7.2.5 实操:LLM 调用工作台
这一节把前面的概念变成一个能跟着做的流程。先不要急着比较哪个模型最强,先学会一次完整 LLM 调用到底发生了什么:用户任务、Token 预算、请求载荷、模型输出、校验和重试。
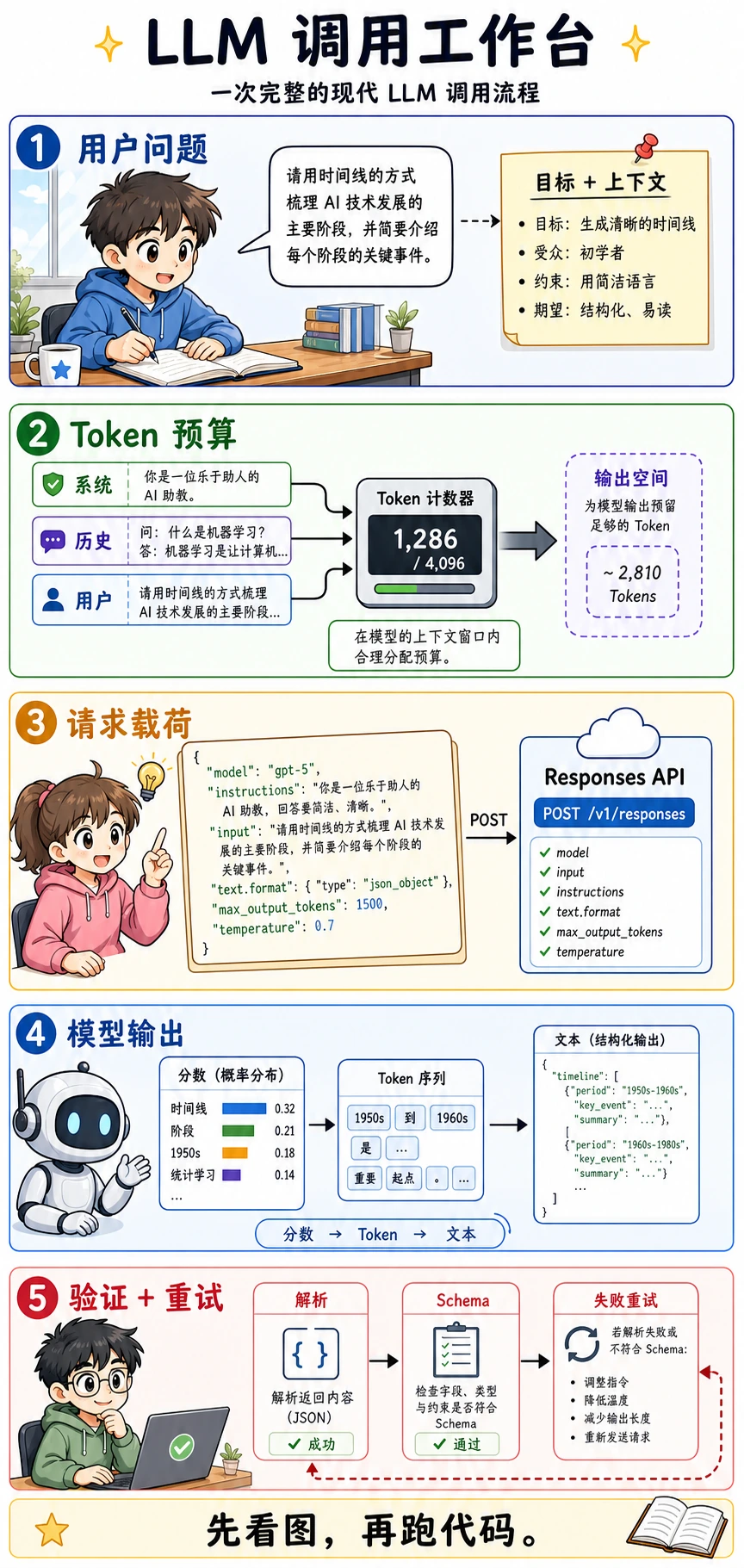
按照“先看图,再跑代码,最后看术语和公式”的顺序学习。只要能把一次请求从输入追踪到可用输出,LLM 工程就不会那么像黑盒。
这一节要练什么
学完这一节后,你应该能解释:
- 一个 API 请求到底把什么发送给模型。
- 为什么上下文窗口本质上是 Token 预算。
- 为什么结构化输出必须解析和校验。
- 为什么失败重试不能盲目再问一次,而要修复失败原因。
- 为什么只打印出一段漂亮回答,还不能算可靠产品功能。
看代码前先理解这些术语
| 术语 | 通俗解释 | 在本节中的作用 |
|---|---|---|
| API | Application Programming Interface,软件调用另一个服务的标准接口 | 程序把请求发给模型服务,并接收响应 |
| SDK | Software Development Kit,把 API 调用封装成更好用的代码库 | 可选真实 API 示例会使用官方 Python SDK |
| Endpoint | 接收请求的 URL 路径 | 现代 OpenAI 文本 API 端点是 /v1/responses |
| Payload | 发送给 API 的 JSON 请求体 | 包含模型名、指令、输入、输出设置和约束 |
| Token 预算 | 上下文窗口里可用的空间 | 系统规则、历史消息、用户输入、检索材料和输出空间都会竞争它 |
| JSON | 程序容易解析的结构化数据格式 | 我们要求模型返回时间线对象,而不是自由段落 |
| Schema | JSON 应该长什么样的约定 | 告诉程序哪些字段必须存在、字段类型是什么 |
| Validation | 程序对输出做校验 | 捕捉缺字段、类型错误和无效 JSON |
| Retry | 在可控失败后重试 | 有价值的重试会修复原因,例如加强 Schema 约束 |
| Latency | 请求耗时 | 上下文越长、输出越长,通常延迟越高 |
先跑离线工作台
第一个示例只使用 Python 标准库,不会调用真实模型。这是有意设计的:你不需要 API key、网络或付费模型,就能先理解完整工程闭环。
保存为 llm_call_workbench.py,然后运行:
python llm_call_workbench.py
import json
CONTEXT_LIMIT = 4096
def rough_token_count(text):
# A real tokenizer is more complex. This simple counter is enough for budget intuition.
return max(1, len(text.split()))
def build_payload(user_task, max_output_tokens=600, temperature=0.3):
instructions = (
"You are a teaching assistant. Return valid JSON only. "
"Each timeline era must include period, key_event, and summary."
)
input_text = (
"Create a beginner-friendly timeline of AI development with four eras. "
f"User task: {user_task}"
)
used_tokens = rough_token_count(instructions) + rough_token_count(input_text)
remaining = CONTEXT_LIMIT - used_tokens - max_output_tokens
payload = {
"model": "gpt-5.5",
"instructions": instructions,
"input": input_text,
"text": {"format": {"type": "json_object"}},
"max_output_tokens": max_output_tokens,
"temperature": temperature,
}
return payload, used_tokens, remaining
