7.2.3 大模型核心概念
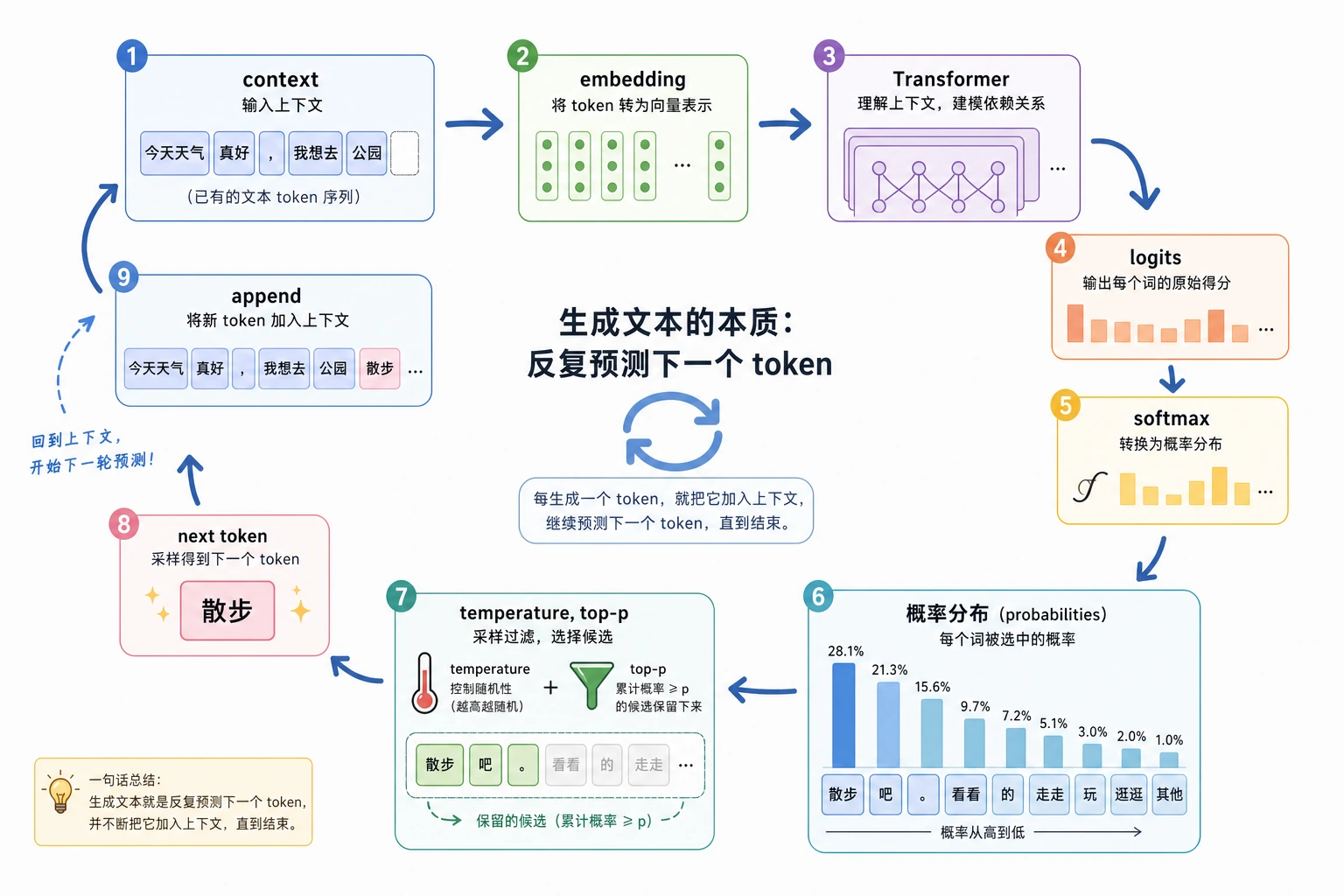
核心循环
大语言模型不是一次写完整答案,而是不断重复:
context -> logits -> probabilities -> choose next token -> append token -> repeat
概念地图
| 概念 | 实操含义 |
|---|---|
| token | 模型读写的基本单位 |
| context window | system prompt、历史、证据、问题和输出共享的 token 预算 |
| embedding | token 的向量表示 |
| attention | 按相关性加权混合 token 信息 |
| logits | 变成概率之前的原始分数 |
| temperature | 让概率分布更尖锐或更平的旋钮 |
| pretraining | 来自大规模文本的通用能力 |
| instruction tuning / alignment | 让能力更像助手行为 |
实验 1:预测下一个 token
import numpy as np
context = "Beijing is China's"
candidates = ["capital", "city", "university"]
logits = np.array([4.0, 2.0, 0.5])
def softmax(x):
e = np.exp(x - x.max())
return e / e.sum()
probs = softmax(logits)
best = candidates[np.argmax(probs)]
print("Context:", context)
for token, prob in zip(candidates, probs):
