7.2.5 実践:LLM 呼び出しワークベンチ
このレッスンでは、前の概念を実際に追えるワークフローに変えます。どのモデルが一番強いかを比較する前に、まず 1 回の LLM 呼び出しで何が起きているのかを理解しましょう。ユーザー課題、Token 予算、リクエスト payload、モデル出力、検証、再試行までを順に見ます。
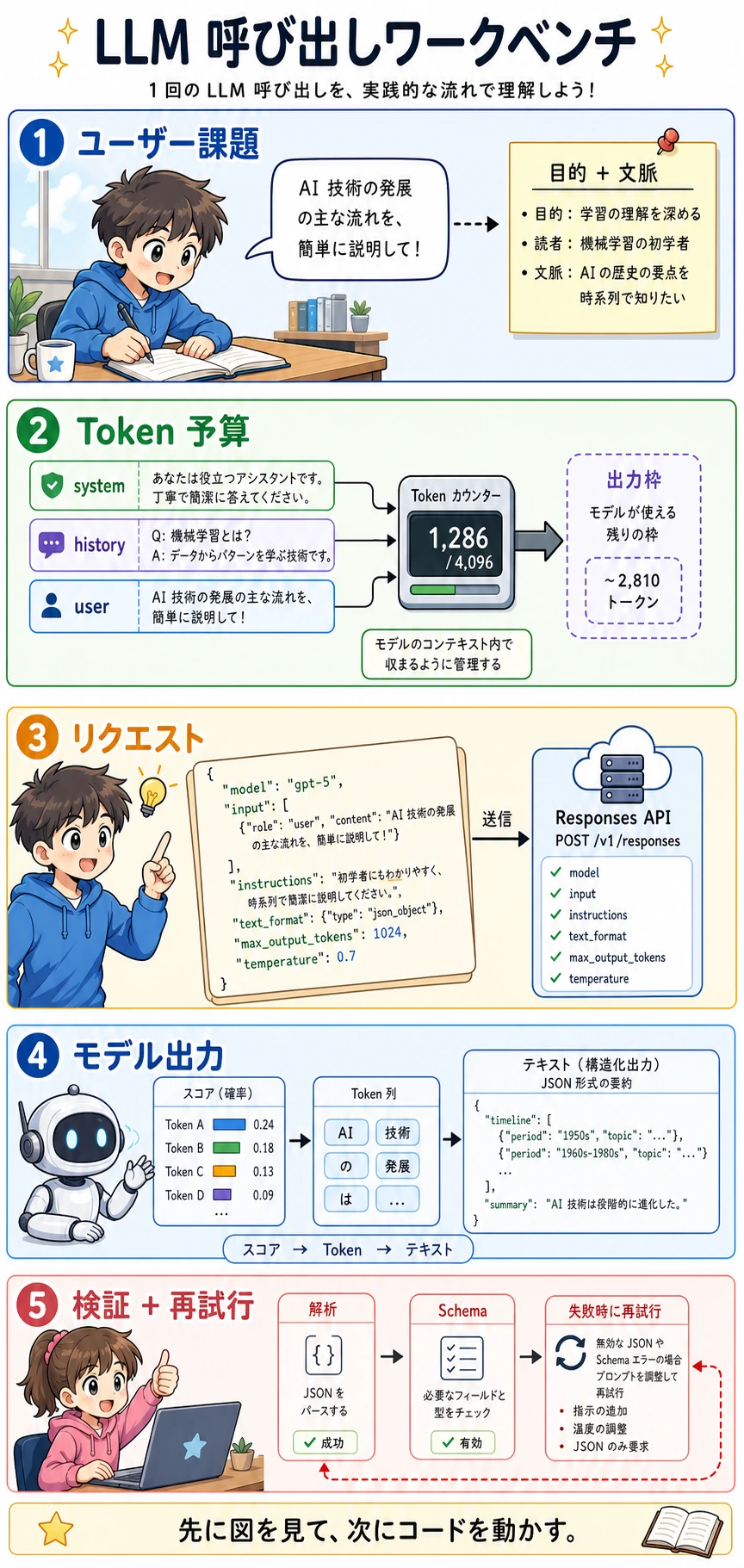
まず図を見て、次にコードを動かし、最後に用語や式を確認します。1 回のリクエストを入力から検証済み出力まで追えるようになると、LLM エンジニアリングはかなり見通しやすくなります。
この実践で学ぶこと
このレッスンの後で、次のことを説明できるようになるのが目標です。
- API リクエストがモデルに何を送るのか。
- コンテキストウィンドウが実質的には Token 予算である理由。
- 構造化出力に parsing と validation が必要な理由。
- 再試行はただ同じ質問を繰り返すのではなく、失敗原因を修正すべき理由。
- きれいな回答を表示できても、それだけでは信頼できるプロダクト機能ではない理由。
コードの前に理解したい用語
| 用語 | やさしい説明 | このレッスンでの役割 |
|---|---|---|
| API | Application Programming Interface。ソフトウェアが別のサービスを呼び出すための標準的な窓口 | プログラムがモデルサービスへリクエストを送り、レスポンスを受け取る |
| SDK | Software Development Kit。API 呼び出しを扱いやすくするライブラリ | 任意の実 API 例では公式 Python SDK を使う |
| Endpoint | リクエストを受け取る URL パス | 現代的な OpenAI テキスト API の endpoint は /v1/responses |
| Payload | API に送る JSON 本文 | model、instructions、input、出力設定、制約を含む |
| Token 予算 | コンテキストウィンドウ内で使える容量 | system ルール、履歴、ユーザー入力、検索コンテキスト、出力枠が共有する |
| JSON | プログラムが解析しやすい構造化データ形式 | 自由な段落ではなく、timeline オブジェクトを返す |
| Schema | JSON の期待される形 | 必須フィールドと型をプログラムに伝える |
| Validation | 出力をプログラムで検査すること | 欠けたフィールド、型の誤り、不正な JSON を検出する |
| Retry | 制御された失敗の後で再試行すること | 価値のある retry は、Schema 指示を強めるなど原因を直す |
| Latency | リクエストにかかる時間 | 長いコンテキストや長い出力は、通常 latency を増やす |
まずオフラインのワークベンチを動かす
最初の例は Python 標準ライブラリだけを使います。実際のモデルは呼びません。これは意図的です。API key、ネットワーク、有料モデルがなくても、先にエンジニアリングの流れを理解できます。
llm_call_workbench.py として保存し、次を実行します。
python llm_call_workbench.py
import json
CONTEXT_LIMIT = 4096
def rough_token_count(text):
# A real tokenizer is more complex. This simple counter is enough for budget intuition.
return max(1, len(text.split()))
def build_payload(user_task, max_output_tokens=600, temperature=0.3):
instructions = (
"You are a teaching assistant. Return valid JSON only. "
"Each timeline era must include period, key_event, and summary."
)
input_text = (
"Create a beginner-friendly timeline of AI development with four eras. "
f"User task: {user_task}"
)
used_tokens = rough_token_count(instructions) + rough_token_count(input_text)
remaining = CONTEXT_LIMIT - used_tokens - max_output_tokens
payload = {
"model": "gpt-5.5",
"instructions": instructions,
