7.6.1 微调路线图:数据、LoRA、评估
微调通过样本训练来改变模型行为。它适合稳定任务模式、重复格式、领域表达风格或行为习惯。它通常不是补充私有知识的第一选择,那类问题更常见的路线是 RAG。
先看决策闭环
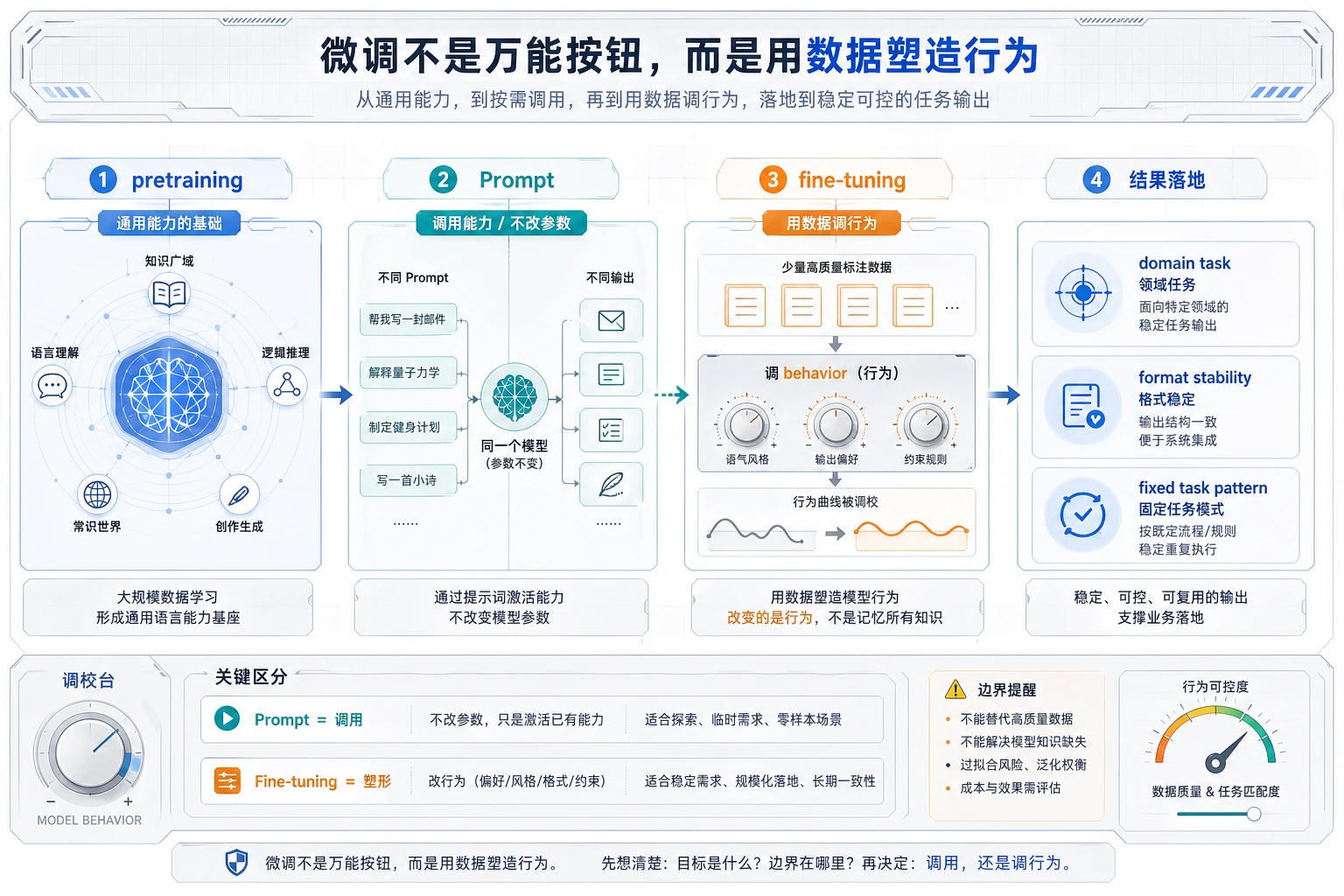
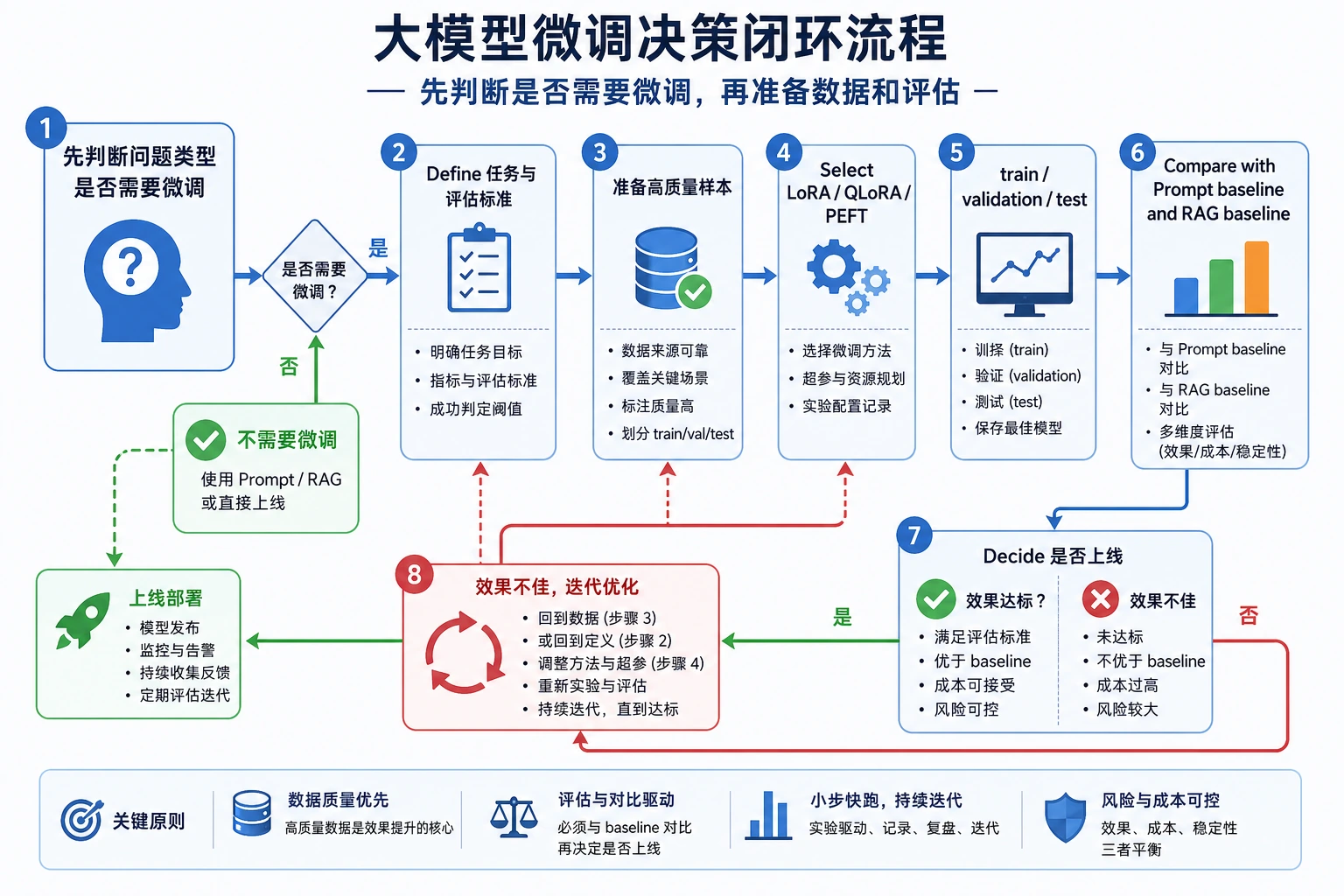
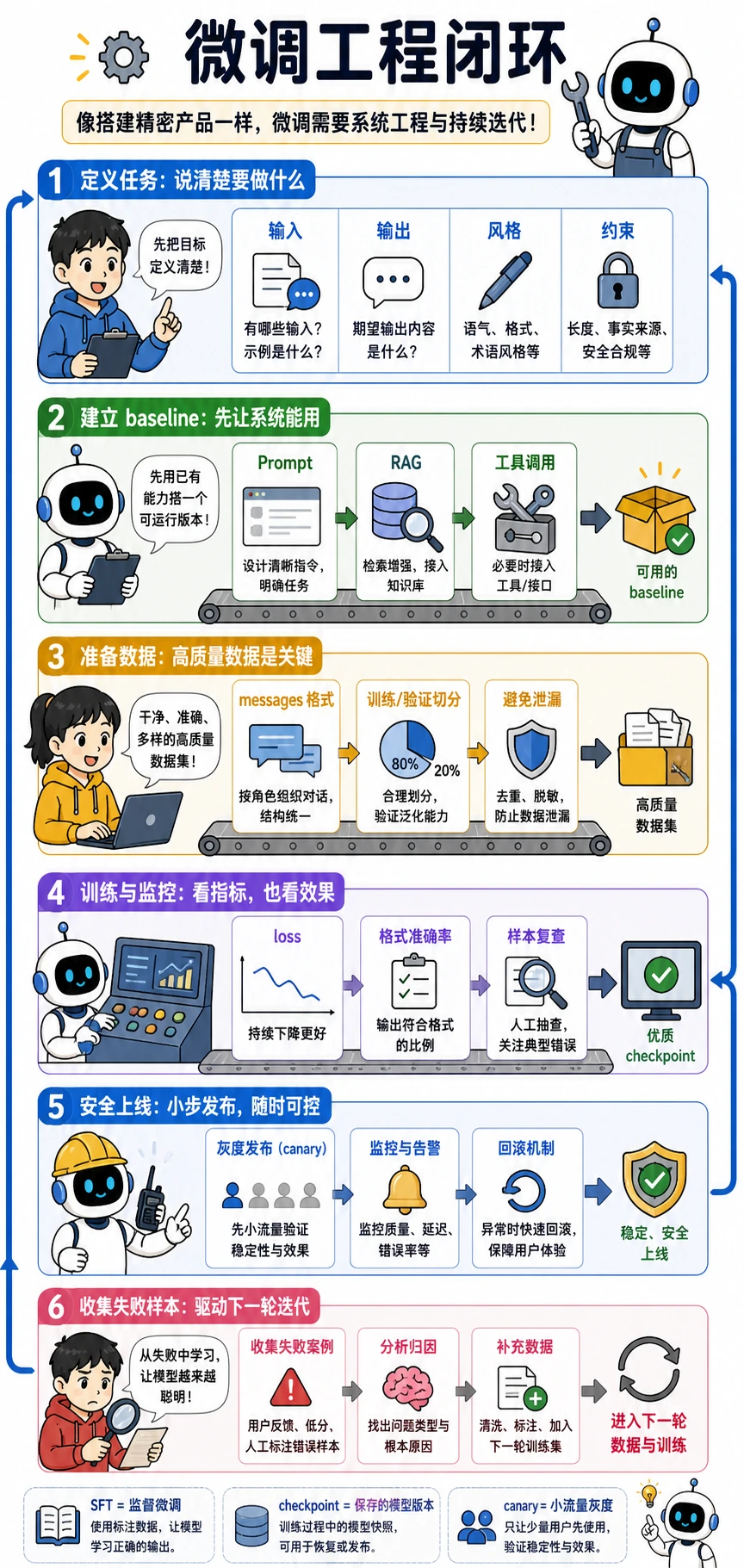
关键术语:LoRA 指低秩适配器,QLoRA 指量化版 LoRA,PEFT 指参数高效微调。它们通过训练少量新增参数,而不是更新全部模型权重,来降低成本。
跑一个微调路线检查
开始训练前先跑这个检查。没有 Prompt 基线、验证集和失败记录的微调,很难判断到底有没有变好。
case = {
"private_facts": False,
"format_drift": True,
"stable_task": True,