print(f"Candidate token={token}, probability={prob:.3f}")
print("Most likely next token:", best)
预期输出:
Context: Beijing is China's
Candidate token=capital, probability=0.858
Candidate token=city, probability=0.116
Candidate token=university, probability=0.026
Most likely next token: capital
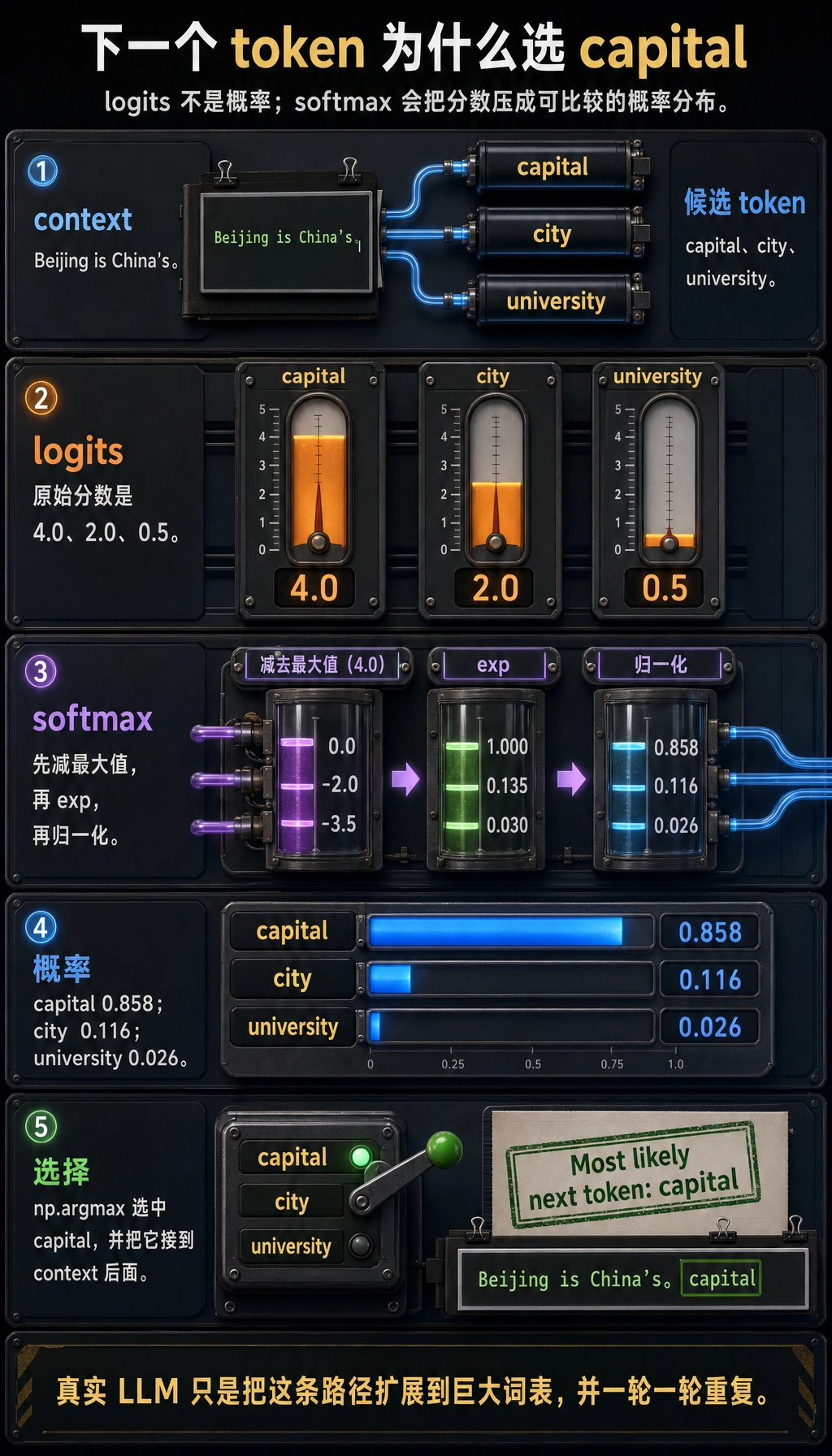
真实模型会在很大的词表上做这件事。原则一样:输出分数,转成概率,再选择下一个 token。
Context Window 是预算
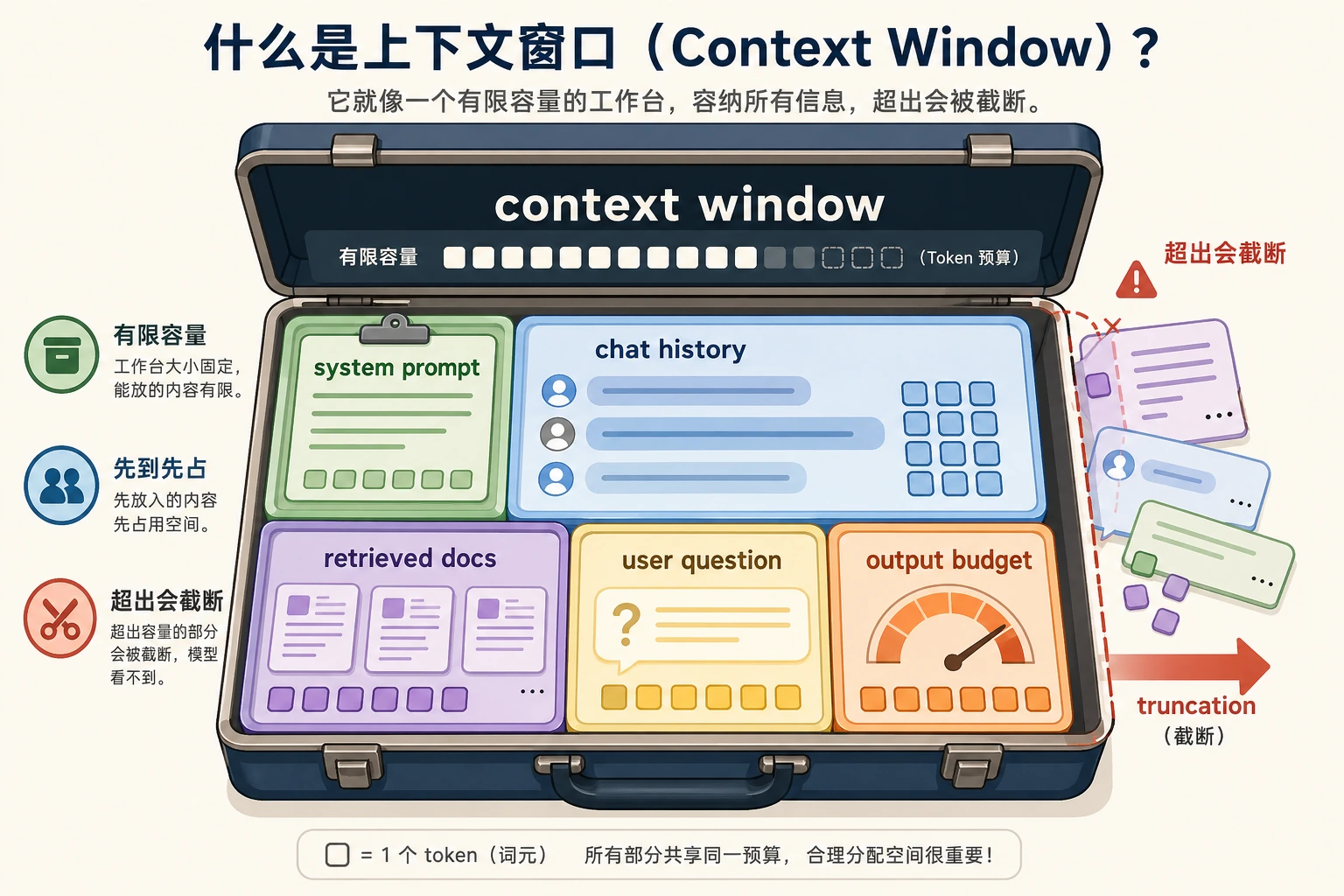
上下文窗口不是无限记忆,而是一段固定 token 预算:
system prompt + chat history + retrieved evidence + user question + answer space <= context window
实操影响:
- 长文档必须筛选、压缩或分块;
- RAG 要同时给证据和最终回答留空间;
- 聊天历史不再有帮助时要总结或裁剪;
- 更大上下文只有在放进正确信息时才有用。
实验 2:Temperature 改变采样
import numpy as np
tokens = ["Beijing", "Shanghai", "Guangzhou"]
logits = np.array([3.0, 1.5, 0.5])
def softmax_with_temperature(logits, temperature=1.0):