"input": input_text,
"text": {"format": {"type": "json_object"}},
"max_output_tokens": max_output_tokens,
"temperature": temperature,
}
return payload, used_tokens, remaining
def fake_model_response(attempt):
if attempt == 1:
# The first response is intentionally broken: the first era misses "summary".
return """
{
"timeline": [
{"period": "1950s", "key_event": "Turing Test"},
{"period": "2017", "key_event": "Transformer", "summary": "Self-attention became the backbone of LLMs."}
]
}
"""
return """
{
"timeline": [
{"period": "1936-1950", "key_event": "Turing machine and Turing Test", "summary": "AI became a testable question."},
{"period": "1956-1980s", "key_event": "Symbolic AI and expert systems", "summary": "Rules worked in narrow domains but did not scale well."},
{"period": "1990s-2012", "key_event": "Statistical learning and deep learning", "summary": "Data and neural networks replaced many hand-written rules."},
{"period": "2017-now", "key_event": "Transformer and LLMs", "summary": "Self-attention, scale, and alignment made general assistants practical."}
]
}
"""
def validate_timeline(text):
try:
data = json.loads(text)
except json.JSONDecodeError:
return False, "invalid_json", None
if "timeline" not in data or not isinstance(data["timeline"], list):
return False, "missing_timeline_list", None
required_fields = {"period", "key_event", "summary"}
for index, era in enumerate(data["timeline"]):
if not isinstance(era, dict):
return False, f"era_{index}_not_object", None
missing = required_fields - set(era)
if missing:
return False, f"era_{index}_missing_{sorted(missing)}", None
return True, "valid", data
def run_workbench(user_task):
payload, used_tokens, remaining = build_payload(user_task)
print("used input tokens estimate:", used_tokens)
print("remaining output room :", remaining)
print("request model :", payload["model"])
for attempt in [1, 2]:
print("\nattempt:", attempt)
raw_output = fake_model_response(attempt)
ok, reason, parsed = validate_timeline(raw_output)
print("validation:", reason)
if ok:
print("first era:", parsed["timeline"][0])
return parsed
payload["instructions"] += " Do not omit any required field."
