7.2.3 大規模モデルの核心概念
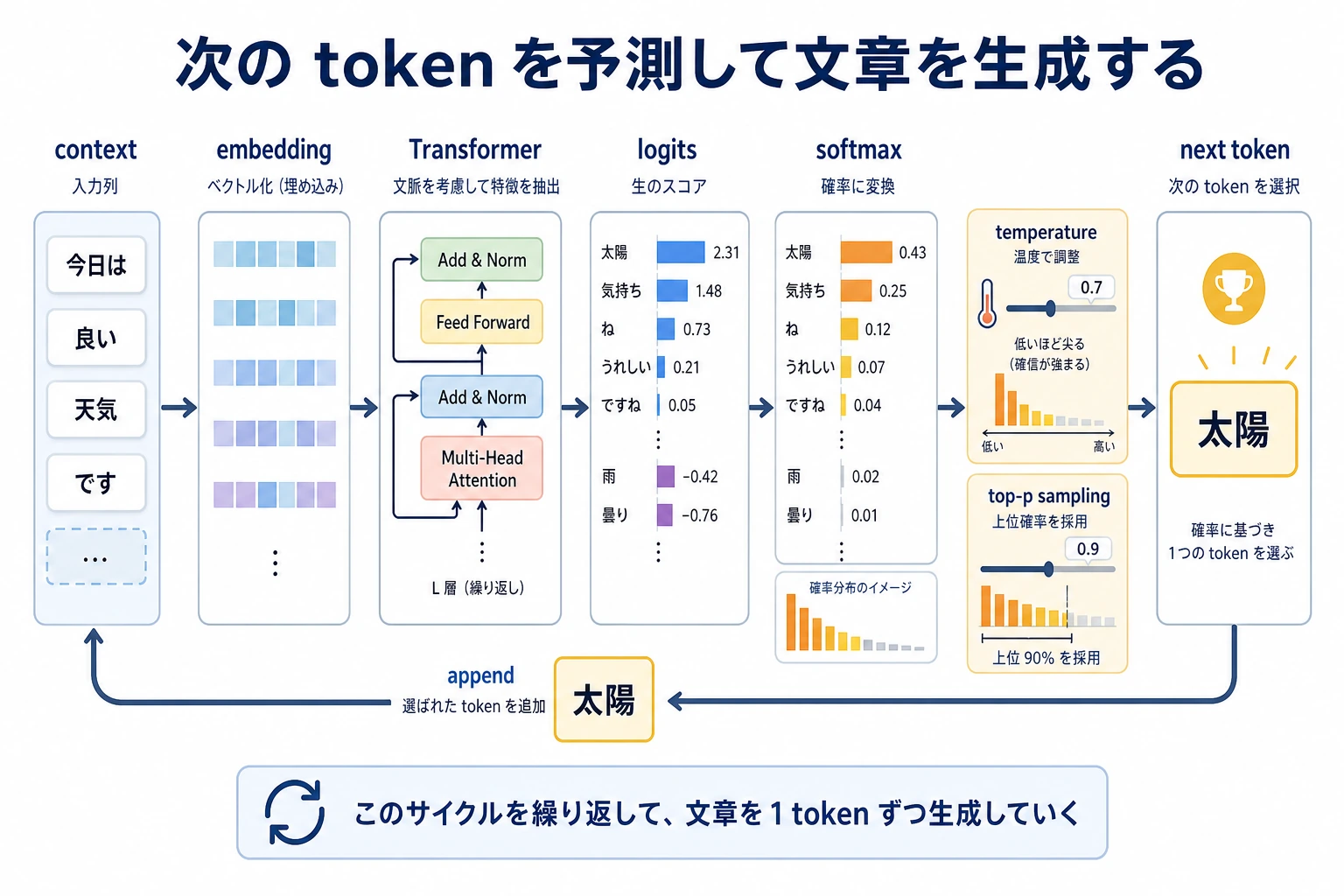
中心ループ
大規模言語モデルは、答え全体を一度に書くのではありません。次のループを繰り返します。
context -> logits -> probabilities -> choose next token -> append token -> repeat
概念マップ
| 概念 | 実務での意味 |
|---|---|
| token | モデルが読む・書く基本単位 |
| context window | system prompt、履歴、証拠、質問、出力が共有する token 予算 |
| embedding | token の vector 表現 |
| attention | 関連度に基づいて token 情報を混ぜる仕組み |
| logits | probability になる前の raw scores |
| temperature | probability distribution を鋭く、または平らにするノブ |
| pretraining | 大規模テキストから得た広い capability |
| instruction tuning / alignment | capability を assistant-like behavior に近づける |
実験 1:次の token を予測する
import numpy as np
context = "Beijing is China's"
candidates = ["capital", "city", "university"]
logits = np.array([4.0, 2.0, 0.5])
def softmax(x):
e = np.exp(x - x.max())
return e / e.sum()
probs = softmax(logits)
best = candidates[np.argmax(probs)]
print("Context:", context)
for token, prob in zip(candidates, probs):
