7.8.4 实操:第 7 章完整工作坊
这一节是第 7 章的实操主线。如果你觉得本章概念很多,可以先把这一页从头到尾跑一遍。这里不会训练大模型,而是搭出一条最小但可复现的工程流程:token、请求载荷、Prompt 版本、结构化输出校验、评测、Prompt/RAG/微调方案选择,以及跑完后可以复盘的小型证据包。
每一步都按这个顺序来:先看图,再运行或阅读代码,最后检查打印结果。如果某个概念还不清楚,就回到图上,用手指顺着数据流再走一遍。
你会做出什么
完成后,你会得到一个可运行的 Python 文件,它可以:
- 把学习者请求拆成简单 tokens、token ids 和一个小型向量痕迹。
- 在固定测试样本上比较三个 Prompt 版本。
- 校验“模型式输出”是不是真正包含必需字段的 JSON。
- 判断一个任务应该先用 Prompt、结构化输出、RAG,还是进入微调方案设计。
- 把 token 痕迹、Prompt 评测结果、方案选择、失败案例和 README 保存到一个本地证据文件夹。
- 像工程师一样解释输出:哪里失败、为什么失败、下一步应该改什么。
代码只使用 Python 标准库。这样新人第一次运行不需要 API key、网络或付费模型,也能先看清楚工程流程。
图解检查点:整条路线
写代码前,先把这些第 7 章 image2 教学图按顺序串起来。它们不是装饰,而是本工作坊的地图。
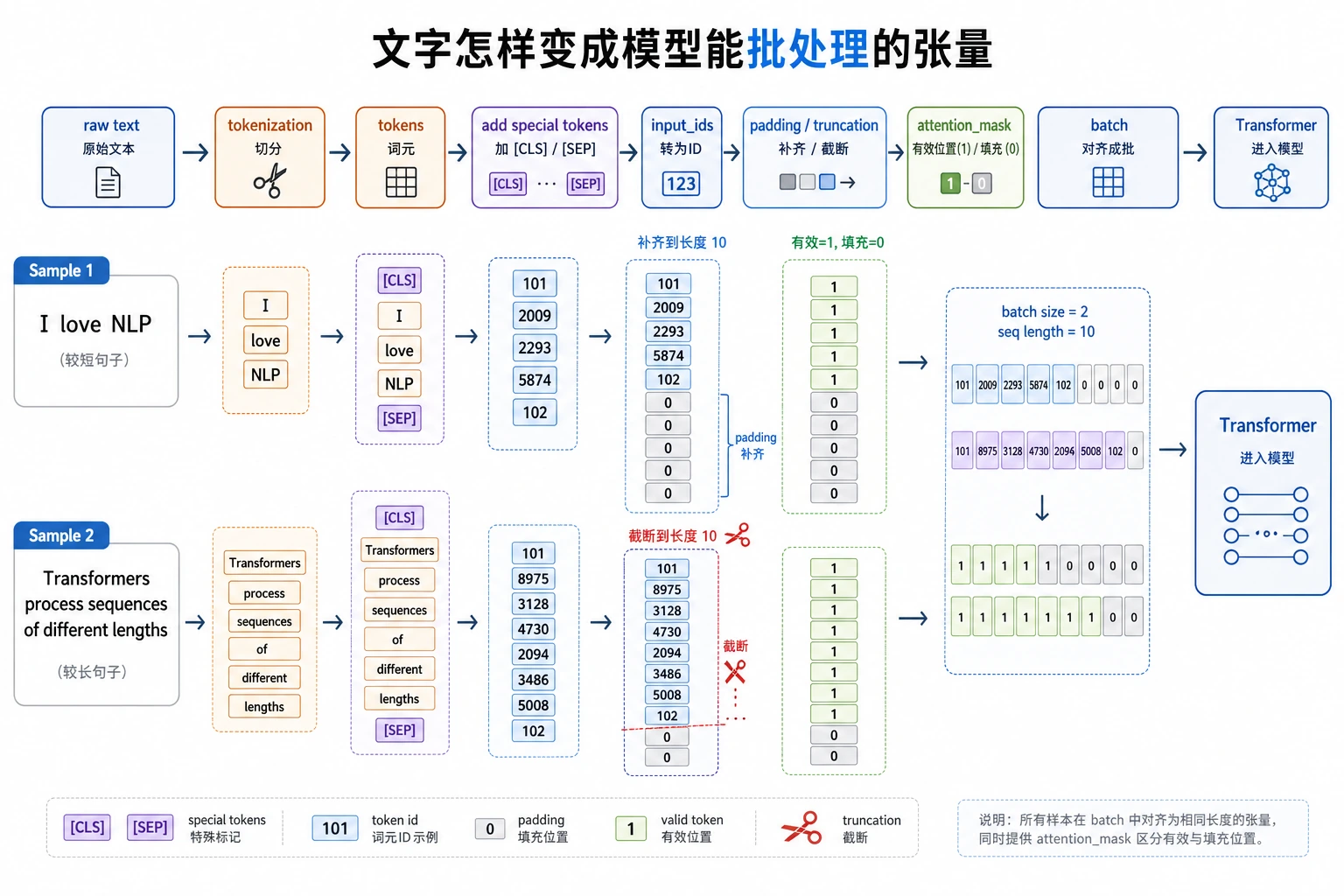
第一步,文本必须先变成 token 和 id,模型才处理得了。
