7.1.4 预训练语言模型速览
一个实用判断
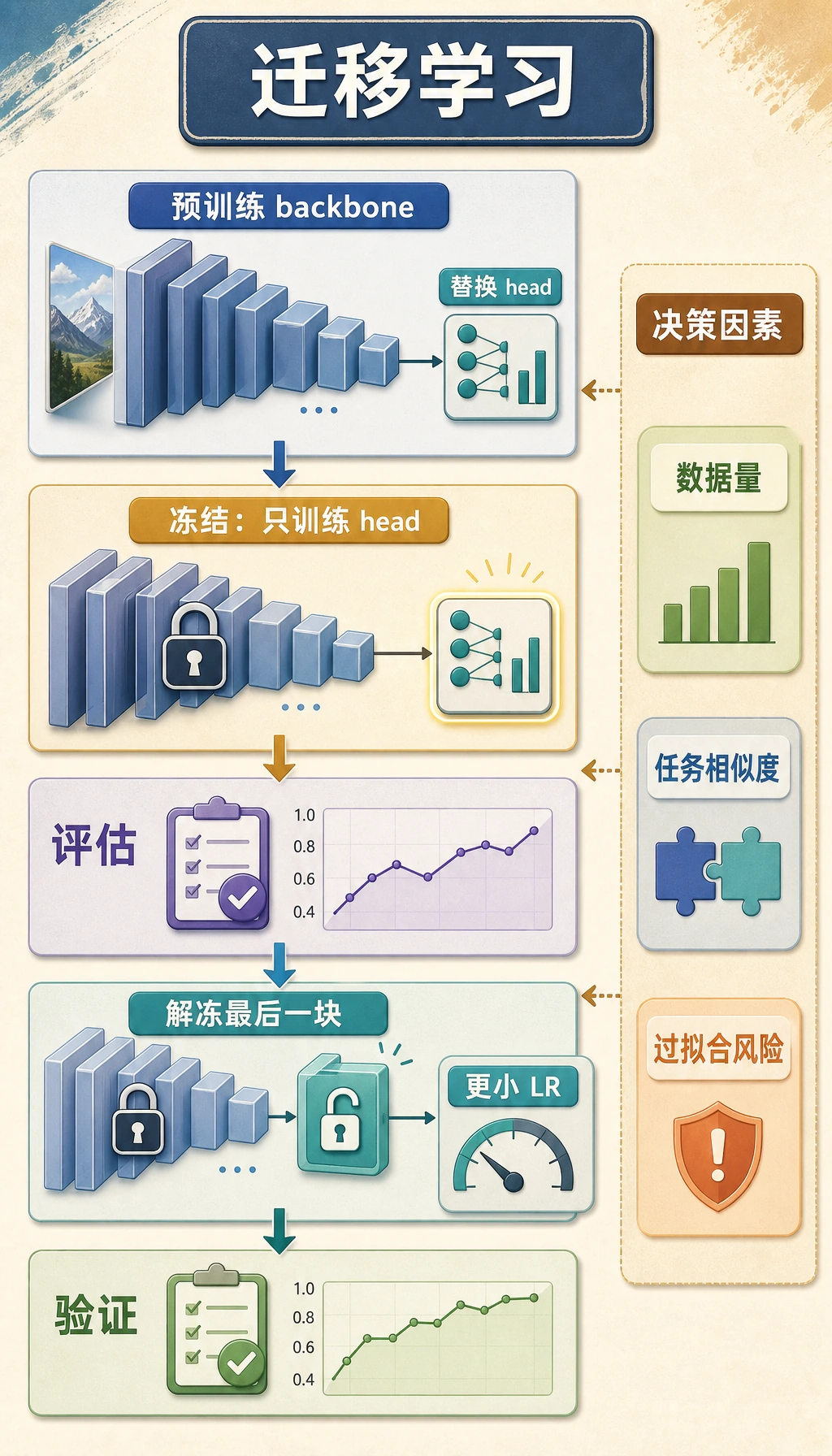
预训练模型不是自动懂你业务的魔法模型。它是可复用的语言基础。你的任务是选择最便宜、最可靠的方式,把这个基础适配到当前任务。
先建立心智模型
预训练普及之前,很多 NLP 任务都要各自训练模型和数据流程。现代 NLP 的起点不同:
large general corpus -> pretrained foundation -> task adaptation -> product behavior
基础模型已经学到有用的语言模式。你的任务通常只需要选择一种适配:
- 把 prompt 写得更稳;
- 用 RAG 补充缺失知识;
- 训练一个小 task head;
- 用 LoRA 或全量更新微调;
- 评估并加上行为护栏。
预训练到底给了什么
预训练通常给三类实用资产:
| 资产 | 含义 | 例子 |
|---|---|---|
| 可复用表示 | 文本已经能映射到有用 hidden states | 分类、排序、检索 |
| 可复用生成能力 | 模型能续写或转换文本 | 对话、写作、代码生成 |
| 可复用语言先验 | 语法、常见模式、高频事实 | 下游样本需求更少 |
它不保证知识最新、业务政策正确、行为安全。这些仍然需要数据、检索、评估和部署控制。
实验:共享基础模型 + 两个任务头
这个玩具例子不会训练真实 LLM,但能展示结构:一个共享 encoder,两个不同 head。
from math import exp
word_vectors = {
"refund": [0.9, 0.8, 0.1],
"order": [0.8, 0.7, 0.2],
"password": [0.1, 0.2, 0.9],
"reset": [0.1, 0.1, 0.95],
"great": [0.7, 0.2, 0.1],
"bad": [0.2, 0.8, 0.1],
}
def encode(text):
tokens = text.lower().split()
valid = [word_vectors[token] for token in tokens if token in word_vectors]
dim = len(valid[0])
return [sum(vec[i] for vec in valid) / len(valid) for i in range(dim)]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
def softmax(scores):
exps = [exp(score) for score in scores]
total = sum(exps)
return [value / total for value in exps]
intent_head = {
"refund_intent": [1.0, 0.9, 0.1],
"password_intent": [0.1, 0.2, 1.0],
}
sentiment_head = {
"positive": [1.0, 0.2, 0.0],
"negative": [0.1, 1.0, 0.0],
}
def classify(vector, head):
labels = list(head.keys())
scores = [dot(vector, head[label]) for label in labels]
probs = softmax(scores)
best = max(zip(labels, probs), key=lambda item: item[1])
rounded = dict(zip(labels, [round(prob, 3) for prob in probs]))
return best, rounded
for text in ["refund order", "reset password"]:
vector = encode(text)
best, probs = classify(vector, intent_head)