print(f"Candidate token={token}, probability={prob:.3f}")
print("Most likely next token:", best)
期待される出力:
Context: Beijing is China's
Candidate token=capital, probability=0.858
Candidate token=city, probability=0.116
Candidate token=university, probability=0.026
Most likely next token: capital
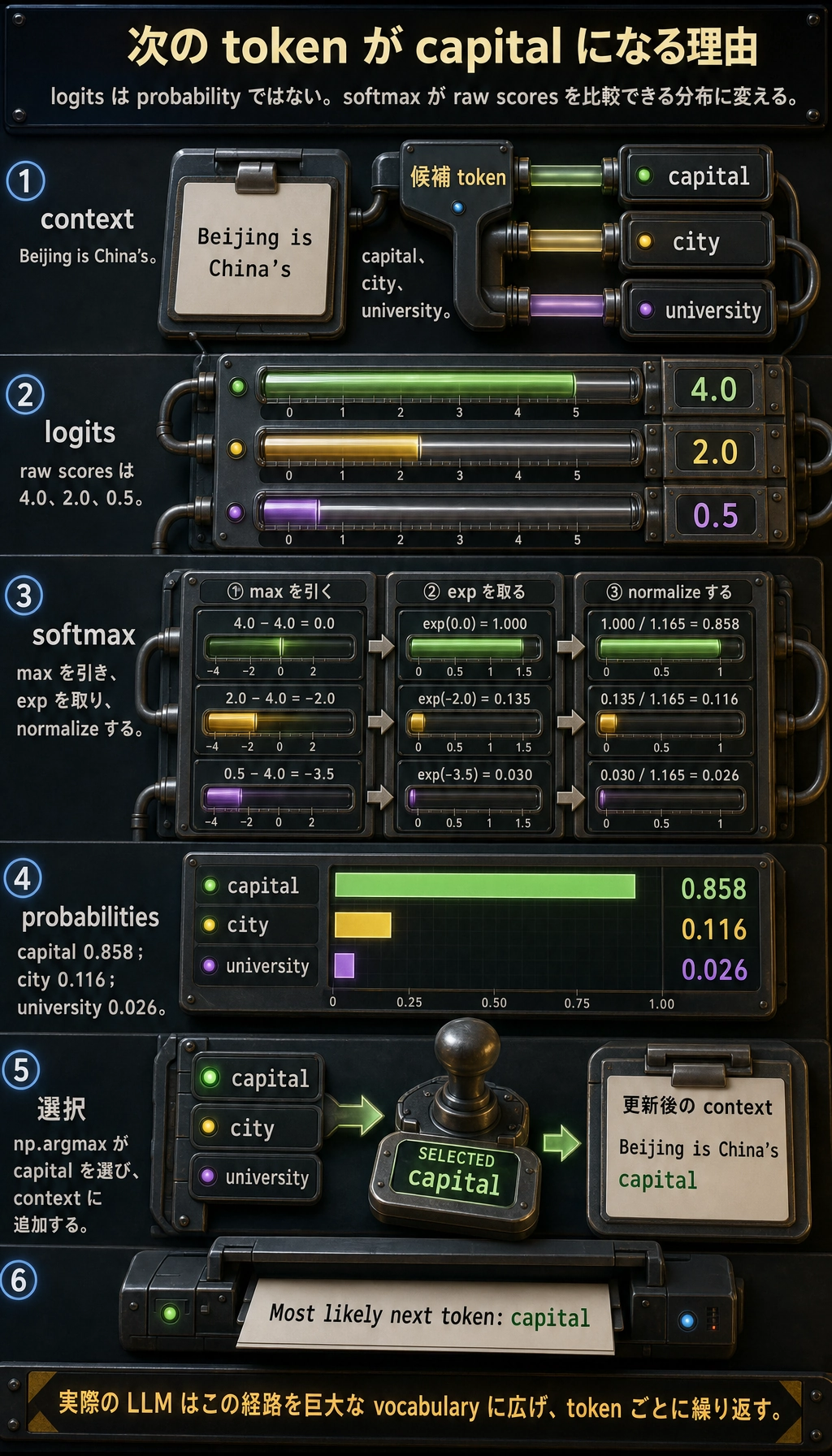
実際のモデルは非常に大きな vocabulary 上でこれを行います。原理は同じです。scores を出し、probabilities に変換し、次の token を選びます。
Context Window は予算

Context window は無限の記憶ではなく、固定された token budget です。
system prompt + chat history + retrieved evidence + user question + answer space <= context window
実務上の意味:
- 長い文書は選択、圧縮、または chunking が必要。
- RAG は evidence と final answer の両方にスペースを残す。
- chat history は役に立たなくなったら要約または削る。
- 大きな context は、正しい情報を入れたときだけ役に立つ。
実験 2:Temperature が sampling を変える
import numpy as np
tokens = ["Beijing", "Shanghai", "Guangzhou"]
logits = np.array([3.0, 1.5, 0.5])
def softmax_with_temperature(logits, temperature=1.0):
scaled = logits / temperature
