线真正走清楚。
学习目标
- 学会把“领域微调”题目收窄成一个可执行项目
- 学会把原始知识整理成 SFT 数据和评估集
- 学会做出真正有说服力的 baseline 对比
- 学会把这个项目展示成作品级页面
一、项目选题为什么必须先收窄?
大题目几乎都做不动
例如:
- 做一个行业专家大模型
这类题目通常边界太宽, 很难明确:
- 输入是什么
- 输出是什么
- 什么叫答对
更适合作品集的题目
例如:
电商售后政策助手:专注退款、地址修改、发票和售后流程四类问题。
这个题目好在:
- 范围窄
- 语义稳定
- 评估标准好设计
二、作品级微调项目最小闭环长什么样?
- 定义任务边界
- 整理知识与对话样本
- 做 baseline
- 整理 SFT 数据
- 建评估集
- 训练并做 before/after 对比
只要这 6 步清楚,你的项目就已经很有说服力。
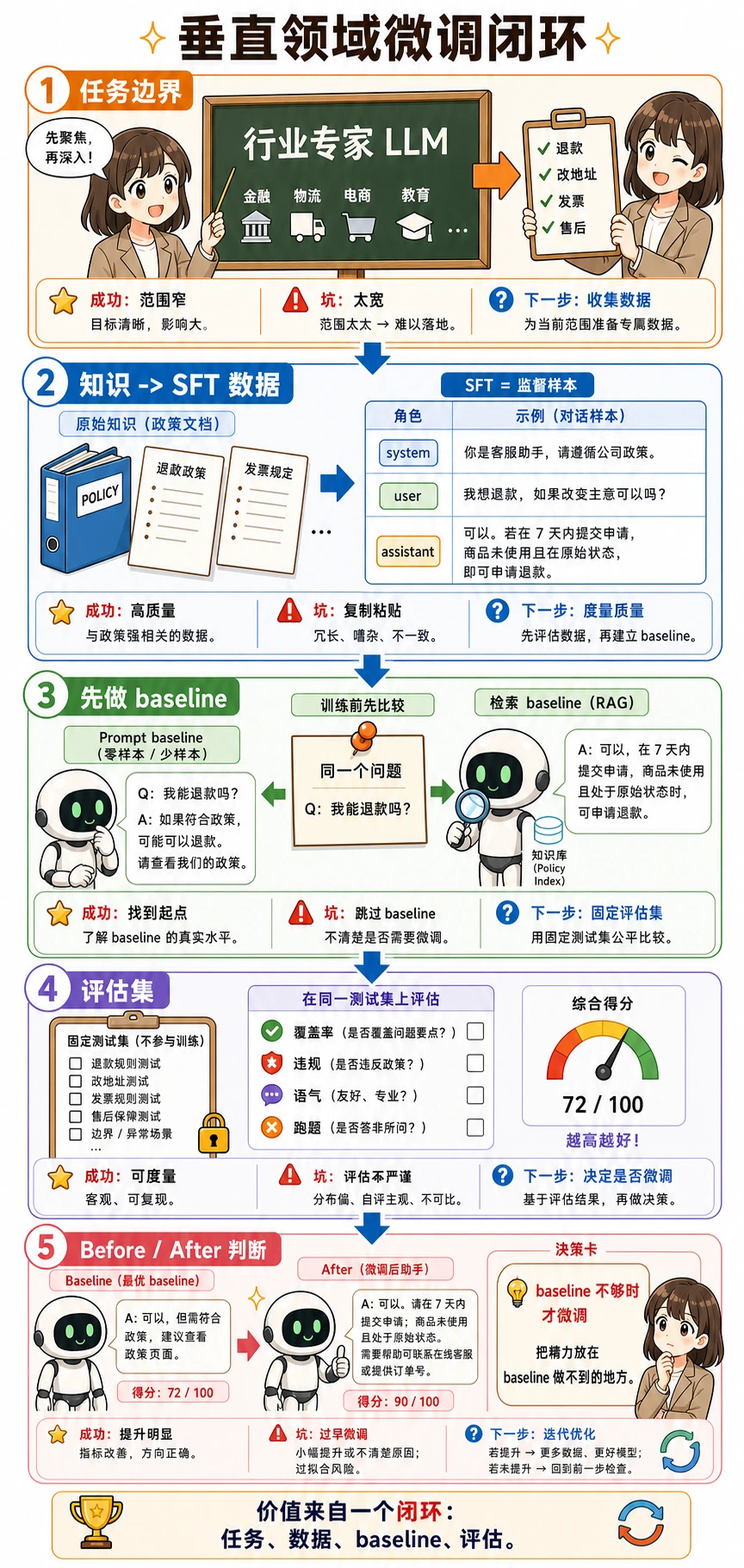
这张图建议从上往下读:先收窄任务,再把原始知识整理成 SFT 样本,训练前先比较 baseline,用固定评估集检查效果,最后才判断微调是否值得付出额外成本。
三、推荐推进顺序
对新人来说,更稳的顺序通常是:
- 先把题目范围收窄
- 再做 Prompt / 检索 baseline
- 再整理 SFT 数据
- 最后才做微调和 before/after 对比
这样项目才更像“判断之后的微调”,而不是“为了微调而微调”。
读代码前先看懂几个项目词
| 术语 | 新人友好解释 | 在本节里的作用 |
|---|---|---|
| LLM | Large Language Model,大语言模型,会按 token 逐步预测和生成文本 | 本项目要调整的就是 LLM 在垂直领域任务里的行为 |
| Prompt | 推理时发给模型的指令、上下文和约束 | 它是第一个 baseline,因为成本比训练低 |
| RAG | Retrieval-Augmented Generation,检索增强生成,回答前先从外部资料里找相关内容 | 当模型缺少最新知识或私有资料时,优先考虑它 |
| 微调 | 在任务专属样本上继续训练模型 | 当模型需要稳定风格、格式或判断模式时更有价值 |
| SFT | Supervised Fine-Tuning,监督微调,用人工或可靠数据整理出的输入/输出样本训练模型 | 它告诉模型“好答案应该长什么样” |
| baseline | 在复杂方法之前先做的最简单对比系统 | 防止没有证据就说“效果提升了” |
| 评估集 | 一组固定测试问题,不能拿来训练 | 用来判断新方案是否真的能处理没见过的样例 |
| 覆盖率 | 答案覆盖了多少个必须出现的政策点 | 把“看起来不错”变成更可度量的分数 |
四、先看一个更完整的数据与 baseline 示例
下面这个例子会同时体现:
- 原始记录
- SFT 样本
- 两个 baseline
- 评估规则
这段代码只使用 Python 标准库。可以保存为 domain_finetune_demo.py,然后运行 python domain_finetune_demo.py。
raw_records = [
{
"intent": "refund_unshipped",
"question": "订单还没发货,可以直接退款吗?",
"policy_points": ["未发货可直接申请退款", "退款原路返回", "到账时间 3 到 7 个工作日"],
"evaluation_keywords": [["未发货"], ["原路"], ["3 到 7", "工作日"]],
"answer": "可以。如果订单尚未发货,您可以直接申请退款,款项会原路退回,通常 3 到 7 个工作日到账。",
},
{
"intent": "change_address",
"question": "收货地址填错了,还能改吗?",
"policy_points": ["未出库可修改地址", "已出库需联系人工客服"],
"evaluation_keywords": [["未出库"], ["人工客服", "已出库"]],
"answer": "如果订单尚未出库,您可以在订单详情页修改地址;若已经出库,请联系人工客服处理。",