print("intent:", text, "->", best, probs)
for text in ["great refund", "bad refund"]:
vector = encode(text)
best, probs = classify(vector, sentiment_head)
print("sentiment:", text, "->", best, probs)
预期输出:
intent: refund order -> ('refund_intent', 0.7604230019887309) {'refund_intent': 0.76, 'password_intent': 0.24}
intent: reset password -> ('password_intent', 0.654188113761243) {'refund_intent': 0.346, 'password_intent': 0.654}
sentiment: great refund -> ('positive', 0.5793242521487495) {'positive': 0.579, 'negative': 0.421}
sentiment: bad refund -> ('negative', 0.5361866202317948) {'positive': 0.464, 'negative': 0.536}

这样读:
encode()是共享基础;intent_head和sentiment_head是任务适配层;- 基础被复用,最后的决策层不同;
- 真实模型用的是百万到千亿级参数,而不是手写向量。
主要模型家族
| 家族 | 典型信息流 | 擅长 | 例子 |
|---|---|---|---|
| Encoder-only | 双向读取输入 | 分类、抽取、匹配、embedding | BERT 类模型 |
| Decoder-only | 按因果顺序预测下一个 token | 对话、补全、代码、工具调用 | GPT/LLaMA/Qwen 类模型 |
| Encoder-decoder | 先读输入,再生成输出 | 翻译、摘要、结构化生成 | T5/BART 类模型 |
这只是第一层筛选,不是最终规则。现代系统常常会结合检索、工具和服务成本一起设计。
选择适配路径
| 情况 | 通常先试 | 原因 |
|---|---|---|
| 模型已经懂任务格式 | 优化 prompt | 迭代最快 |
| 答案依赖私有或最新知识 | RAG | 不改权重也能更新知识 |
| 需要稳定标签或分数 | task head / classifier | 成本低、容易评估 |
| 风格或领域行为要明显迁移 | LoRA / PEFT | 成本可控地改变行为 |
| 任务高度专用且数据强 | 全量微调 | 灵活度最高,风险和成本也最高 |
这是工程决策,不是信仰选择。优先选择能通过评估的最小改动。
常见失败模式
- **预训练数据不匹配:**模型学过通用语言,不等于懂你的具体政策。
- **知识过期:**模型可能不知道近期事实。
- **数据污染:**评测或测试数据可能进入过类似训练语料。
- **过度适配:**微调可能改善一个行为,同时损伤其他能力。
- **评估缺口:**演示 prompt 好看,不代表边界样本可靠。
练习
- 给实验添加
topic_head,标签为account_topic和commerce_topic。 - 修改
bad的向量,观察 sentiment 置信度怎样变化。 - 如果做一个带私有政策的客服 bot,你会先用 prompt、RAG、task head 还是微调?说明理由。
- 在生产中信任一个预训练模型前,你会做哪两个检查?
- 解释为什么“模型更大”和“更适合当前任务”不是一回事。
小结
预训练改变了工作流:
do not relearn language every time -> reuse a foundation -> adapt with evidence
看懂这个模式后,Prompt、RAG、微调、对齐和 Agent 都会变成:用不同方式驾驭同一个可复用基础。