7.1.3 词向量与语义表示
一句话理解
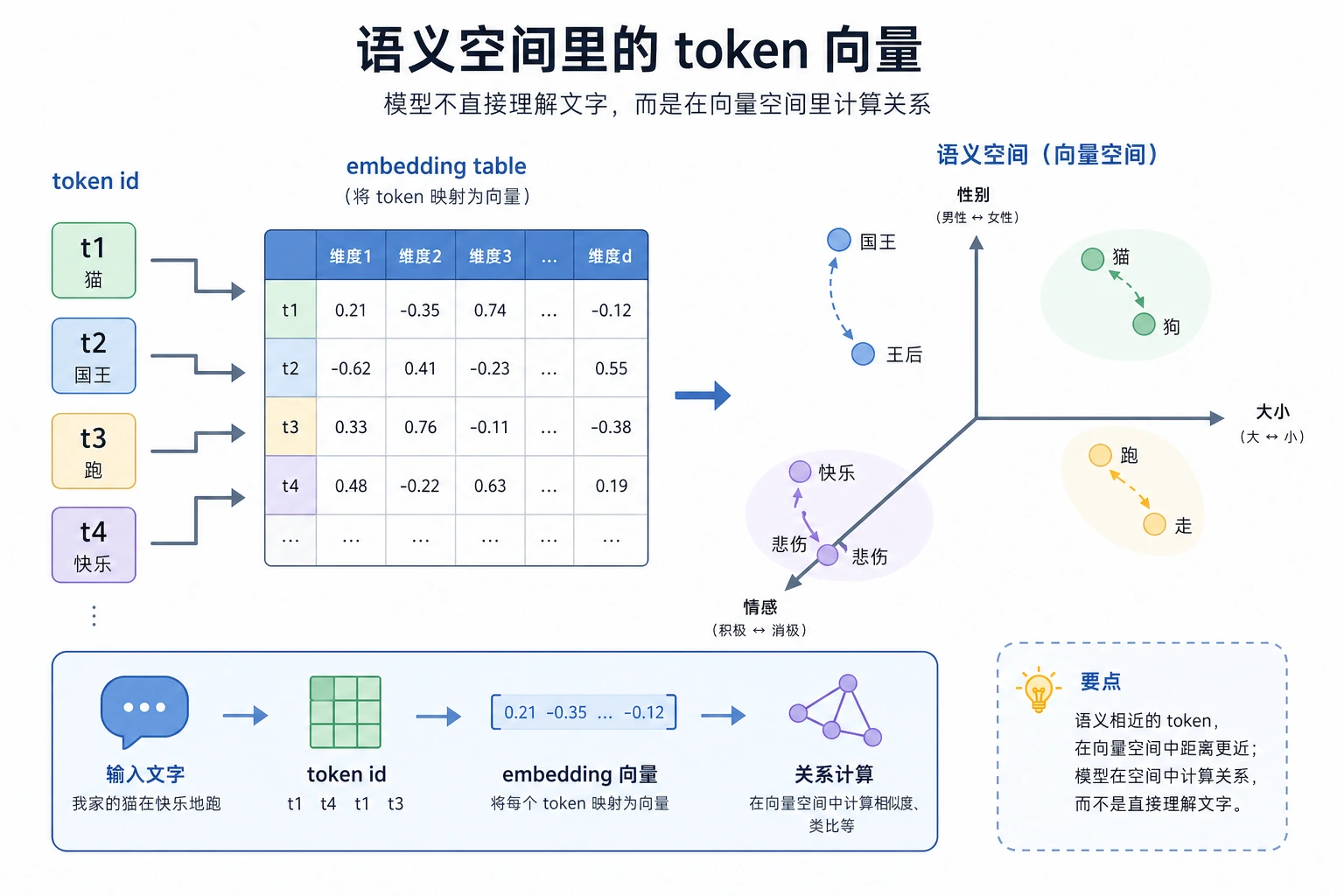
Tokenizer 给模型离散 ID,Embedding 把这些 ID 变成向量,让模型可以比较、组合并在层与层之间传递语义。
先建立心智模型
One-hot ID 能区分词,但不能表达哪些词相关。稠密 embedding 会把 token 放进一个向量空间:
token id -> embedding table lookup -> dense vector
在这个空间里:
- 距离近的向量通常表示用法相关;
- cosine similarity 衡量方向是否相近;
- 句向量通常由 token 向量 pooling 得到;
- 上下文模型能让同一个 token 根据周围词改变位置。
从 One-Hot 到稠密向量
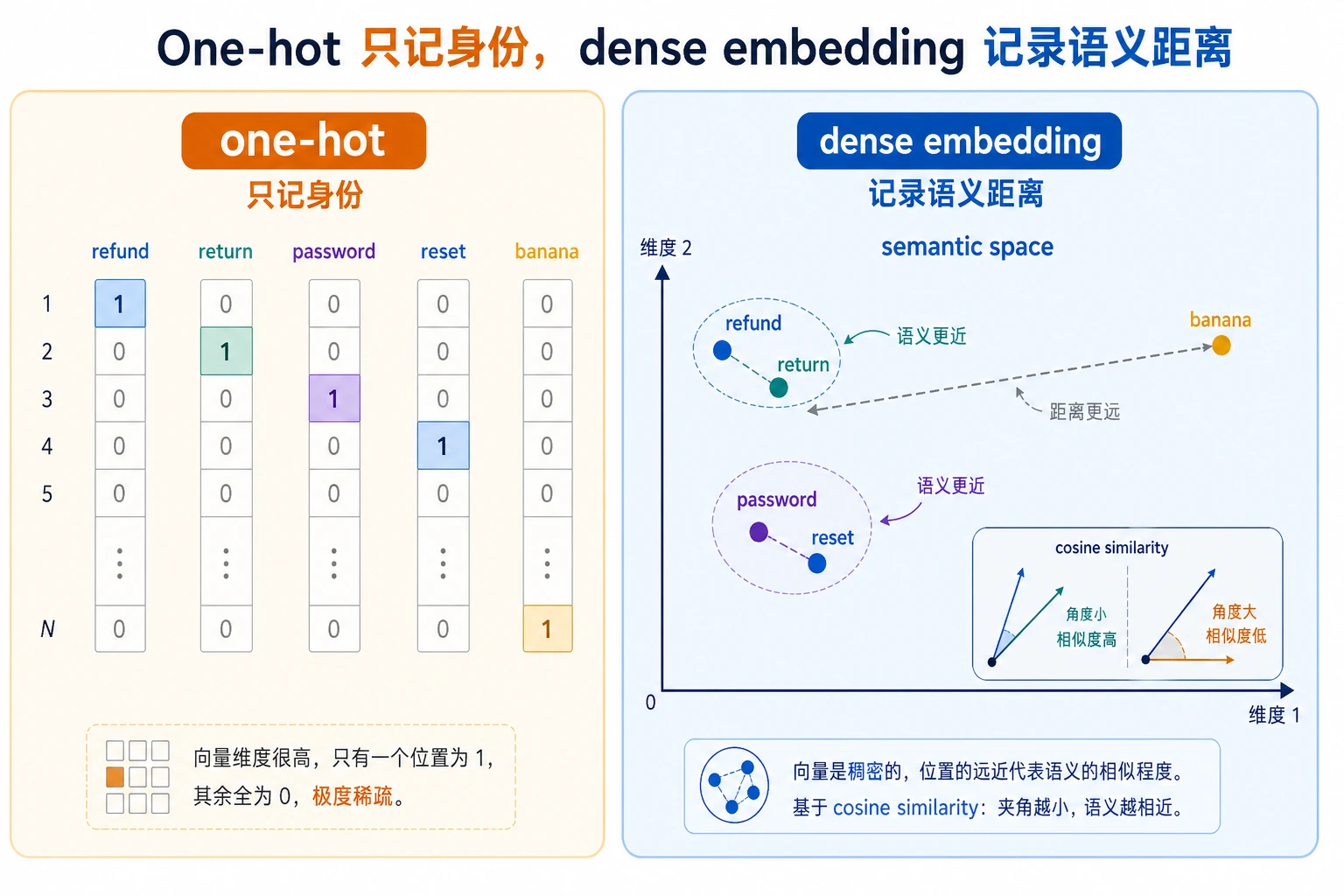
One-hot 向量里,任何不同词都一样“不同”:
refund -> [1, 0, 0, 0]
return -> [0, 1, 0, 0]
password -> [0, 0, 1, 0]
banana -> [0, 0, 0, 1]
稠密向量可以表达更有用的几何关系:
refund and return -> close
password and reset -> close
refund and password -> far
这种几何关系不是手写规则,而是从数据里学出来的。经常出现在相似上下文里的词,向量也倾向于接近。
实验 1:比较词语相似度
先跑这个极小 embedding table。数字是为了教学手写的,但操作和真实向量检索一致。
from math import sqrt
embeddings = {
"refund": [0.90, 0.80, 0.10],
"return": [0.88, 0.78, 0.12],
"password": [0.10, 0.20, 0.95],
"reset": [0.12, 0.18, 0.92],
"order": [0.75, 0.70, 0.15],
"banana": [0.05, 0.95, 0.10],
"policy": [0.82, 0.74, 0.18],
}