"labeled_examples": 120,
}
if case["private_facts"]:
route = "RAG first"
elif case["format_drift"] and case["stable_task"] and case["labeled_examples"] >= 50:
route = "fine-tuning candidate"
else:
route = "prompt baseline first"
print("route:", route)
print("minimum_before_training:", ["prompt baseline", "validation set", "failure log"])
预期输出:
route: fine-tuning candidate
minimum_before_training: ['prompt baseline', 'validation set', 'failure log']
每次只改一个值再重新运行。例如把 private_facts 改成 True,路线就应该先转向 RAG。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 微调概览 | 写清什么时候用 Prompt、RAG 或微调 |
| 2 | LoRA / QLoRA | 解释训练哪些参数,以及为什么成本下降 |
| 3 | 其他 PEFT 方法 | 知道全量微调不是唯一选择 |
| 4 | 微调实战 | 准备训练/验证样本和一条运行命令 |
| 5 | 数据标注 | 检查格式、重复、泄漏和边界样本 |
通过标准
如果你能说明为什么微调值得尝试,展示它击败的基线,并保留没有参与训练的验证集,就通过了本章。
本章出口小项目是一份小型指令微调计划:选择一个固定任务,准备几十到几百条样本,定义 Prompt 基线,并在 LoRA/QLoRA 运行后比较格式稳定性或准确率。