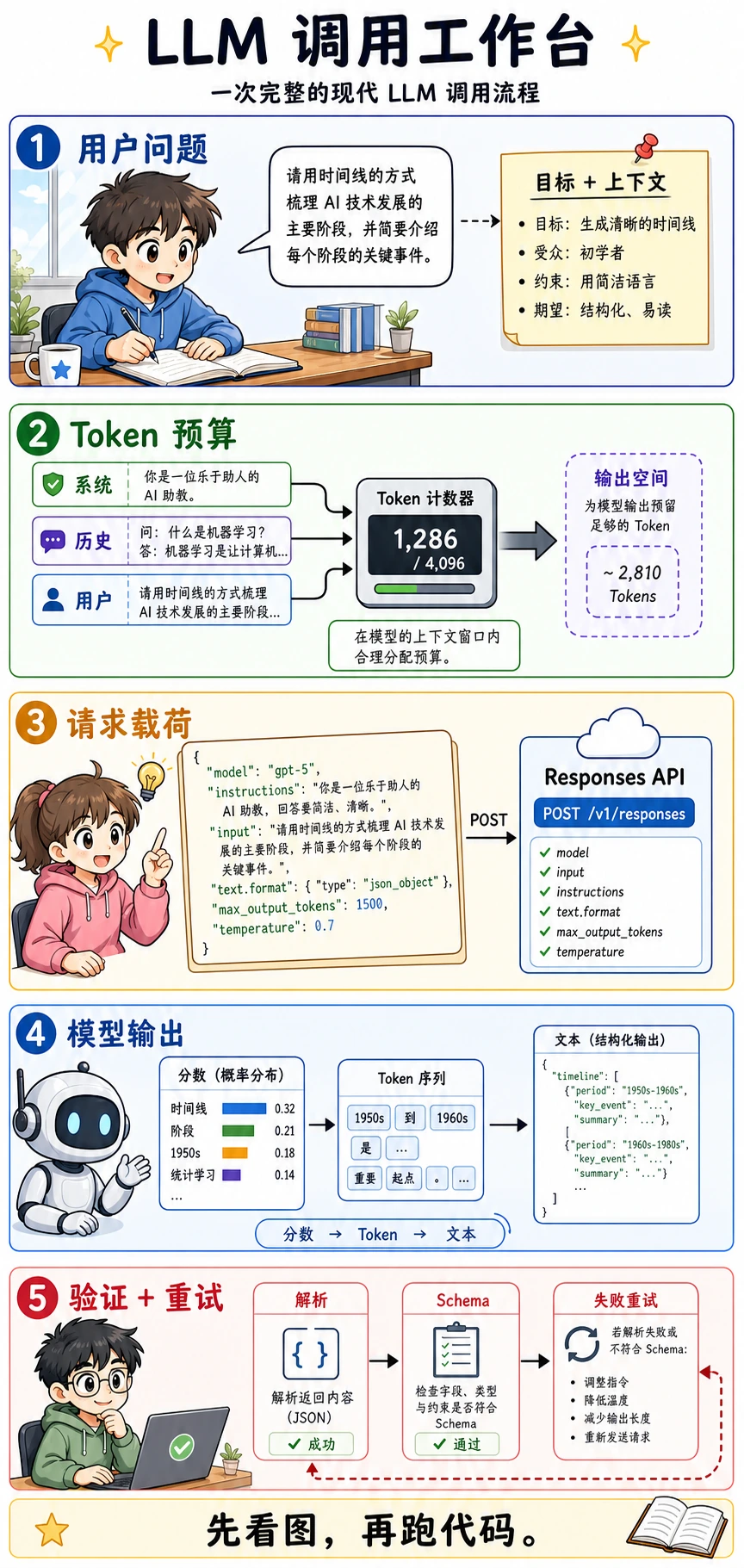
接着,一次模型调用是一个请求载荷,而不只是聊天框里的一句话。
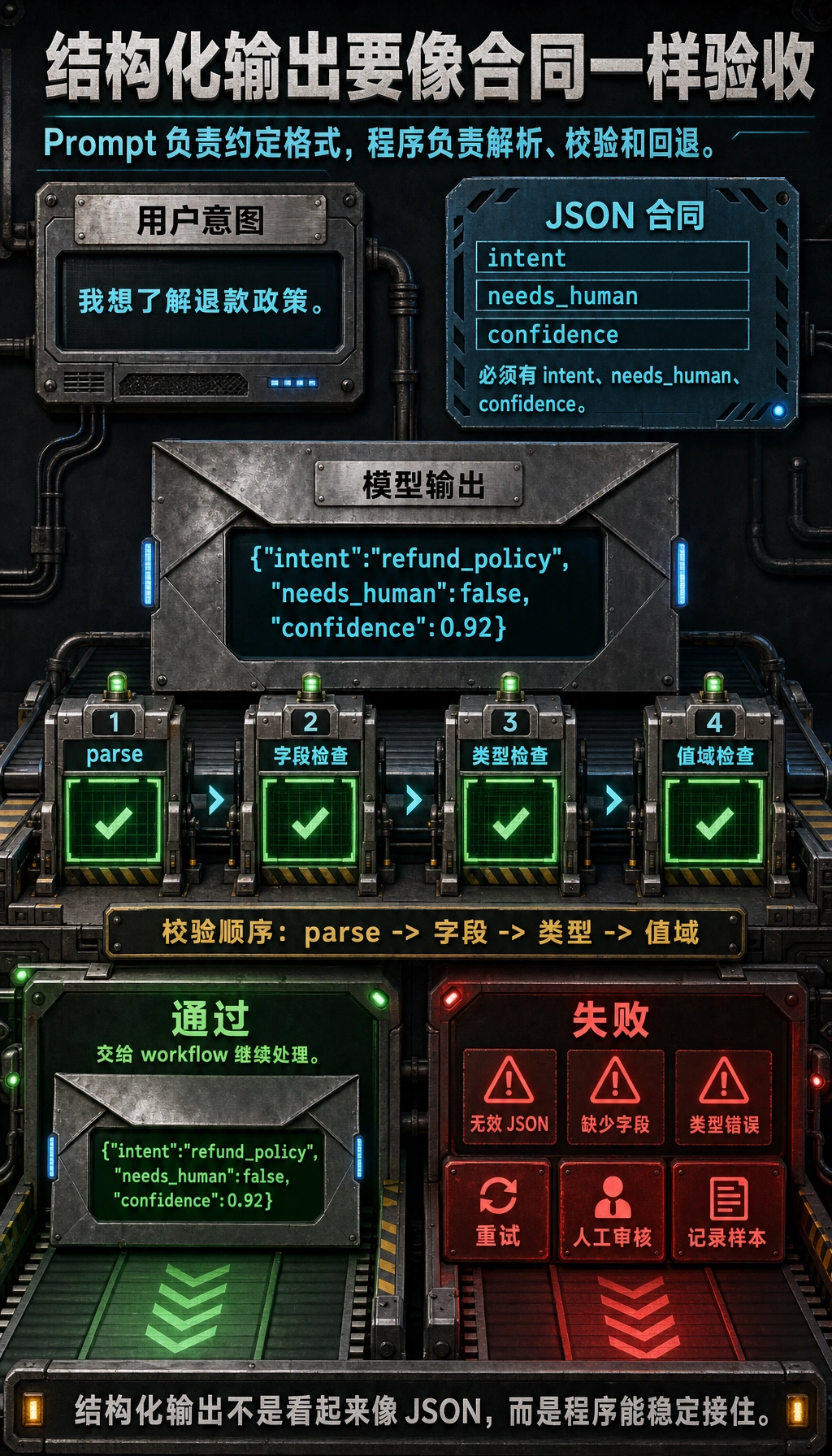
然后,产品代码必须解析并校验模型输出。
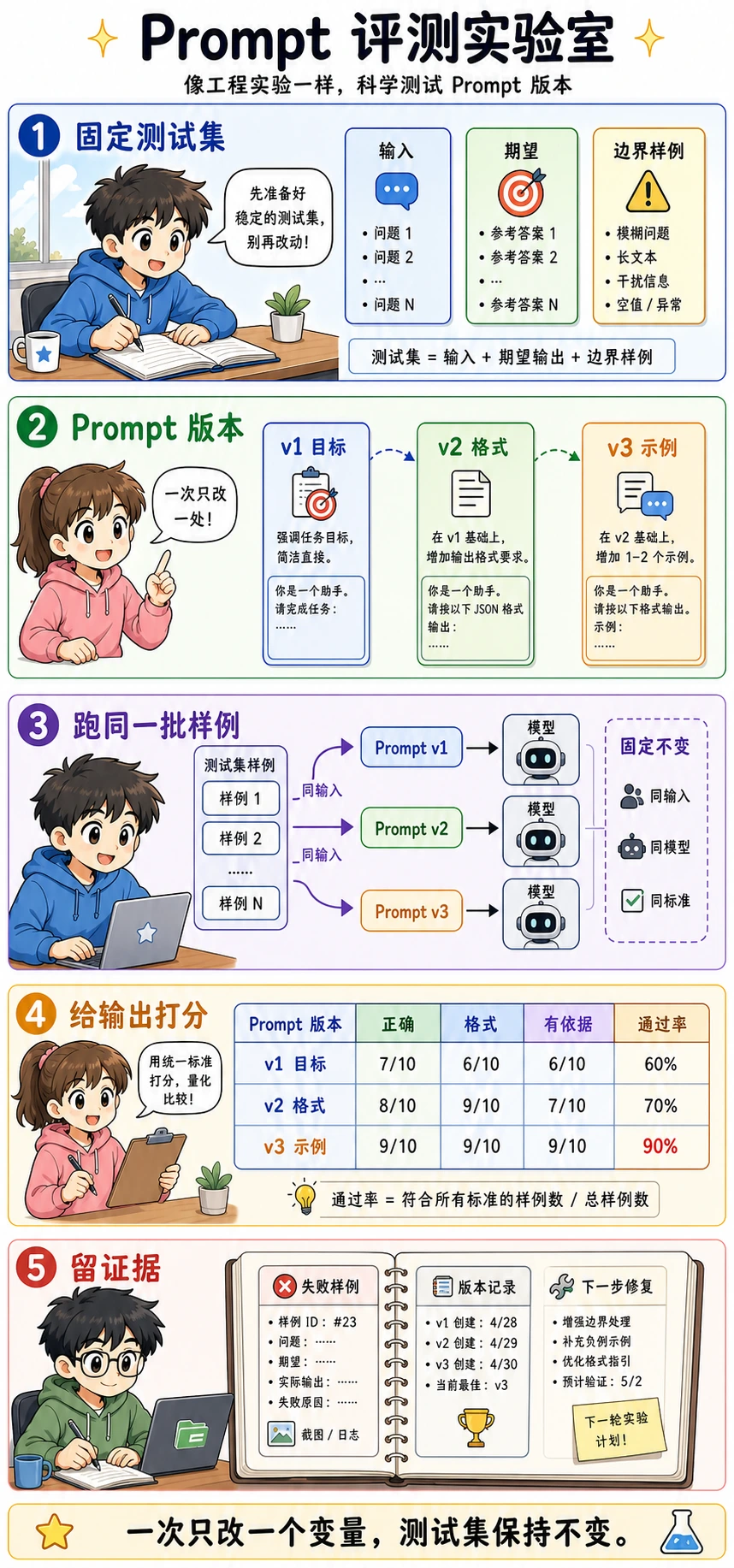
再往后,Prompt 改动要用固定样本评测,而不是凭感觉判断。
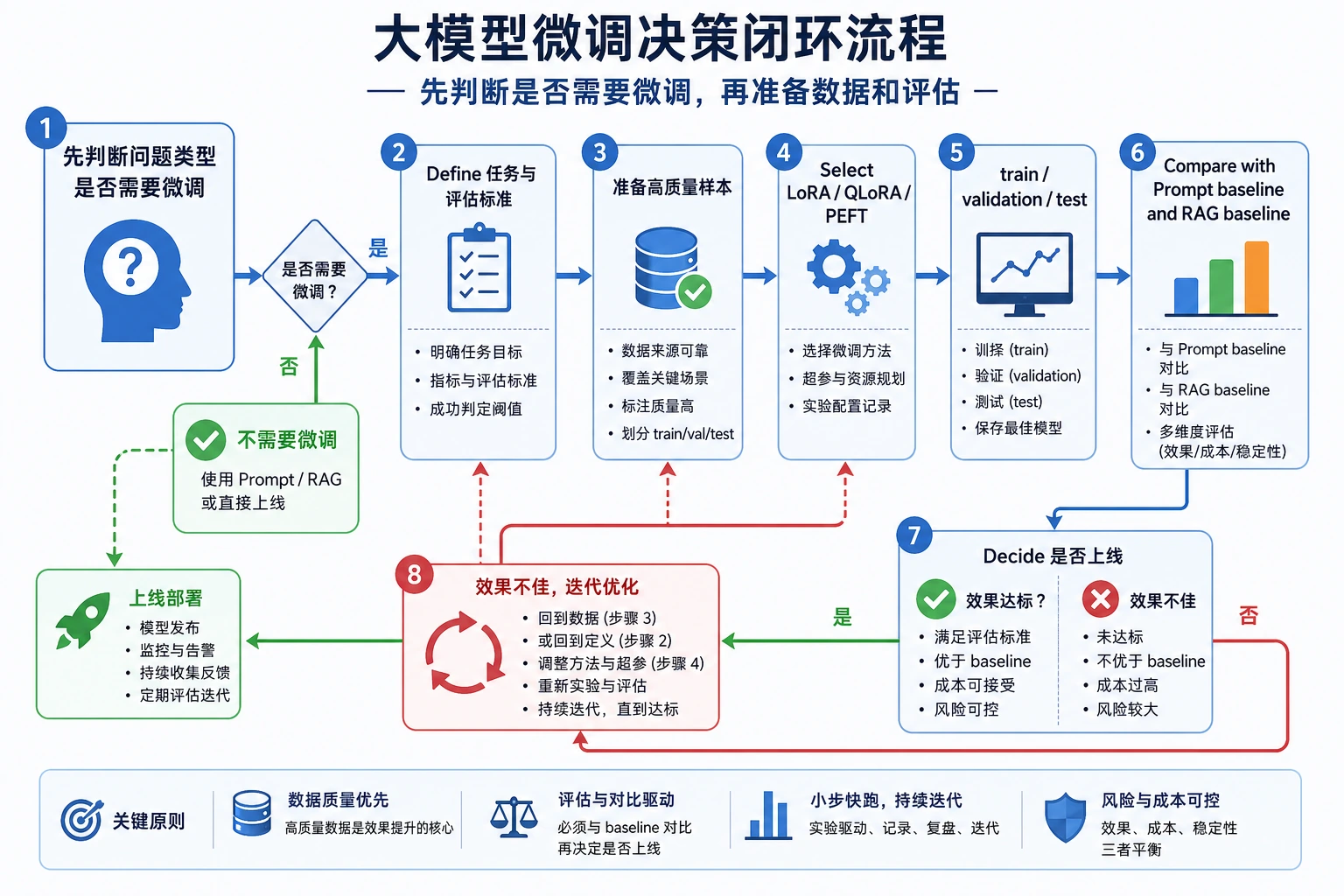
最后,不要一遇到问题就跳到微调。先判断你面对的到底是哪类问题。
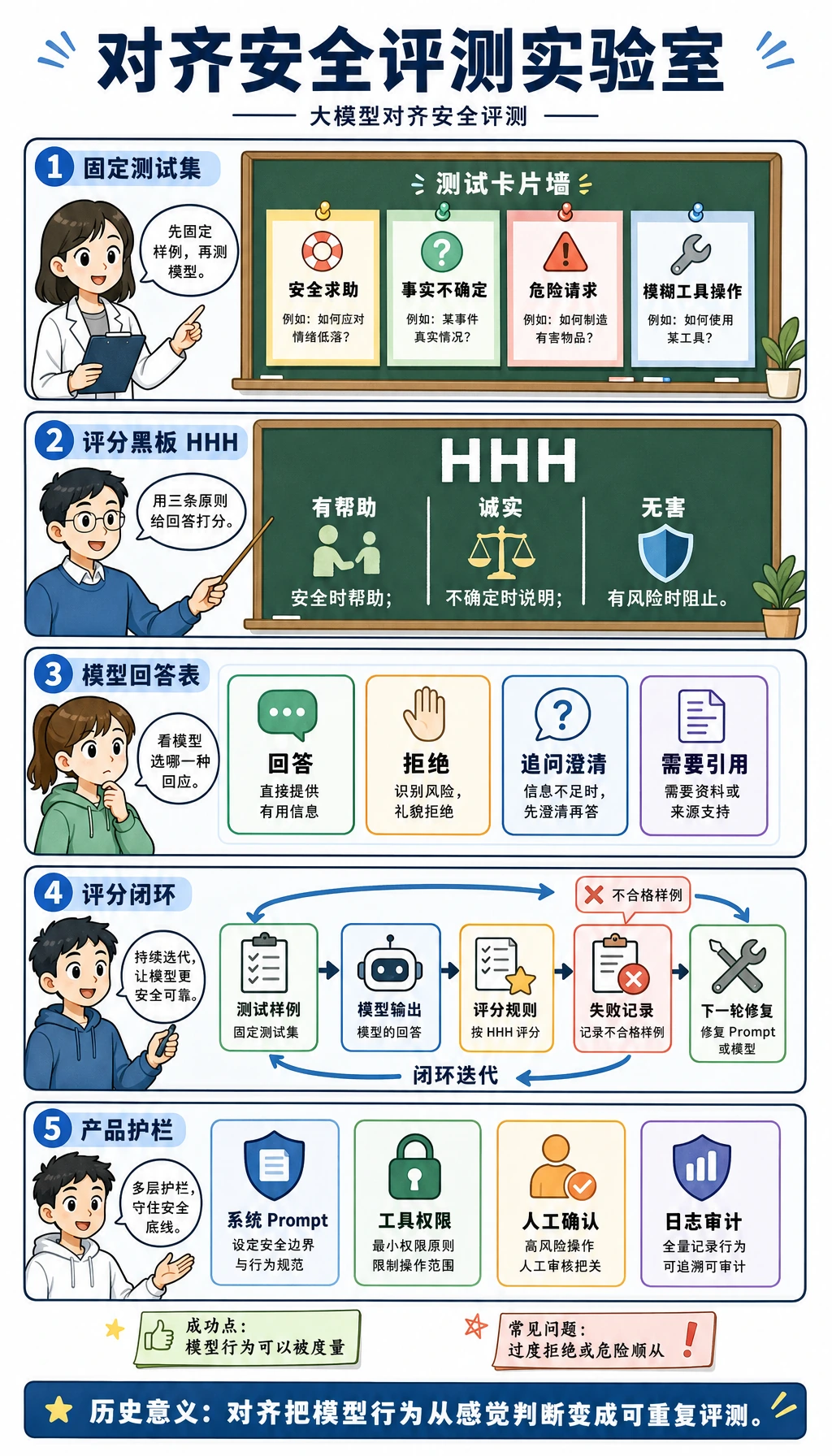
如果任务有风险,要加入行为评测和人工审核边界。
接下来用这些专门为本工作坊准备的图,当作运行时检查清单。
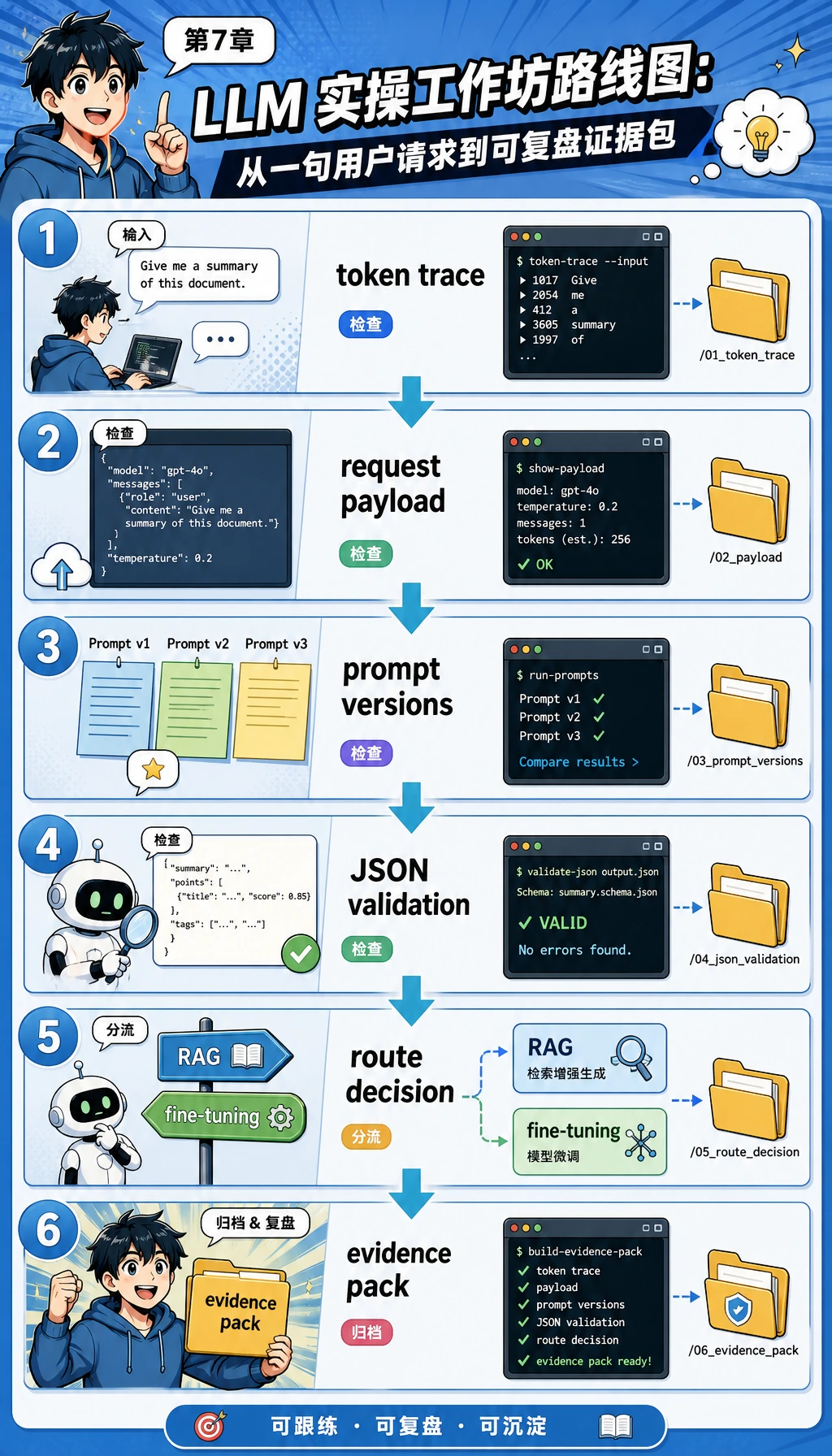
这就是你会在文件中跟着走的路线:tokens、payload、Prompt 版本、校验、方案选择和证据。
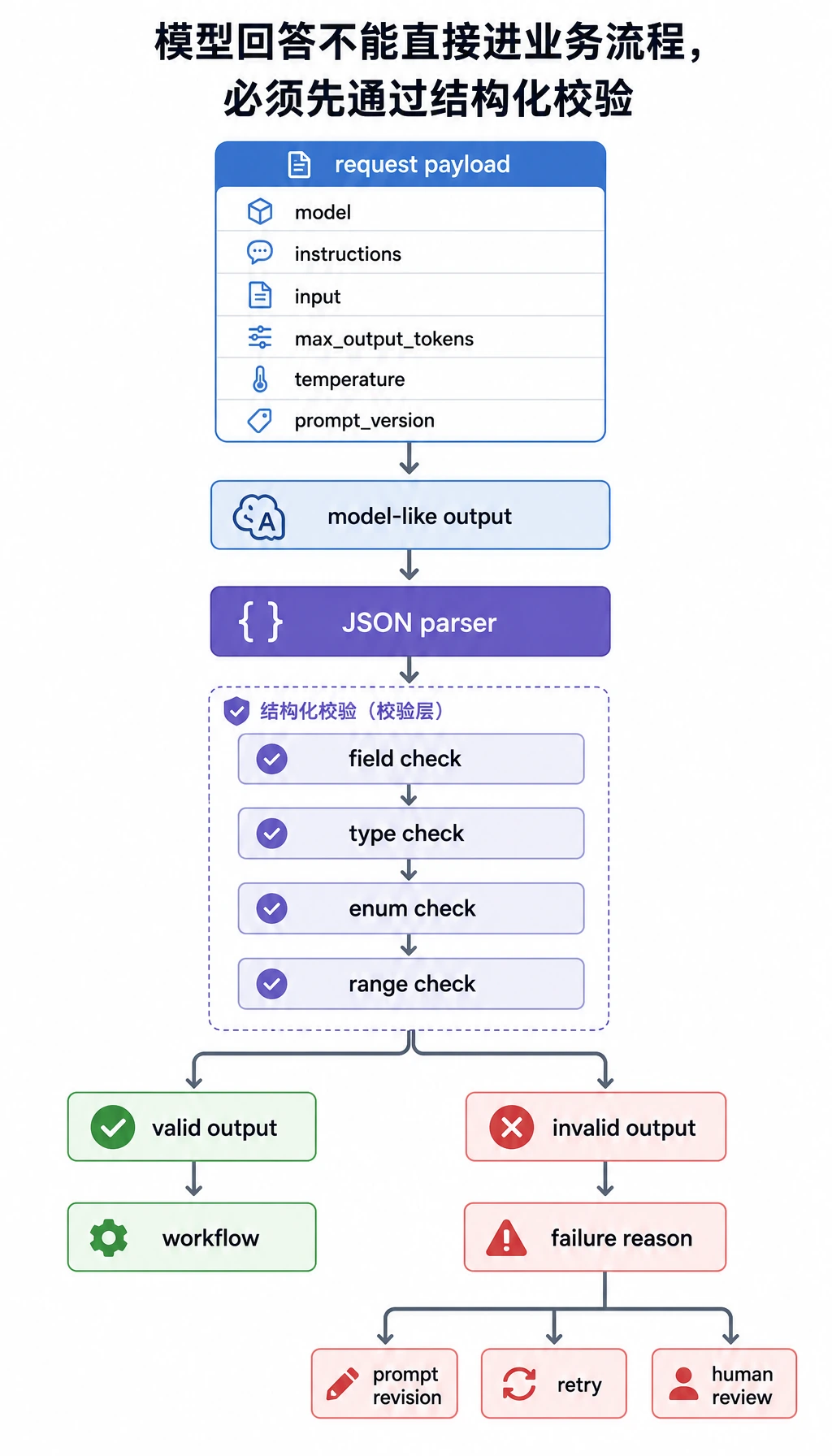
每个“模型式回答”都要先经过解析器、字段检查和类型检查,程序才可以信任它。
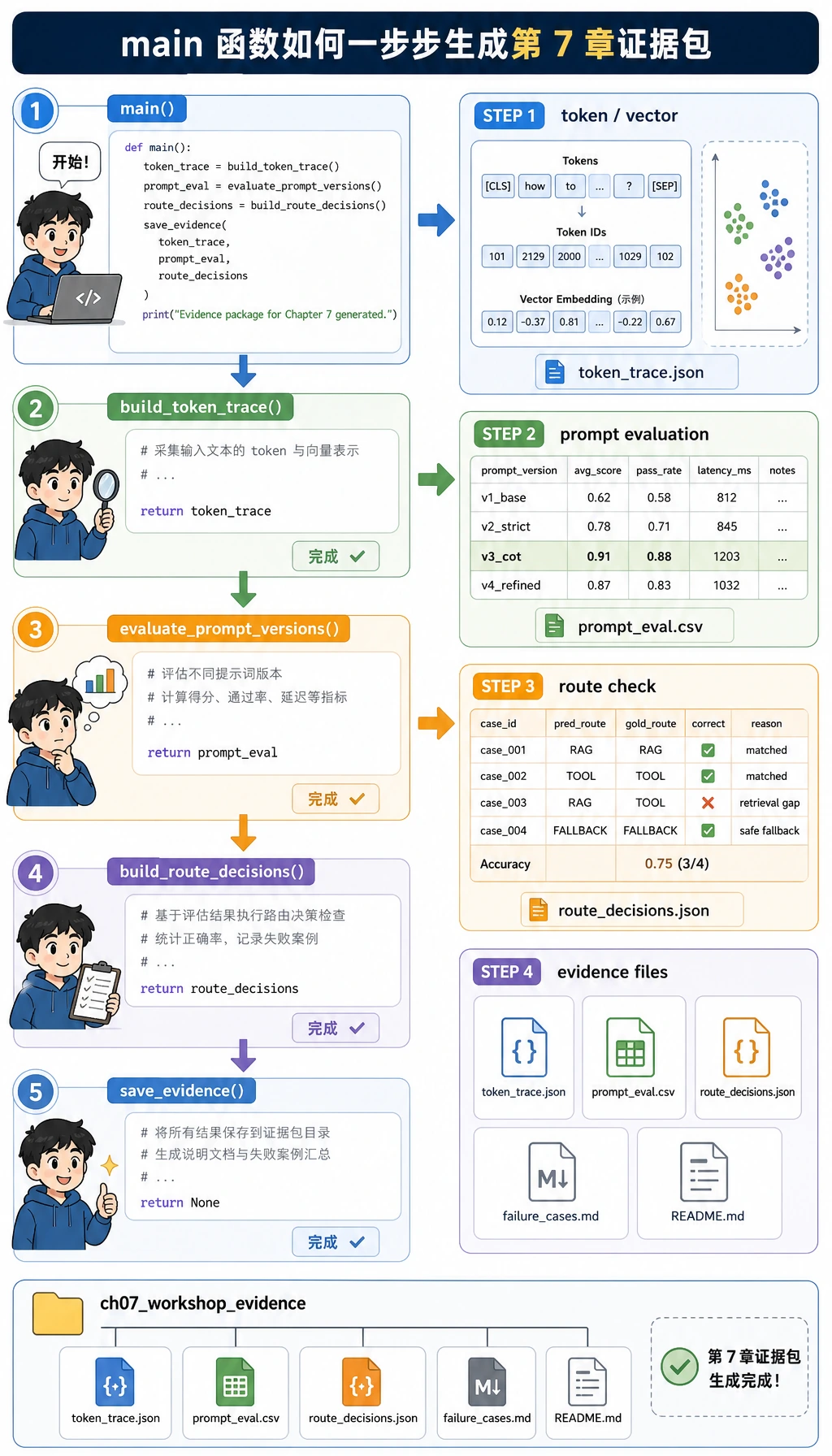
脚本运行时,会先生成痕迹,再评测 Prompt,然后选择方案路线,最后保存文件。
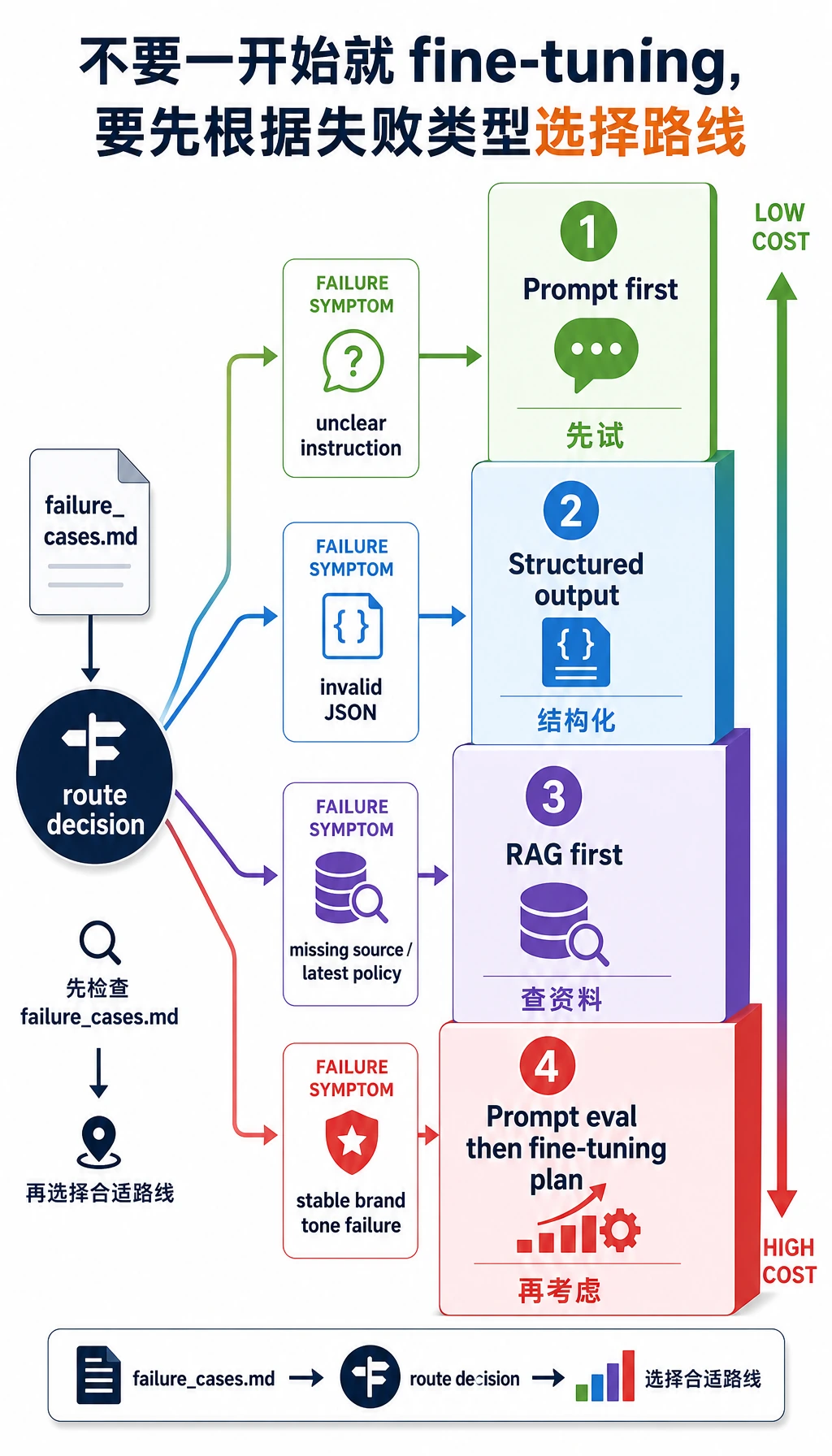
