7.2.4 大模型产业格局
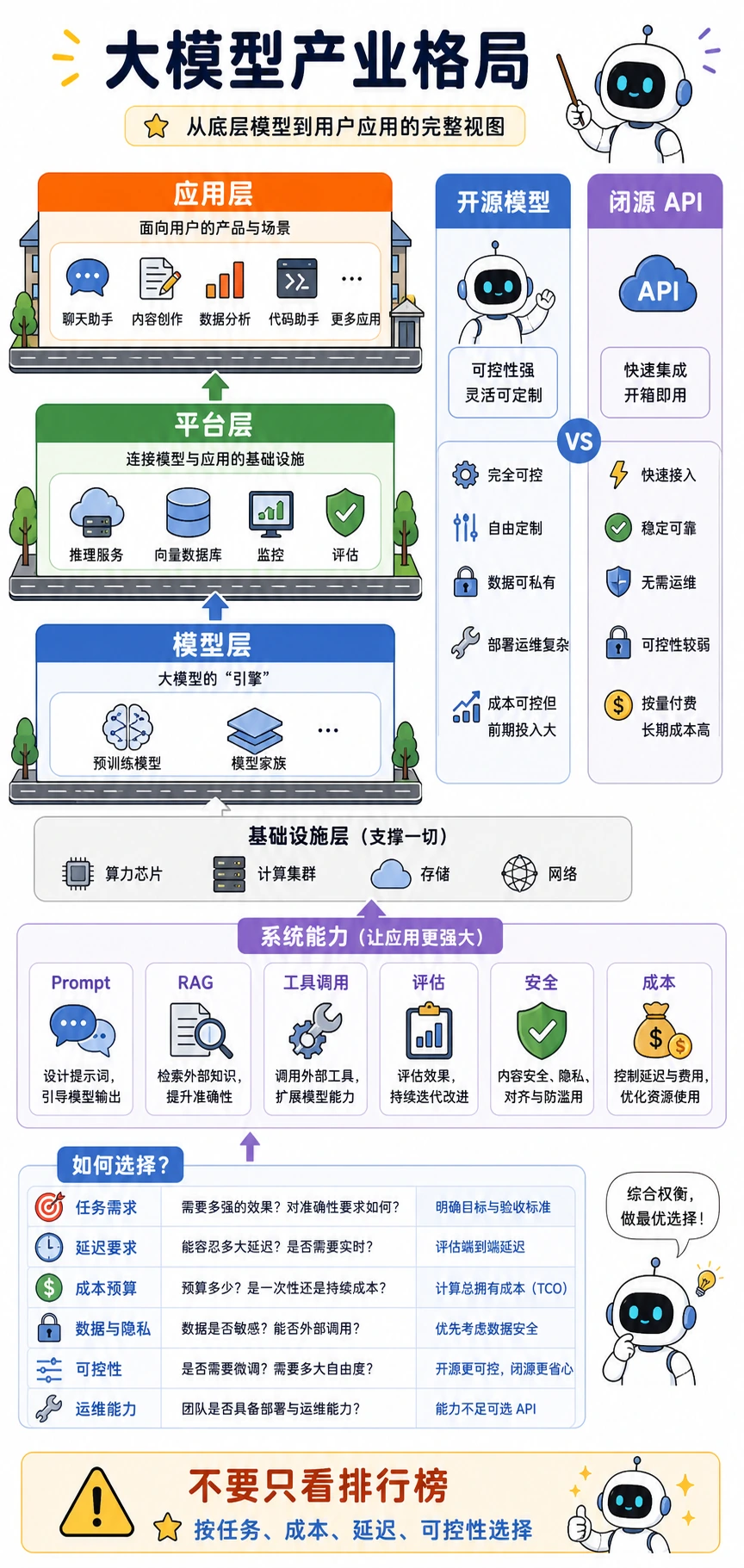
把它当成一栋楼来看:模型层提供“发动机”,平台层让发动机可调用、可观察、可运维,应用层把能力变成用户能使用的工作流。开源和闭源 API 不是“谁绝对更好”,而是在可控性、成本、延迟、隐私和运维之间做不同取舍。
学习目标
完成本节后,你将能够:
- 从产业链视角理解大模型生态
- 分清模型层、平台层、应用层分别在做什么
- 理解开源与闭源路线的不同优势
- 用一个小例子练习模型选型思路
一、先把产业链拆开看
模型层:谁在造“发动机”?
模型层主要负责训练基础模型和通用模型。 你可以把它理解成“造发动机的人”。
这层通常关注:
- 模型架构
- 训练数据
- 训练算力
- 模型能力
常见形态包括:
- 闭源 API 模型
- 开源可下载模型
- 行业专用模型
平台层:谁在让模型更容易被用?