def cosine(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = sqrt(sum(x * x for x in a))
norm_b = sqrt(sum(x * x for x in b))
return dot / (norm_a * norm_b)
print("refund vs return :", round(cosine(embeddings["refund"], embeddings["return"]), 3))
print("refund vs password:", round(cosine(embeddings["refund"], embeddings["password"]), 3))
print("password vs reset :", round(cosine(embeddings["password"], embeddings["reset"]), 3))
预期输出:
refund vs return : 1.0
refund vs password: 0.293
password vs reset : 1.0
这样理解:
- cosine 高表示方向相似,不代表含义完全相同;
refund和return接近,是因为这个玩具表把它们放在客服退款区域;password和reset接近,是因为它们属于账号问题区域;refund和password远,是因为意图不同。
实验 2:做一个迷你语义检索器
现在把 token 向量平均成句向量,再按 query 给三条文档排序。
def mean_embedding(tokens):
vectors = [embeddings[token] for token in tokens if token in embeddings]
dim = len(vectors[0])
return [sum(vector[i] for vector in vectors) / len(vectors) for i in range(dim)]
query = mean_embedding(["reset", "password"])
documents = {
"A refund policy": ["refund", "policy"],
"B password reset": ["password", "reset"],
"C banana return": ["banana", "return"],
}
ranked = sorted(
(
(name, cosine(query, mean_embedding(tokens)))
for name, tokens in documents.items()
),
key=lambda item: item[1],
reverse=True,
)
for name, score in ranked:
print(f"{name}: {score:.3f}")
预期输出:
B password reset: 1.000
C banana return: 0.335
A refund policy: 0.333
这就是向量检索的核心:
query text -> query vector -> compare with document vectors -> top-k results
真实 RAG 系统会使用更强的 embedding model 和 vector database,但逻辑仍然是相似度排序。
平均向量有用,但不够强
Mean pooling 很好理解,但会丢掉重要信息:
- 词序;
- 否定;
- 强调;
- 长距离依赖;
- 哪个 token 更关键。
例如玩具检索器会把 reset password 和 password reset 看成完全一样。这对建立直觉可以,但不适合推理要求高的任务。
上下文表示
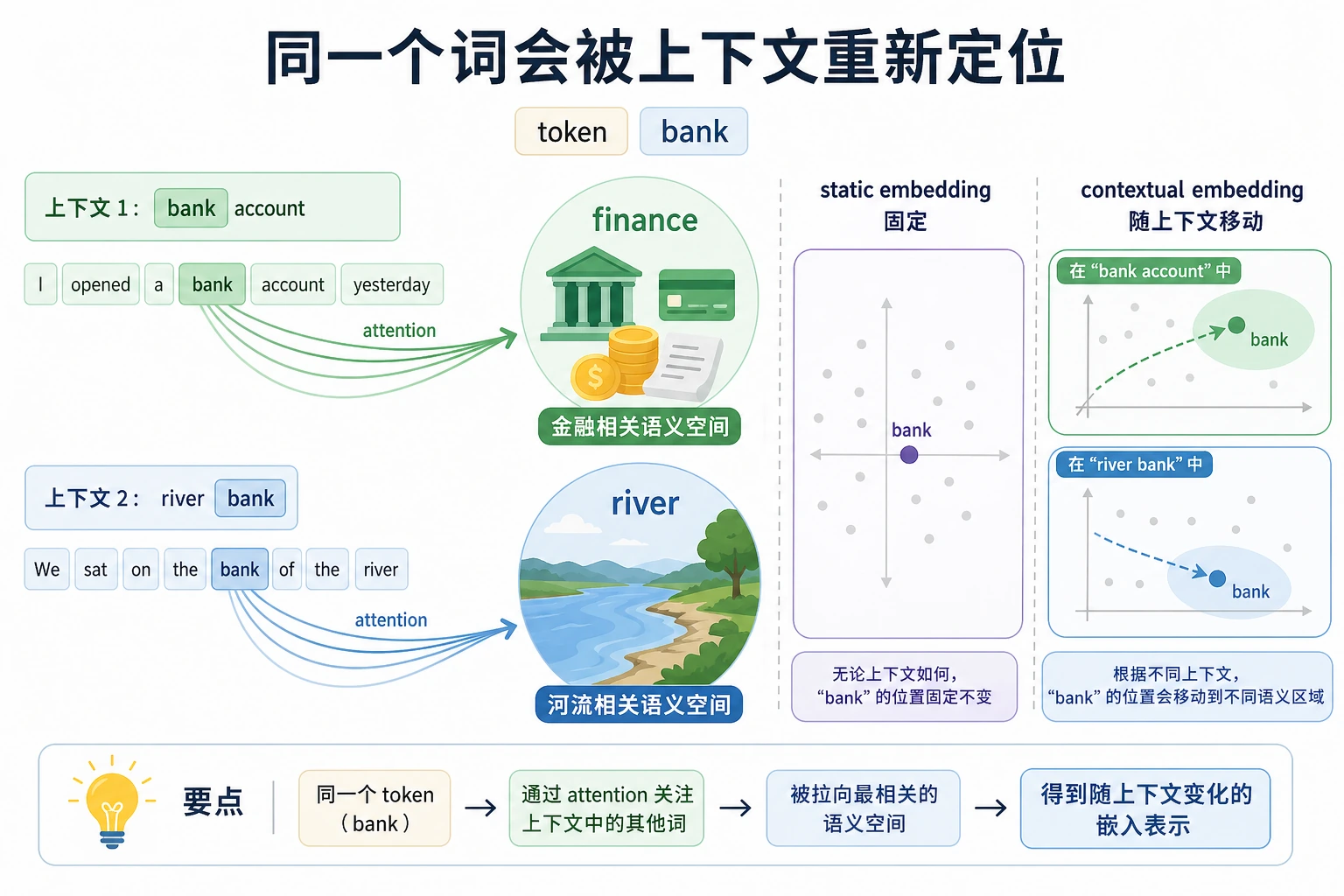
静态 embedding 通常一个词一个向量。上下文模型会让向量受周围词影响:
bank account -> bank 靠近金融语义
river bank -> bank 靠近地理语义
跑一个小模拟:
base_bank = [0.50, 0.50, 0.50]
finance_context = [0.30, -0.10, 0.20]
river_context = [-0.20, 0.25, -0.10]
bank_in_finance = [a + b for a, b in zip(base_bank, finance_context)]
bank_in_river = [a + b for a, b in zip(base_bank, river_context)]