payload["temperature"] = 0.1
print("retry fix: strengthen schema instruction and lower temperature")
raise RuntimeError("Could not get a valid timeline after retries.")
run_workbench("Explain AI history with simple language.")
想定される出力の形は次のようになります。
used input tokens estimate: 36
remaining output room : 3460
request model : gpt-5.5
attempt: 1
validation: era_0_missing_['summary']
retry fix: strengthen schema instruction and lower temperature
attempt: 2
validation: valid
first era: {'period': '1936-1950', ...}
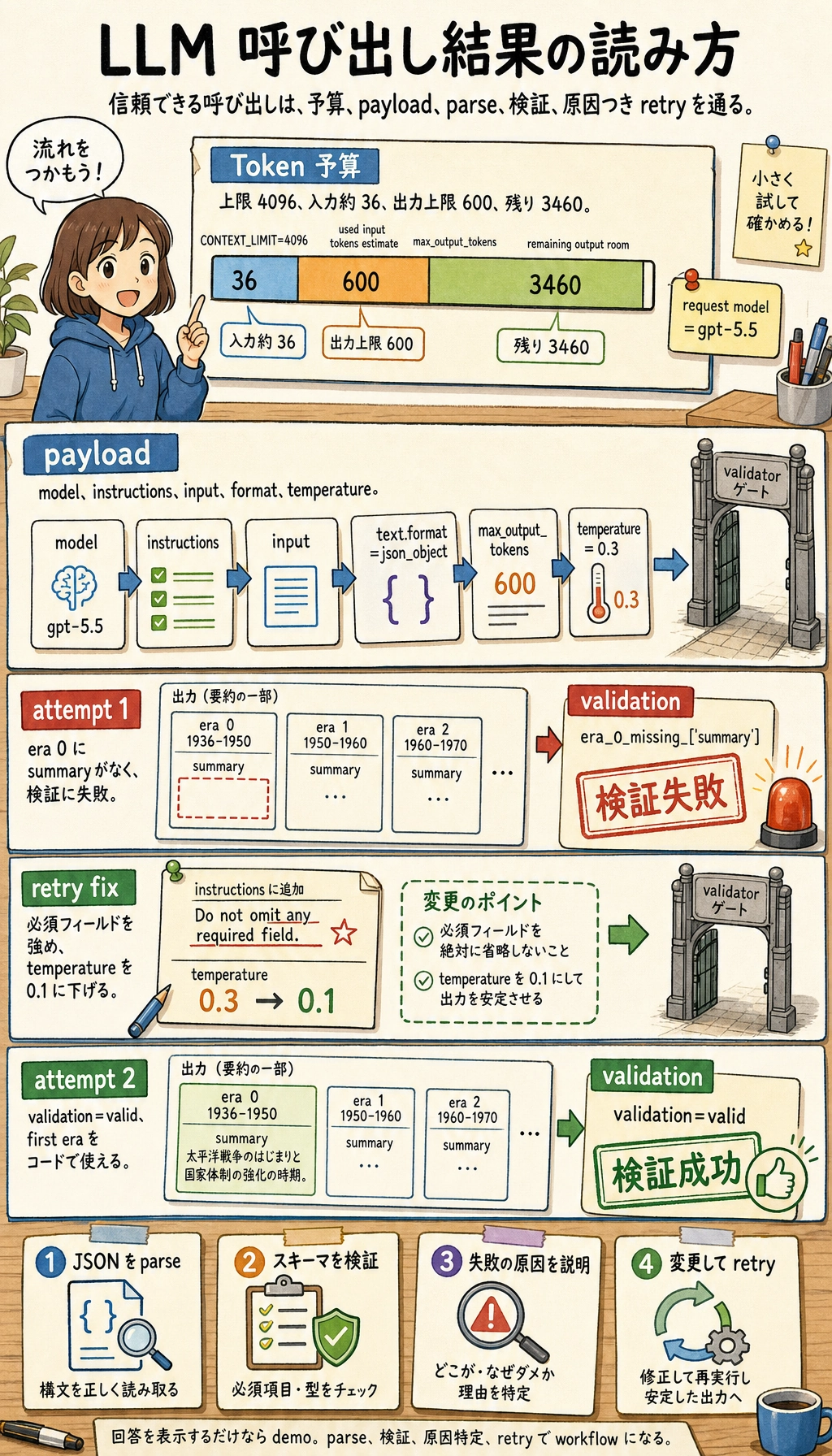
このコードが本当に示していること
リクエストは Prompt だけではない
Payload には model、instructions、input、text.format、max_output_tokens、temperature が含まれます。初心者は Prompt の文だけを直しがちですが、実際の LLM エンジニアリングでは出力長、形式、ランダム性、検証方法も制御します。
Token 予算はプロダクト上の制約
モデルは無限の文章を見られるわけではありません。system 指示、ユーザーメッセージ、会話履歴、検索資料、出力枠は同じコンテキストウィンドウを共有します。背景情報を詰め込みすぎると、回答するための空きが足りなくなることがあります。
Validation がデモをワークフローに変える
レスポンスを表示するだけならデモです。ワークフローでは、出力を parse し、必須フィールドを確認し、失敗タイプを検出し、再試行するのか、ユーザーに確認するのか、人にエスカレーションするのかを決めます。
Retry は原因を直すべき
同じリクエストを何度も投げるだけでは時間とコストを浪費します。よりよい retry は、具体的な問題を直します。
| 失敗 | よりよい retry |
|---|---|
| JSON が不正 | JSON だけを要求し、余分な説明を減らす。可能なら構造化出力を使う |
| フィールド不足 | 必須フィールドを再度明示し、省略不可と伝える |
| 出力が長すぎる | max_output_tokens を下げる、または短い形式を要求する |
| 分類が不安定 | temperature を下げ、例を追加する |
| 知識が不足 | 検索コンテキストを追加するか、後の RAG に任せる |
任意:実際の Responses API 呼び出し
API key がある場合は、公式 OpenAI Python SDK と現代的な Responses API で同じ考え方を試せます。まずオフラインのワークベンチを理解してから実行しましょう。