平台层像“修路和供电的人”。
它们常做的事包括:
- 模型托管
- 推理服务
- 向量数据库
- 监控与评估
- 微调平台
- Agent / workflow 开发框架
如果没有平台层,很多团队即使拿到模型,也很难稳定落地。
新人术语速查:平台层常见词
| 术语 | 它是什么意思 | 为什么重要 |
|---|---|---|
| API | 调用模型或服务的标准接口 | 让应用不用管理模型内部细节,也能请求模型结果 |
| 推理 | 运行模型并产生输出 | 用户每问一次问题,背后通常都会发生一次推理 |
| 向量数据库 | 专门存储和检索 embedding 的数据库 | RAG 系统常用它作为检索层 |
| 监控 | 持续观察延迟、错误、成本和输出质量 | 生产系统需要靠它及时发现问题 |
| 评估 | 衡量输出是否满足任务要求 | 避免团队只凭感觉判断模型好坏 |
二、应用层:真正离用户最近
应用层卖的不是模型,而是结果
应用层更像“开餐厅的人”。
用户通常不关心你用的是哪种注意力机制,用户关心的是:
- 能不能帮我完成任务
- 回答是否可靠
- 速度够不够快
- 成本能不能接受
典型应用包括:
- AI 搜索
- AI 客服
- AI 编程助手
- AI 办公工具
- AI 教学助手
同一个模型,可以长出很多不同产品
同一个基础模型,在不同团队手里可能会变成完全不同的产品:
- 法务助手
- 销售助手
- 教育助教
- 代码评审工具
这说明产业竞争并不只发生在“谁模型更大”,也发生在:
- 工作流设计
- 数据积累
- 产品体验
- 行业 know-how
三、开源路线和闭源路线怎么选?
闭源模型更像“即插即用的成熟发动机”
优势通常是:
- 开箱效果强
- 模型维护工作少
- 上线速度快
代价通常是:
- 成本按调用计费
- 可控性较弱
- 私有部署受限
开源模型更像“可自己改装的发动机”
优势通常是:
- 可自部署
- 可微调
- 数据和推理链路更可控
代价通常是:
- 部署和维护更复杂
- 效果不一定天然最强
- 需要更多工程能力
一句话记忆:
闭源偏省心,开源偏可控。
四、很多团队真正比拼的是“系统能力”
模型只是系统中的一个零件
现实中的大模型产品,往往不是“模型单打独斗”,而是整套系统协作:
- Prompt
- RAG
- 工具调用
- 评估体系
- 安全策略
- 成本控制
也就是说:
用户体验 = 模型能力 × 系统设计 × 数据质量
为什么同一个模型,不同产品体验差很多?
因为真正决定体验的,往往还包括:
- 知识库好不好
- 工具准不准
- 失败时有没有兜底
- 延迟控制得好不好
这也是为什么“会调 API”不等于“会做 AI 产品”。
五、一个实用的模型选型框架
不要先问“谁最强”,先问“我需要什么”
常见选型维度有:
| 维度 | 你要问的问题 |
|---|---|
| 质量 | 任务效果够不够好? |
| 成本 | 每次调用贵不贵? |
| 延迟 | 用户能不能接受响应速度? |
| 可控性 | 能不能私有部署、微调、审计? |
| 多模态 | 是否需要看图、听音频? |
| 工具能力 | 是否要 function calling / agent? |
一个小型评分脚本
下面这个例子不是在选真实最新模型,而是在练习“怎么按需求评分”。
models = {
"cloud_api_model": {
"quality": 9,
"cost": 4,
"latency": 8,
"control": 4
},
"open_source_8b": {
"quality": 6,
"cost": 9,
"latency": 7,
"control": 9
},
"open_source_70b": {
"quality": 8,
"cost": 5,
"latency": 5,
"control": 9
}
}
weights = {
"quality": 0.4,
"cost": 0.2,
"latency": 0.2,
"control": 0.2
}
def score_model(info, weights):
return sum(info[k] * weights[k] for k in weights)
scores = []
for name, info in models.items():
scores.append((score_model(info, weights), name))
for score, name in sorted(scores, reverse=True):
print(name, "->", round(score, 2))
预期输出:
open_source_8b -> 7.4
open_source_70b -> 7.0
cloud_api_model -> 6.8

你可以把 weights 改掉,模拟不同公司的不同偏好。
六、为什么“产业格局”对工程师也重要?
因为你每天都在做技术选型
你会不断遇到这些问题:
- 用 API 还是自部署?
- 先做 RAG 还是先做微调?
- 用通用模型还是垂直模型?
- 用单模型还是多模型路由?
这些问题本质上都和产业结构有关。
因为技术路线会影响职业路径
不同岗位更偏向不同能力:
- 基础模型:更偏训练和算法
- 平台工程:更偏推理、部署、优化
- 应用工程:更偏产品、工作流、评估
知道产业格局,能帮你更清楚自己想往哪类岗位走。
七、初学者常见误区
只盯着排行榜
排行榜有价值,但它不是全部。 真实项目里,成本、时延、稳定性同样关键。
以为“开源一定便宜”
模型本身开源,不代表训练、部署、维护都便宜。
以为“有最好模型”这件事总成立
很多时候没有“绝对最好”,只有“当前场景下最合适”。
小结
这一节最重要的认识是:
大模型产业不是只比模型参数,而是在比模型、平台、数据、产品和工程能力的组合。
做应用的人理解产业格局,不是为了追热点,而是为了做出更稳的技术和产品决策。
练习
- 修改评分脚本里的权重,分别模拟“创业团队”和“金融企业”的选型偏好。
- 想一想:如果你的项目要求私有部署,开源和闭源路线的优先级会怎么变?
- 用自己的话解释:为什么很多时候真正的竞争优势不只是模型本身?