print("bank in finance:", [round(x, 2) for x in bank_in_finance])
print("bank in river :", [round(x, 2) for x in bank_in_river])
预期输出:
bank in finance: [0.8, 0.4, 0.7]
bank in river : [0.3, 0.75, 0.4]

这不是一个真实 Transformer,只是帮助记忆:同一个 token 混入上下文后,可以得到不同表示。
项目里怎么用
| 场景 | embedding 提供什么 | 注意点 |
|---|---|---|
| RAG 检索 | 找到语义相关 chunk | chunk 切得差或 metadata 过期仍会伤害答案 |
| FAQ 聚类 | 合并相似问题 | 接近不一定等于重复 |
| 去重 | 找近似重复内容 | 模板化文本和改写会干扰分数 |
| 分类 | 把文本变成特征 | 标签质量和校准仍然重要 |
| 推荐 | 比较用户、物品或查询 | 热门偏差可能压过语义相似 |
排查清单
- 如果库没有自动处理,先把向量 normalize 再算 cosine。
- 打印 top-k 分数,不只看 top-1;分差小代表检索不确定。
- 检查 false positive:相关词不一定就是正确答案。
- 对同一批数据比较 static、sentence、contextual embedding。
- 多语言项目要先测跨语言样本,不要默认 embedding model 已经对齐语言。
练习
- 把
banana移到更接近password的位置,观察检索如何出错。 - 添加文档
D recover account,并给recover、account设计向量。 - 创建 query
refund order,你认为哪条文档应该排第一? - 用自己的话解释:为什么
doctor和hospital可能接近,但不是同义词? - 在 RAG 项目中,你会收集什么证据证明 embedding model 足够好?
小结
Embedding 把离散 token ID 变成几何关系:
identity -> vector -> distance -> retrieval / clustering / model input
真正重要的不是公式,而是语义变成了可以比较、排序并传入神经网络的东西。