exp_values = np.exp(scaled - scaled.max())
return exp_values / exp_values.sum()
for temp in [0.5, 1.0, 2.0]:
probs = softmax_with_temperature(logits, temperature=temp)
print(f"temperature={temp}")
for token, prob in zip(tokens, probs):
print(f" {token}: {prob:.4f}")
期待される出力:
temperature=0.5
Beijing: 0.9465
Shanghai: 0.0471
Guangzhou: 0.0064
temperature=1.0
Beijing: 0.7662
Shanghai: 0.1710
Guangzhou: 0.0629
temperature=2.0
Beijing: 0.5685
Shanghai: 0.2686
Guangzhou: 0.1629
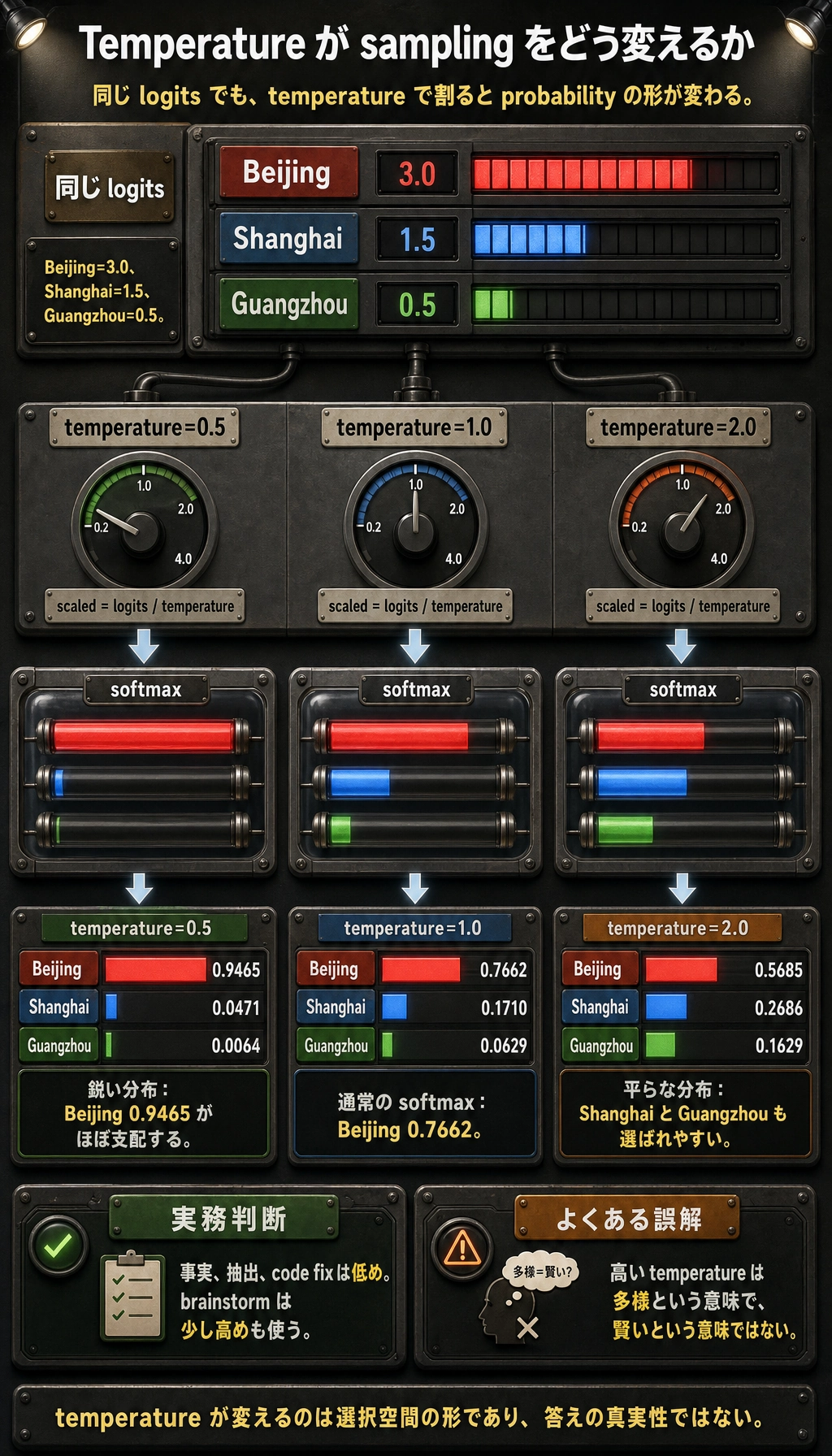
読み方:
- temperature が低いほど top choice が支配的になる。
- temperature が高いほど lower-ranked tokens も選ばれやすい。
- temperature が高いことは、賢いことではなく、多様なことを意味する。
事実回答、抽出、コード修正では低めから始めます。ブレスト、命名、複数案作成では少し高めが役立つことがあります。
実験 3:Attention は関連度で情報を混ぜる
import numpy as np
X = np.array([
[1.0, 0.0],
[0.0, 1.0],
[1.0, 1.0],
])
Q = X
K = X
V = X
scores = Q @ K.T
scaled_scores = scores / np.sqrt(K.shape[1])
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