不要一上来就微调。先看失败类型,再选择成本最低且可靠的路线。

最后生成的文件夹也是课程内容的一部分:它让这次运行可以复现、可以复盘、可以展示。
创建项目文件夹
先创建一个本地小文件夹:
mkdir ch07_hands_on
cd ch07_hands_on
然后创建文件 llm_stage_workshop.py。
运行后,脚本还会创建一个名为 ch07_workshop_evidence 的文件夹。如果这个文件夹已经存在,里面的文件会被本次最新运行覆盖。
粘贴并运行工作坊代码
把下面代码保存到 llm_stage_workshop.py:
import csv
import json
import math
import hashlib
from pathlib import Path
SAMPLES = [
{
"id": "case_1",
"user_input": "I understand tokens but not attention. Give me a short study plan.",
"expected_intent": "learning_plan",
},
{
"id": "case_2",
"user_input": "Convert this note into JSON fields: topic=LoRA, risk=overfitting.",
"expected_intent": "structured_output",
},
{
"id": "case_3",
"user_input": "Our assistant keeps using the wrong brand tone. Should we fine-tune?",
"expected_intent": "solution_choice",
},
]
INTENTS = {"learning_plan", "structured_output", "solution_choice"}
EVIDENCE_DIR = Path("ch07_workshop_evidence")
def simple_tokenize(text):
cleaned = "".join(ch.lower() if ch.isalnum() else " " for ch in text)
return [token for token in cleaned.split() if token]
def stable_token_id(token):
digest = hashlib.sha1(token.encode("utf-8")).hexdigest()
return int(digest[:6], 16) % 10000
def tiny_embedding(tokens, width=6):
vector = [0.0] * width
for token in tokens:
vector[stable_token_id(token) % width] += 1.0