def fake_model_response(attempt):
if attempt == 1:
# The first response is intentionally broken: the first era misses "summary".
return """
{
"timeline": [
{"period": "1950s", "key_event": "Turing Test"},
{"period": "2017", "key_event": "Transformer", "summary": "Self-attention became the backbone of LLMs."}
]
}
"""
return """
{
"timeline": [
{"period": "1936-1950", "key_event": "Turing machine and Turing Test", "summary": "AI became a testable question."},
{"period": "1956-1980s", "key_event": "Symbolic AI and expert systems", "summary": "Rules worked in narrow domains but did not scale well."},
{"period": "1990s-2012", "key_event": "Statistical learning and deep learning", "summary": "Data and neural networks replaced many hand-written rules."},
{"period": "2017-now", "key_event": "Transformer and LLMs", "summary": "Self-attention, scale, and alignment made general assistants practical."}
]
}
"""
def validate_timeline(text):
try:
data = json.loads(text)
except json.JSONDecodeError:
return False, "invalid_json", None
if "timeline" not in data or not isinstance(data["timeline"], list):
return False, "missing_timeline_list", None
required_fields = {"period", "key_event", "summary"}
for index, era in enumerate(data["timeline"]):
if not isinstance(era, dict):
return False, f"era_{index}_not_object", None
missing = required_fields - set(era)
if missing:
return False, f"era_{index}_missing_{sorted(missing)}", None
return True, "valid", data
def run_workbench(user_task):
payload, used_tokens, remaining = build_payload(user_task)
print("used input tokens estimate:", used_tokens)
print("remaining output room :", remaining)
print("request model :", payload["model"])
for attempt in [1, 2]:
print("\nattempt:", attempt)
raw_output = fake_model_response(attempt)
ok, reason, parsed = validate_timeline(raw_output)
print("validation:", reason)
if ok:
print("first era:", parsed["timeline"][0])
return parsed
payload["instructions"] += " Do not omit any required field."