attention_weights = np.apply_along_axis(softmax, 1, scaled_scores)
output = attention_weights @ V
print("Attention scores:\n", np.round(scaled_scores, 3))
print("Attention weights:\n", np.round(attention_weights, 3))
print("Output representations:\n", np.round(output, 3))
期待される出力:
Attention scores:
[[0.707 0. 0.707]
[0. 0.707 0.707]
[0.707 0.707 1.414]]
Attention weights:
[[0.401 0.198 0.401]
[0.198 0.401 0.401]
[0.248 0.248 0.503]]
Output representations:
[[0.802 0.599]
[0.599 0.802]
[0.752 0.752]]
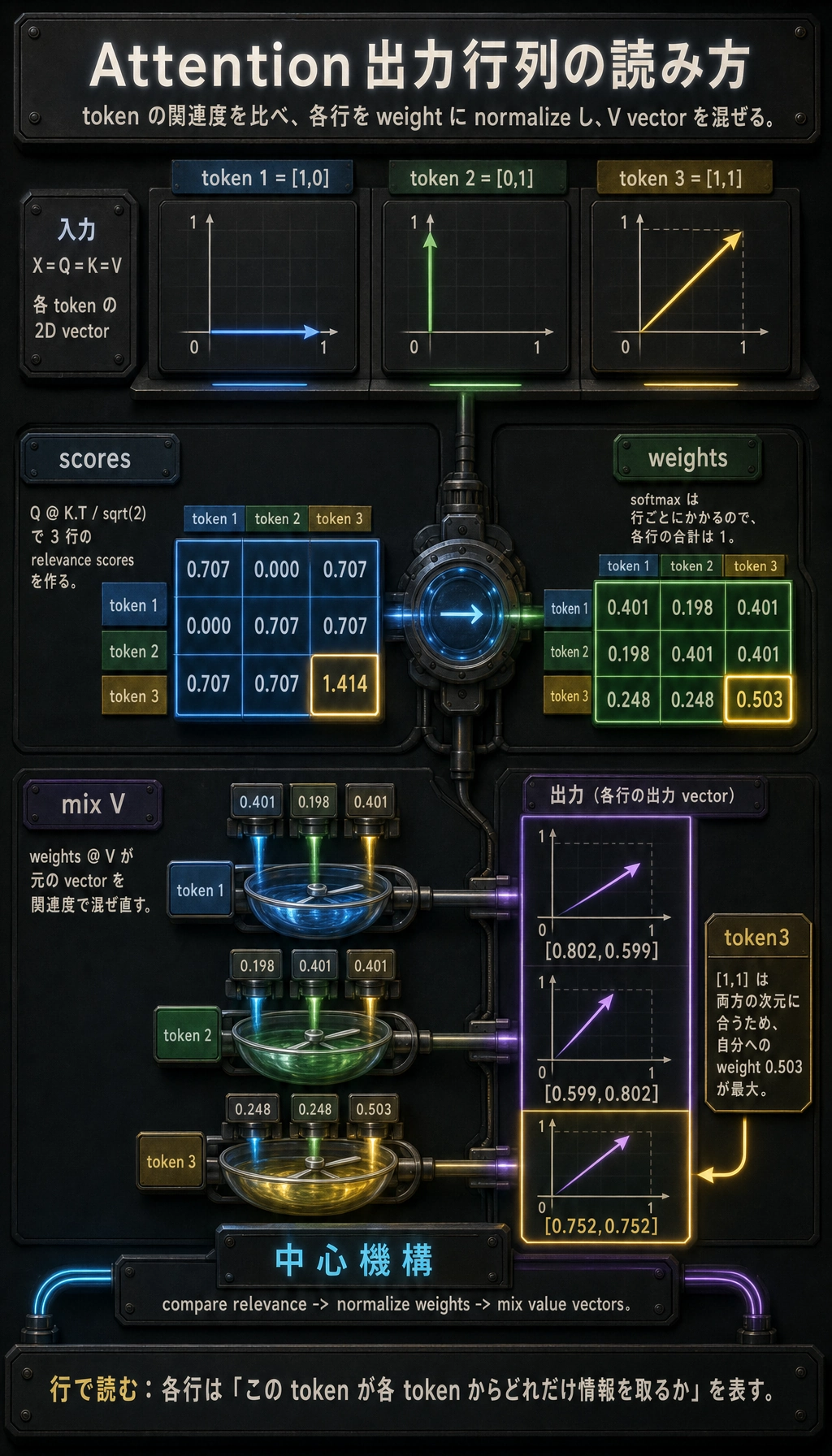
今は式を暗記しなくて大丈夫です。仕組みを覚えます。
compare relevance -> normalize weights -> mix value vectors
Capability はどの層から来るか
| 層 | 何を足すか | model weights を変えるか |
|---|---|---|
| pretraining | 広い言語・世界パターン capability | yes |
| instruction tuning | task following と応答スタイル | yes |
| preference learning / RLHF | より helpful で safer な behavior | yes |
| prompt | runtime の指示と例 | no |
| RAG | runtime の外部 evidence | no |
| tool calling / Agent | テキスト以外の actions | no または一部 |
| fine-tuning / LoRA | repeated domain behavior adaptation | yes |
避けたい誤解
- token は常に 1 単語または 1 文字ではない。
- 大きい context window は、良い記憶と同じではない。
- temperature は diversity を調整するが、truth を保証しない。
- attention weights は直感に役立つが、reasoning の完全な説明ではない。
- pretraining は capability を与える。product reliability には data、evaluation、controls が必要。
練習
- 実験 1 の最初の logit を
4.0から2.2に変える。勝者の confidence はどう変わるか。 - 実験 2 で
temperature=0.1とtemperature=5.0を試す。 - 実験 3 で 3 つ目の token vector を
[1.0, 1.0]から[2.0, 0.0]に変える。何が起きるか。 - 1,000 token の RAG budget を設計する。system prompt、evidence、user question、answer space にどう割り振るか。
- model に capability があっても RAG や alignment が必要になる理由を説明する。
まとめ
核心概念はつながっています。
tokens fill the context -> Transformer mixes token information -> logits score next tokens -> sampling chooses one -> adaptation makes behavior useful
この loop が分かると、RAG、Agent、fine-tuning、evaluation は同じ model core の周りにある engineering choices として見えます。