norm = math.sqrt(sum(value * value for value in vector)) or 1.0
return [round(value / norm, 3) for value in vector]
def infer_intent(text):
lowered = text.lower()
if "json" in lowered or "field" in lowered or "schema" in lowered:
return "structured_output"
if "fine-tune" in lowered or "brand tone" in lowered or "rag" in lowered:
return "solution_choice"
return "learning_plan"
def build_payload(case, prompt_version):
base = {
"model": "gpt-5.5",
"input": case["user_input"],
"max_output_tokens": 180,
"temperature": 0.2,
"prompt_version": prompt_version,
}
if prompt_version == "v1_goal_only":
base["instructions"] = "Help the learner."
elif prompt_version == "v2_json_contract":
base["instructions"] = (
"Classify the learner request. Return JSON with id, intent, action, "
"confidence, and needs_human_review."
)
else:
base["instructions"] = (
"Classify the learner request. Return JSON only. Allowed intent values: "
"learning_plan, structured_output, solution_choice. confidence must be a "
"number from 0 to 1. needs_human_review must be true only when the request "
"asks for unsafe, legal, medical, or production deployment decisions."
)
return base
def fake_model(payload, case):
intent = infer_intent(payload["input"])
if payload["prompt_version"] == "v1_goal_only":
return "Here is a helpful answer, but it is not machine-readable."