scaled = logits / temperature
exp_values = np.exp(scaled - scaled.max())
return exp_values / exp_values.sum()
for temp in [0.5, 1.0, 2.0]:
probs = softmax_with_temperature(logits, temperature=temp)
print(f"temperature={temp}")
for token, prob in zip(tokens, probs):
print(f" {token}: {prob:.4f}")
预期输出:
temperature=0.5
Beijing: 0.9465
Shanghai: 0.0471
Guangzhou: 0.0064
temperature=1.0
Beijing: 0.7662
Shanghai: 0.1710
Guangzhou: 0.0629
temperature=2.0
Beijing: 0.5685
Shanghai: 0.2686
Guangzhou: 0.1629
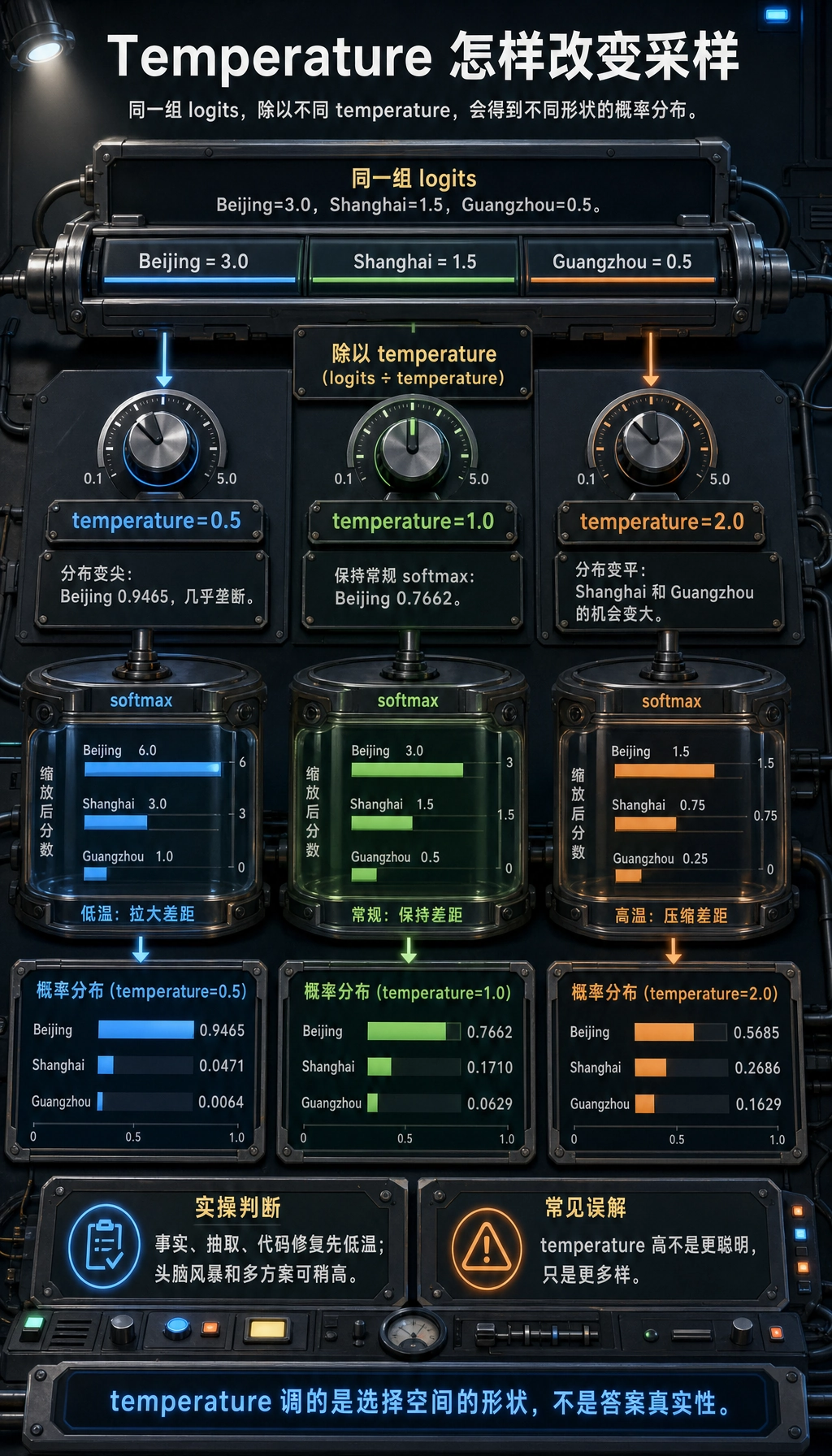
这样理解:
- temperature 越低,最高分选项越占优势;
- temperature 越高,低排名 token 越有机会;
- temperature 高不等于更聪明,只代表更多样。
做事实问答、抽取、代码修复时通常先用较低 temperature。做头脑风暴、命名、生成多方案时可以稍高。
实验 3:Attention 是按相关性混合信息
import numpy as np
X = np.array([
[1.0, 0.0],
[0.0, 1.0],
[1.0, 1.0],