},
{
"intent": "invoice",
"question": "发票什么时候可以开?",
"policy_points": ["订单完成后可申请", "电子发票发送到邮箱"],
"evaluation_keywords": [["订单完成"], ["电子发票", "邮箱"]],
"answer": "订单完成后可在发票中心申请开具,电子发票会发送到您预留的邮箱。",
},
]
def build_sft_record(row):
system = "你是电商售后政策助手,请用礼貌、准确、符合平台规则的方式回答用户问题。"
return {
"messages": [
{"role": "system", "content": system},
{"role": "user", "content": row["question"]},
{"role": "assistant", "content": row["answer"]},
],
"intent": row["intent"],
"policy_points": row["policy_points"],
}
def generic_baseline(question):
if "退款" in question:
return "一般可以申请退款,具体以订单状态为准。"
if "地址" in question:
return "建议尽快联系客服处理地址问题。"
if "发票" in question:
return "发票通常可以申请,具体规则请查看页面说明。"
return "请联系平台客服获取帮助。"
def retrieval_baseline(question, records):
best = max(records, key=lambda row: overlap(question, row["question"]))
return best["answer"]
def tokenize(text):
punctuation = ",。!?;:“”‘’、()()[]{}"
words = [char.strip(punctuation) for char in text]
return {word for word in words if word}
def overlap(a, b):
return len(tokenize(a) & tokenize(b))
def coverage(answer, required_keyword_groups):
matched = [
group
for group in required_keyword_groups
if any(keyword in answer for keyword in group)
]
return round(len(matched) / len(required_keyword_groups), 3)
sft_dataset = [build_sft_record(row) for row in raw_records]
sample = raw_records[0]
generic_answer = generic_baseline(sample["question"])
retrieval_answer = retrieval_baseline(sample["question"], raw_records)
print("question:", sample["question"])
print("generic :", generic_answer, "coverage=", coverage(generic_answer, sample["evaluation_keywords"]))
print("retrieval:", retrieval_answer, "coverage=", coverage(retrieval_answer, sample["evaluation_keywords"]))
print("sft_sample:", sft_dataset[0])
预期输出:
question: 订单还没发货,可以直接退款吗?