if payload["prompt_version"] == "v2_json_contract" and case["id"] == "case_3":
return json.dumps({"id": case["id"], "intent": "fine_tune", "action": "try fine-tuning"})
action_by_intent = {
"learning_plan": "Start with tokens, then attention, then run the LLM call workbench.",
"structured_output": "Define the JSON schema first, then validate every model output.",
"solution_choice": "Run prompt evaluation first; consider fine-tuning only after stable failures repeat.",
}
return json.dumps(
{
"id": case["id"],
"intent": intent,
"action": action_by_intent[intent],
"confidence": 0.86,
"needs_human_review": False,
},
ensure_ascii=False,
)
def validate_output(raw):
try:
data = json.loads(raw)
except json.JSONDecodeError as exc:
return False, f"invalid_json: {exc.msg}", None
required = ["id", "intent", "action", "confidence", "needs_human_review"]
missing = [field for field in required if field not in data]
if missing:
return False, f"missing_fields: {missing}", data
if data["intent"] not in INTENTS:
return False, f"bad_intent: {data['intent']}", data
if not isinstance(data["confidence"], (int, float)):
return False, "confidence_not_number", data
if not 0 <= data["confidence"] <= 1:
return False, "confidence_out_of_range", data
if not isinstance(data["needs_human_review"], bool):
return False, "needs_human_review_not_boolean", data
return True, "ok", data
def solution_route(text):
lowered = text.lower()
if "latest" in lowered or "source" in lowered or "policy" in lowered:
return "RAG first"
if "brand tone" in lowered or "keeps using" in lowered:
return "Prompt eval first, then fine-tuning plan"
if "json" in lowered or "field" in lowered:
return "Structured output"
return "Prompt first"
def build_token_trace():
rows = []
for case in SAMPLES:
tokens = simple_tokenize(case["user_input"])
rows.append(
{
"case_id": case["id"],
"tokens": tokens,
"token_ids": [stable_token_id(token) for token in tokens],
"tiny_embedding": tiny_embedding(tokens),
}
)
return rows
def evaluate_prompt_versions():
rows = []
for version in ["v1_goal_only", "v2_json_contract", "v3_json_with_boundary"]:
for case in SAMPLES:
payload = build_payload(case, version)
raw = fake_model(payload, case)
ok, reason, data = validate_output(raw)
correct_intent = ok and data["intent"] == case["expected_intent"]
if ok and not correct_intent:
reason = f"wrong_intent: {data['intent']} != {case['expected_intent']}"
rows.append(
{
"prompt_version": version,
"case_id": case["id"],
"passed": correct_intent,
"reason": "ok" if correct_intent else reason,
"raw_output": raw,
}
)
return rows
def build_route_decisions():
return [
{
"case_id": case["id"],
"user_input": case["user_input"],
"first_route": solution_route(case["user_input"]),
}
for case in SAMPLES
]
def save_evidence(token_rows, eval_rows, route_rows):
EVIDENCE_DIR.mkdir(exist_ok=True)
token_path = EVIDENCE_DIR / "token_trace.json"
eval_path = EVIDENCE_DIR / "prompt_eval.csv"
route_path = EVIDENCE_DIR / "route_decisions.json"
failure_path = EVIDENCE_DIR / "failure_cases.md"
readme_path = EVIDENCE_DIR / "README.md"
token_path.write_text(json.dumps(token_rows, indent=2, ensure_ascii=False), encoding="utf-8")
route_path.write_text(json.dumps(route_rows, indent=2, ensure_ascii=False), encoding="utf-8")
with eval_path.open("w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["prompt_version", "case_id", "passed", "reason", "raw_output"])
writer.writeheader()
writer.writerows(eval_rows)
failures = [row for row in eval_rows if not row["passed"]]
failure_lines = ["# Failure Cases", ""]
for row in failures:
failure_lines.append(f"- {row['prompt_version']} / {row['case_id']}: {row['reason']}")
failure_path.write_text("\n".join(failure_lines) + "\n", encoding="utf-8")
passed_v3 = sum(row["passed"] for row in eval_rows if row["prompt_version"] == "v3_json_with_boundary")
readme_path.write_text(
"# Chapter 7 LLM Workshop Evidence\n\n"
"Run command: `python llm_stage_workshop.py`\n\n"
f"Best prompt version: v3_json_with_boundary ({passed_v3}/{len(SAMPLES)} passed)\n\n"
"Review `failure_cases.md` before deciding whether to change Prompt, add RAG, or plan fine-tuning.\n",
encoding="utf-8",
)
return [token_path, eval_path, route_path, failure_path, readme_path]
def main():
token_rows = build_token_trace()
print("STEP 1: Token and vector trace")
for row in token_rows:
print(
f"{row['case_id']} tokens={row['tokens'][:8]} "
f"ids={row['token_ids'][:8]} vector={row['tiny_embedding']}"
)
eval_rows = evaluate_prompt_versions()
print("\nSTEP 2: Prompt version evaluation")
for version in ["v1_goal_only", "v2_json_contract", "v3_json_with_boundary"]:
version_rows = [row for row in eval_rows if row["prompt_version"] == version]
passed = sum(row["passed"] for row in version_rows)
failures = [f"{row['case_id']}:{row['reason']}" for row in version_rows if not row["passed"]]
print(f"{version}: {passed}/{len(version_rows)} passed; failures={failures or ['none']}")
route_rows = build_route_decisions()
print("\nSTEP 3: Solution route check")
for row in route_rows:
print(f"{row['case_id']} -> {row['first_route']}")
saved_files = save_evidence(token_rows, eval_rows, route_rows)
print("\nSTEP 4: Evidence files")
for path in saved_files:
print(path.as_posix())
if __name__ == "__main__":
main()
运行:
python llm_stage_workshop.py
预期输出
你应该看到接近下面的输出:
STEP 1: Token and vector trace
case_1 tokens=['i', 'understand', 'tokens', 'but', 'not', 'attention', 'give', 'me'] ids=[3860, 5684, 9523, 2631, 3109, 1613, 4738, 9496] vector=[0.0, 0.324, 0.324, 0.162, 0.811, 0.324]
case_2 tokens=['convert', 'this', 'note', 'into', 'json', 'fields', 'topic', 'lora'] ids=[9914, 5551, 4760, 3544, 3358, 1778, 2081, 3008] vector=[0.0, 0.189, 0.756, 0.189, 0.567, 0.189]
case_3 tokens=['our', 'assistant', 'keeps', 'using', 'the', 'wrong', 'brand', 'tone'] ids=[8696, 9265, 8706, 6757, 7679, 4122, 2342, 7190] vector=[0.343, 0.686, 0.514, 0.0, 0.171, 0.343]
STEP 2: Prompt version evaluation
v1_goal_only: 0/3 passed; failures=['case_1:invalid_json: Expecting value', 'case_2:invalid_json: Expecting value', 'case_3:invalid_json: Expecting value']
v2_json_contract: 2/3 passed; failures=["case_3:missing_fields: ['confidence', 'needs_human_review']"]
v3_json_with_boundary: 3/3 passed; failures=['none']
STEP 3: Solution route check
case_1 -> Prompt first
case_2 -> Structured output
case_3 -> Prompt eval first, then fine-tuning plan
STEP 4: Evidence files
ch07_workshop_evidence/token_trace.json
ch07_workshop_evidence/prompt_eval.csv
ch07_workshop_evidence/route_decisions.json
ch07_workshop_evidence/failure_cases.md
ch07_workshop_evidence/README.md
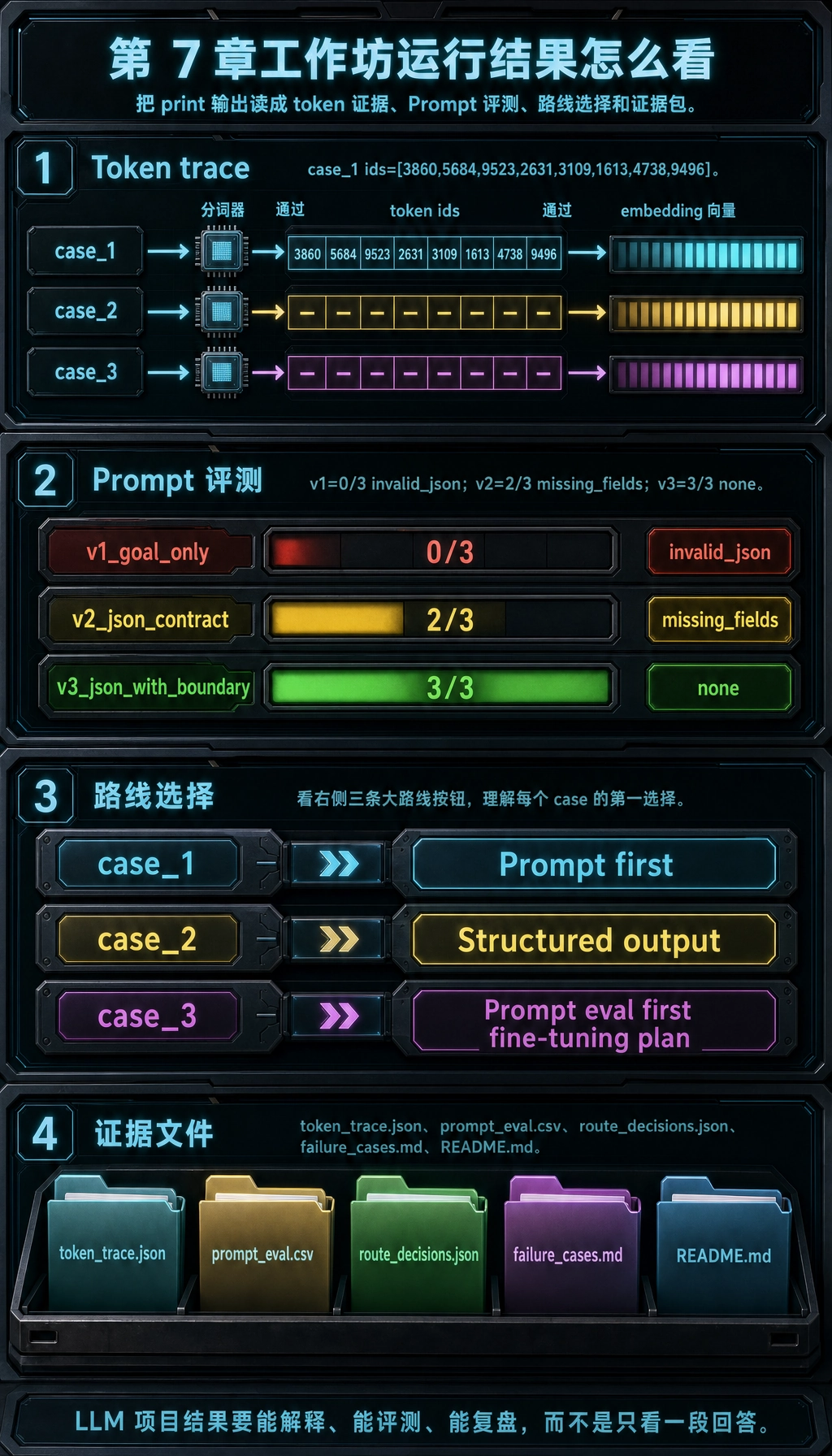
每一步在说明什么
| 输出区域 | 观察重点 | 对应章节概念 |
|---|---|---|
tokens 和 ids | 文本被拆成更小单位,并映射成数字 | Tokenizer 与 token ids |
vector | 小型教学向量说明文本可以变成数值特征 | Embedding 直觉 |
v1_goal_only | 回答可能有帮助,但程序无法解析 | 模糊 Prompt 与不稳定接口 |
v2_json_contract | JSON 有帮助,但缺字段和错误枚举仍会破坏流程 | 结构化输出校验 |
v3_json_with_boundary | 加上允许值、类型和审核规则后,结果才可测试 | Prompt 迭代与 schema 设计 |
solution_route | 不同问题需要不同第一步 | Prompt、RAG、结构化输出、微调边界 |
ch07_workshop_evidence | 运行结果被保存成可以检查、比较和分享的文件 | 可复现项目证据 |
新人常见问题排查
| 现象 | 可能原因 | 处理方式 |
|---|---|---|
python: command not found | 你的系统使用 python3 而不是 python | 运行 python3 llm_stage_workshop.py |
| 输出空格略有不同 | Python 打印列表时可能有细微格式差异 | 重点看通过数量和失败原因 |
出现 invalid_json | 模拟模型返回了自然语言,不是 JSON | 这是 v1_goal_only 的故意设计 |
出现 missing_fields | 输出合同不够严格 | 对比 v2_json_contract 和 v3_json_with_boundary |
| 没有生成证据文件 | 你可能在只读文件夹里运行,或在 STEP 4 前中断了脚本 | 换到普通项目文件夹运行,并确认 STEP 4 打印了文件路径 |
| 想调用真实模型 | 本工作坊刻意离线运行 | 先完成本页,再看 LLM 调用工作台里的可选 API 部分 |
可选:后续替换为真实模型
离线流程理解清楚后,可以把 fake_model() 换成真实模型调用。当前做 OpenAI 文本生成时,优先使用 Responses API 和结构化输出,不要直接照搬旧的 chat-completion 示例。
本工作坊的载荷示例使用 gpt-5.5,因为当前 OpenAI 模型文档把 GPT-5.5 列为最新前沿模型。生产代码里请让 OPENAI_MODEL 可配置,并在发布前检查官方 OpenAI Models、Responses API 和 Structured Outputs 文档。
一个真实的结构化输出调用可以写成这样:
import os
from pydantic import BaseModel
from openai import OpenAI
class RouteResult(BaseModel):
intent: str
action: str
confidence: float
needs_human_review: bool
client = OpenAI()
response = client.responses.parse(
model=os.getenv("OPENAI_MODEL", "gpt-5.5"),
input=[
{
"role": "system",
"content": (
"Classify the learner request. Return a practical next action. "
"Use needs_human_review only for unsafe, legal, medical, or production decisions."
),
},
{
"role": "user",
"content": "Our assistant keeps using the wrong brand tone. Should we fine-tune?",
},
],
text_format=RouteResult,
)
print(response.output_parsed.model_dump())
安装依赖并设置 key 后再运行真实版本:
pip install --upgrade openai pydantic
export OPENAI_API_KEY="your_api_key_here"
python real_route_call.py
阅读证据包
现在脚本会自动保存最小作品集版本。运行后打开这个文件夹:
ls ch07_workshop_evidence
你应该会看到:
| 文件 | 内容 |
|---|---|
README.md | 运行命令、最佳 Prompt 版本和下一步复盘动作 |
token_trace.json | 每个样本的 tokens、token ids 和小型向量 |
prompt_eval.csv | 每个 Prompt 版本和测试样本一行,包含通过/失败原因 |
route_decisions.json | 每个样本应该先走哪条方案路线 |
failure_cases.md | 改 Prompt、加 RAG 或规划微调前应该先看的失败证据 |
先打开 failure_cases.md。它会告诉你为什么 v1 不能被程序读取,为什么 v2 仍然不够严格。这就是第 7 章要训练的习惯:不要凭一个看起来不错的答案做决定,而要根据可重复的失败和保存下来的证据做决定。
退出检查清单
- 我能在本地跑通这个工作坊。
- 我能解释为什么自然语言输出不足以支撑产品流程。
- 我能解释校验为什么能抓到无效 JSON 和缺字段。
- 我能用固定测试样本比较 Prompt 版本。
- 我能解释为什么微调通常应该放在 Prompt 评测和稳定失败证据之后。
如果五项都能勾上,你就已经把第 7 章从概念章节变成了一条可运行的工程闭环。