])
Q = X
K = X
V = X
scores = Q @ K.T
scaled_scores = scores / np.sqrt(K.shape[1])
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
attention_weights = np.apply_along_axis(softmax, 1, scaled_scores)
output = attention_weights @ V
print("Attention scores:\n", np.round(scaled_scores, 3))
print("Attention weights:\n", np.round(attention_weights, 3))
print("Output representations:\n", np.round(output, 3))
预期输出:
Attention scores:
[[0.707 0. 0.707]
[0. 0.707 0.707]
[0.707 0.707 1.414]]
Attention weights:
[[0.401 0.198 0.401]
[0.198 0.401 0.401]
[0.248 0.248 0.503]]
Output representations:
[[0.802 0.599]
[0.599 0.802]
[0.752 0.752]]

暂时不用背公式,先记住机制:
compare relevance -> normalize weights -> mix value vectors
能力来自哪些层
| 层 | 提供什么 | 是否改变模型权重 |
|---|---|---|
| pretraining | 通用语言和世界模式能力 | 是 |
| instruction tuning | 更会按任务和格式回答 | 是 |
| preference learning / RLHF | 更有帮助、更安全的行为 | 是 |
| prompt | 运行时任务说明和示例 | 否 |
| RAG | 运行时外部证据 | 否 |
| tool calling / Agent | 文本以外的动作能力 | 否或部分改变 |
| fine-tuning / LoRA | 重复领域行为适配 | 是 |
避免误解
- token 不总是一个词或一个字。
- 更大 context window 不等于更好记忆。
- temperature 控制多样性,不控制真实性。
- attention 权重能帮助理解,但不是推理过程的完整解释。
- 预训练给能力,产品可靠性仍然需要数据、评估和控制。
练习
- 把实验 1 的第一个 logit 从
4.0改成2.2,胜出 token 的置信度怎样变? - 在实验 2 里试试
temperature=0.1和temperature=5.0。 - 把实验 3 第三个 token 向量从
[1.0, 1.0]改成[2.0, 0.0],观察变化。 - 设计一个 1,000 token 的 RAG 预算:system prompt、证据、用户问题、回答空间各多少?
- 解释为什么模型有能力,但仍可能需要 RAG 或 alignment。
小结
核心概念是连在一起的:
tokens fill the context -> Transformer mixes token information -> logits score next tokens -> sampling chooses one -> adaptation makes behavior useful
看清这条循环以后,RAG、Agent、微调和评估都会变成围绕同一个模型核心做工程选择。