generic : 一般可以申请退款,具体以订单状态为准。 coverage= 0.0
retrieval: 可以。如果订单尚未发货,您可以直接申请退款,款项会原路退回,通常 3 到 7 个工作日到账。 coverage= 1.0
sft_sample: {'messages': [{'role': 'system', 'content': '你是电商售后政策助手,请用礼貌、准确、符合平台规则的方式回答用户问题。'}, {'role': 'user', 'content': '订单还没发货,可以直接退款吗?'}, {'role': 'assistant', 'content': '可以。如果订单尚未发货,您可以直接申请退款,款项会原路退回,通常 3 到 7 个工作日到账。'}], 'intent': 'refund_unshipped', 'policy_points': ['未发货可直接申请退款', '退款原路返回', '到账时间 3 到 7 个工作日']}
这段小代码的重点不是做一个生产级检索系统,而是让对比变得可见:通用回答听起来礼貌,但缺少必须覆盖的政策细节;领域相关回答则可以用固定政策点检查。
这个例子为什么比纯“项目规划对象”更值钱?
因为它已经把项目里真正最重要的四件事放出来了:
- 原始数据长什么样
- SFT 样本长什么样
- baseline 结果是什么
- 评估规则是什么
这已经是一个很像真实微调项目的核心骨架。

这张图建议按作品集视角读:任务边界先收窄,SFT 数据要能展示来源和格式,baseline 必须先跑,评估要有政策点覆盖、违规承诺、风格一致性和 before/after 对比。项目值钱的不是“我微调了”,而是你能证明为什么值得微调、提升在哪里。
为什么要先做两个 baseline?
最少建议比较:
- 纯 Prompt / 通用回答
- 检索或简单领域匹配
- 微调后系统
否则你后面很难说清:
- 微调到底提升了什么
如果检索已经很好,什么时候还值得微调?
检索回答的是“模型应该看到哪些知识”,微调回答的是另一个问题:“模型看到输入后应该形成怎样的稳定行为”。如果检索已经能找到正确政策,微调仍然可能在这些场景里有价值:助手必须始终保持固定语气、稳定判断意图、输出严格 JSON schema,或反复执行某种固定推理模式。
| 场景 | 更适合先用什么 | 原因 |
|---|---|---|
| 答案依赖私有资料或经常变化的知识 | RAG | 更新文档通常比重新训练更安全 |
| 答案必须保持稳定风格或结构 | 微调 | 模型会学习重复出现的输出模式 |
| 任务定义本身还不清楚 | 先重写任务和 Prompt | 用混乱样本训练,只会把混乱固化 |
| 输出必须被代码稳定解析 | 先用 Prompt + schema,再看是否需要微调 | schema 约束能暴露问题到底在表达还是行为 |
| baseline 已经通过评估 | 保留简单方案 | 简单可靠的系统通常更容易维护 |
五、微调项目最重要的评估不只是“看起来像专家”
结构化评估点
至少应包含:
- 是否覆盖关键政策点
- 是否有违规承诺
- 风格是否一致
- 是否答非所问
一个更像作品级的展示方式
最推荐展示:
- 同一组问题
- baseline 回答
- 微调后回答
- 逐条说明差异
失败样例非常重要
例如:
- 容易编政策
- 细节答错
- 口吻不稳定
这会比只展示成功案例更像真实项目。
六、怎么把这个项目做成作品级页面?
页面结构建议
- 任务边界
- 数据构造方式
- baseline 对比
- SFT 样本示例
- before / after
- 失败案例
一个很加分的点
把“政策点覆盖率”这种明确规则放出来。 它会让项目显得非常扎实,而不是只靠主观评价。
七、最容易踩的坑
一上来就做大范围题目
这会让评估和数据一起发散。
没有 baseline
没有对比,微调项目几乎站不住。
只展示模型训练,不展示任务判断
项目交付时最好补上的内容
- 一张任务边界表
- 一张 baseline 对比表
- 一组 before / after 问答样例
- 一组失败样例与原因分析
- 一段“为什么这里值得微调而不是只做 RAG / Prompt”的判断说明
项目真正值钱的地方在:
- 题目定义
- 数据组织
- 评估设计
小结
这节最重要的是建立一个作品级判断:
垂直领域微调项目真正有价值的地方,不是“我微调了一个模型”,而是你能否把任务边界、SFT 数据、baseline、评估规则和 before/after 对比讲成一条清楚闭环。
只要这条闭环清楚,这个项目就非常适合拿来展示。
版本路线建议
| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
练习
- 再给原始数据补 5 条样本,让四类意图都更均衡。
- 想一想:如果 Retrieval baseline 已经很好,什么时候微调还值得做?
- 为什么说“政策点覆盖率”比“感觉更像人工”更适合做项目评估?
- 如果把这个项目做成作品集,最值得展示哪 4 个 before/after 样例?