payload["temperature"] = 0.1
print("retry fix: strengthen schema instruction and lower temperature")
raise RuntimeError("Could not get a valid timeline after retries.")
run_workbench("Explain AI history with simple language.")
预期输出大致长这样:
used input tokens estimate: 36
remaining output room : 3460
request model : gpt-5.5
attempt: 1
validation: era_0_missing_['summary']
retry fix: strengthen schema instruction and lower temperature
attempt: 2
validation: valid
first era: {'period': '1936-1950', ...}
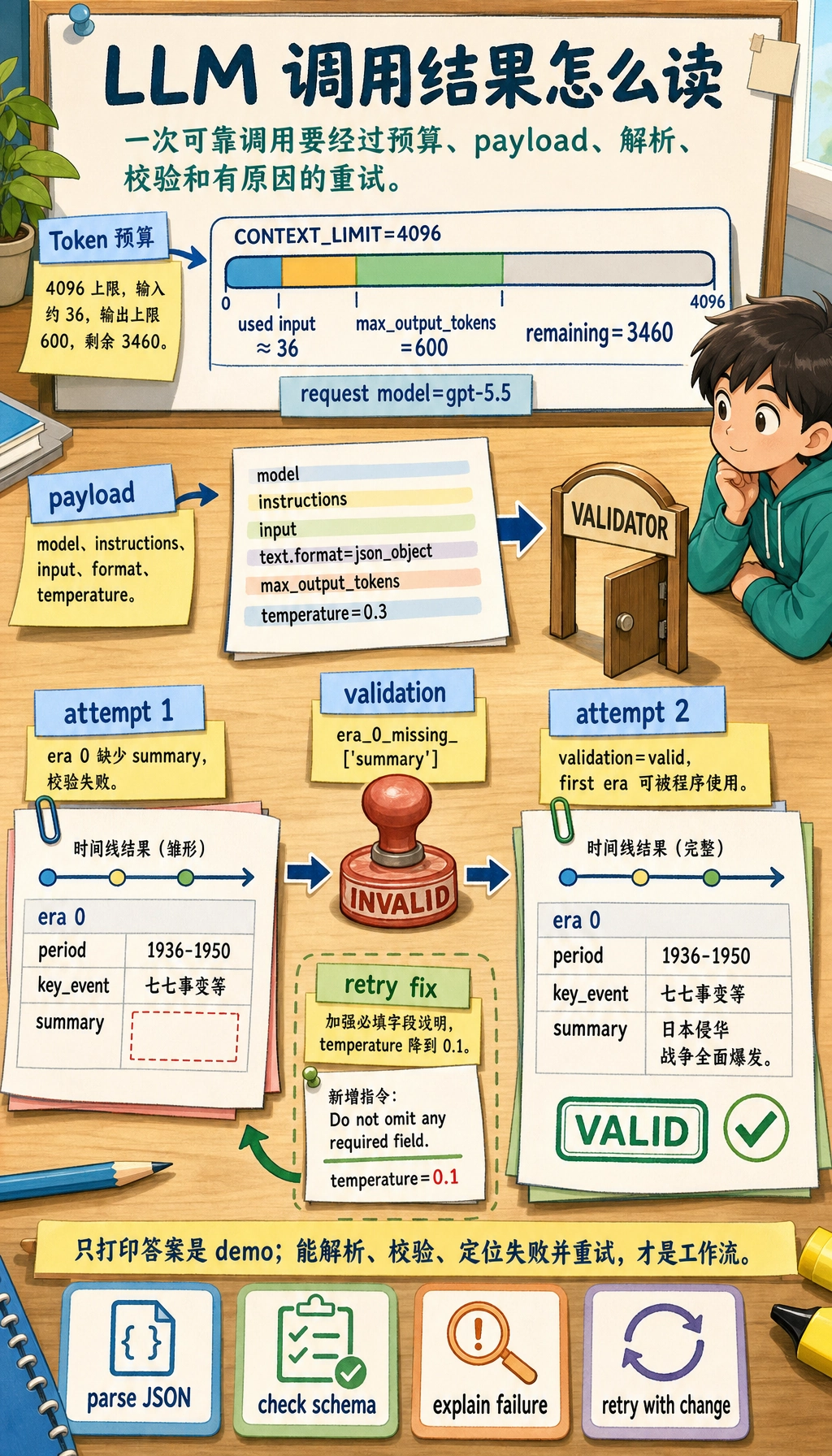
这段代码真正想说明什么
请求不只是 Prompt
Payload 里包含 model、instructions、input、text.format、max_output_tokens 和 temperature。很多新人只会改 Prompt 文本,但真实 LLM 工程还会控制输出长度、格式、随机性和校验方式。
Token 预算是产品约束
模型不能看到无限长的文本。系统指令、用户消息、历史对话、检索材料和输出空间都共享上下文窗口。如果你把窗口全部塞满背景材料,模型可能没有足够空间回答。
校验把演示变成工作流
打印响应只是演示。工作流必须解析输出、检查必需字段、识别失败类型,并决定是重试、让用户补充信息,还是转人工处理。
重试应该修复原因
盲目重试会浪费时间和成本。更好的重试会改变具体问题:
| 失败现象 | 更好的重试方式 |
|---|---|
| JSON 无效 | 要求只输出 JSON、减少额外解释,或使用结构化输出 |
| 缺少字段 | 重复必填字段,并明确这些字段不可省略 |
| 输出过长 | 降低 max_output_tokens,或要求更短格式 |
| 分类不稳定 | 降低 temperature,并增加示例 |
| 缺少知识 | 加入检索上下文,或把问题留到后面的 RAG 阶段解决 |
可选:真实 Responses API 调用
如果你有 API key,可以使用官方 OpenAI Python SDK 和现代 Responses API 跑同样的思路。建议先理解离线工作台,再运行真实调用。