python -m pip install --upgrade openai pydantic
export OPENAI_API_KEY="your_api_key_here"
python real_responses_call.py
import os
from pydantic import BaseModel
from openai import OpenAI
class Era(BaseModel):
period: str
key_event: str
summary: str
class Timeline(BaseModel):
timeline: list[Era]
client = OpenAI()
response = client.responses.parse(
model=os.getenv("OPENAI_MODEL", "gpt-5.5"),
input=[
{
"role": "system",
"content": (
"You are a teaching assistant. Return a concise beginner-friendly "
"AI history timeline."
),
},
{
"role": "user",
"content": "Create a four-era AI development timeline for beginners.",
},
],
text_format=Timeline,
)
print(response.output_parsed.model_dump())
新しいテキスト生成アプリでは、古い chat-completion 例から始めるよりも Responses API を優先します。重要なエンジニアリングの考え方はオフラインのワークベンチと同じです。リクエストを作り、出力を制御し、結果を parse し、プログラムが使えることを確認します。
アカウントやデプロイで別の承認済みモデルを使う場合は OPENAI_MODEL を設定してください。モデル名を設定可能にしておくことで、教材コードを固定の既定値に縛られにくくします。
練習方法
- オフライン課題を「AI history timeline」から「course study plan」に変え、必須 Schema フィールドを更新する。
- 最初の fake response を不正 JSON にして、validator が検出できるか確認する。
- 各 era に
source_refsフィールドを追加し、validation でも必須にする。 max_output_tokensを下げ、それがどんなプロダクト上の問題を模擬しているか説明する。- 1 ページのメモを書く。どこが Prompt 設計で、どこが API payload 設計で、どこがアプリケーション信頼性なのかを分ける。
まとめ
実際の LLM 呼び出しは、「質問を送って回答を受け取る」だけではありません。小さなエンジニアリングループです。
課題を定義し、Token 予算を管理し、明確な Payload を送り、出力を parse し、Schema を検証し、失敗理由がわかるときだけ retry する。
このループに慣れると、Prompt、構造化出力、RAG、tool calling、Agent ワークフローは、ばらばらの流行語ではなく、同じ基礎能力の拡張として見えるようになります。