python -m pip install --upgrade openai pydantic
export OPENAI_API_KEY="your_api_key_here"
python real_responses_call.py
import os
from pydantic import BaseModel
from openai import OpenAI
class Era(BaseModel):
period: str
key_event: str
summary: str
class Timeline(BaseModel):
timeline: list[Era]
client = OpenAI()
response = client.responses.parse(
model=os.getenv("OPENAI_MODEL", "gpt-5.5"),
input=[
{
"role": "system",
"content": (
"You are a teaching assistant. Return a concise beginner-friendly "
"AI history timeline."
),
},
{
"role": "user",
"content": "Create a four-era AI development timeline for beginners.",
},
],
text_format=Timeline,
)
print(response.output_parsed.model_dump())
新的文本生成应用优先使用 Responses API,而不是从更旧的 chat-completion 示例开始。关键工程思路和离线工作台一样:构造请求、控制输出、解析结果,并确认结果真的能被程序使用。
如果你的账号或部署使用其他已批准模型,可以设置 OPENAI_MODEL。示例保留模型名可配置,避免课程代码永远绑定一个固定默认值。
练习方式
- 把离线任务从“AI 历史时间线”改成“课程学习计划”,并更新必填 Schema 字段。
- 把第一次假模型输出改成无效 JSON,观察校验器是否能发现。
- 给每个阶段增加
source_refs字段,并在校验器里要求它存在。 - 降低
max_output_tokens,解释这模拟了什么产品问题。 - 写一页笔记:哪些部分属于 Prompt 设计,哪些属于 API Payload 设计,哪些属于应用可靠性设计。
总结
一次真实 LLM 调用不是“发一个问题,拿一个回答”这么简单。它是一个小型工程闭环:
定义任务、管理 Token 预算、发送清晰 Payload、解析输出、校验 Schema,并且只在知道失败原因时重试。
熟悉这个闭环以后,Prompt、结构化输出、RAG、工具调用和 Agent 工作流都会更像同一个基础能力的延伸,而不是互不相关的名词。