7.1.2 トークン化と Tokenizer
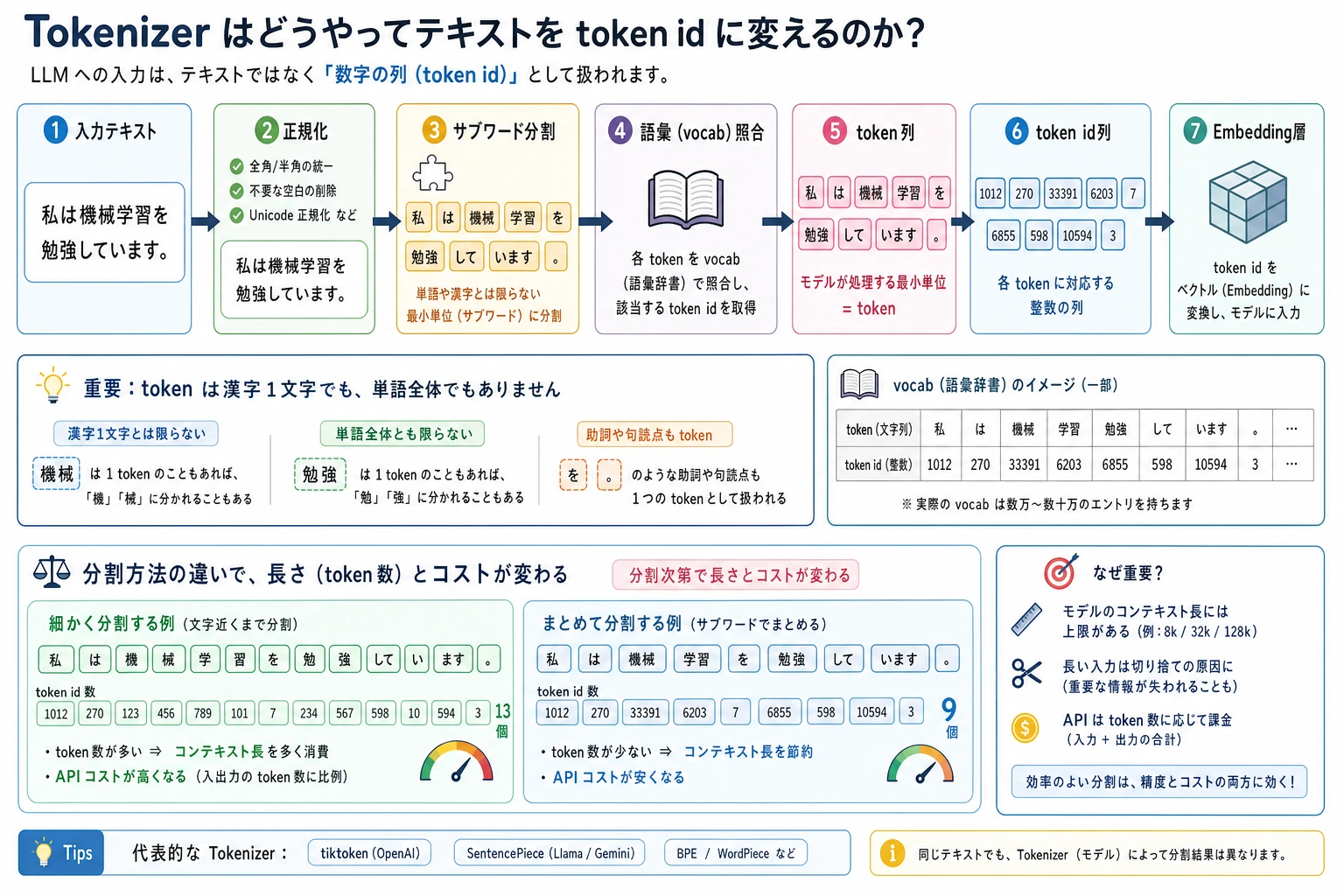
この節の後では、任意の prompt を見て次の 4 点を確認できるようにします。
- この文章はどの tokens に分かれるか。
- モデルが実際に受け取る整数 ID は何か。
- どの位置が本物の内容で、どの位置が padding か。
- この prompt は context window を無駄遣い、または超過していないか。
まずメンタルモデルを作る
ニューラルネットワークは文字列を直接読むわけではありません。受け取るのは tensor です。Tokenizer は、人間の文章とモデル用 tensor の間にある契約です。
raw text -> tokens -> input_ids -> model
大きなモデルの不思議に見える挙動も、この契約を見ると原因が見えやすくなります。
- 1 つの単語が複数 token になることがある。
- 句読点、大文字小文字、中国語、コード、emoji は token 数を大きく変えることがある。
- padding は同じ batch の例を同じ長さにそろえる。
- truncation は長すぎる内容を静かに削る。
- chat template は system、user、assistant の周囲に構造 token を追加する。
分割粒度のトレードオフ
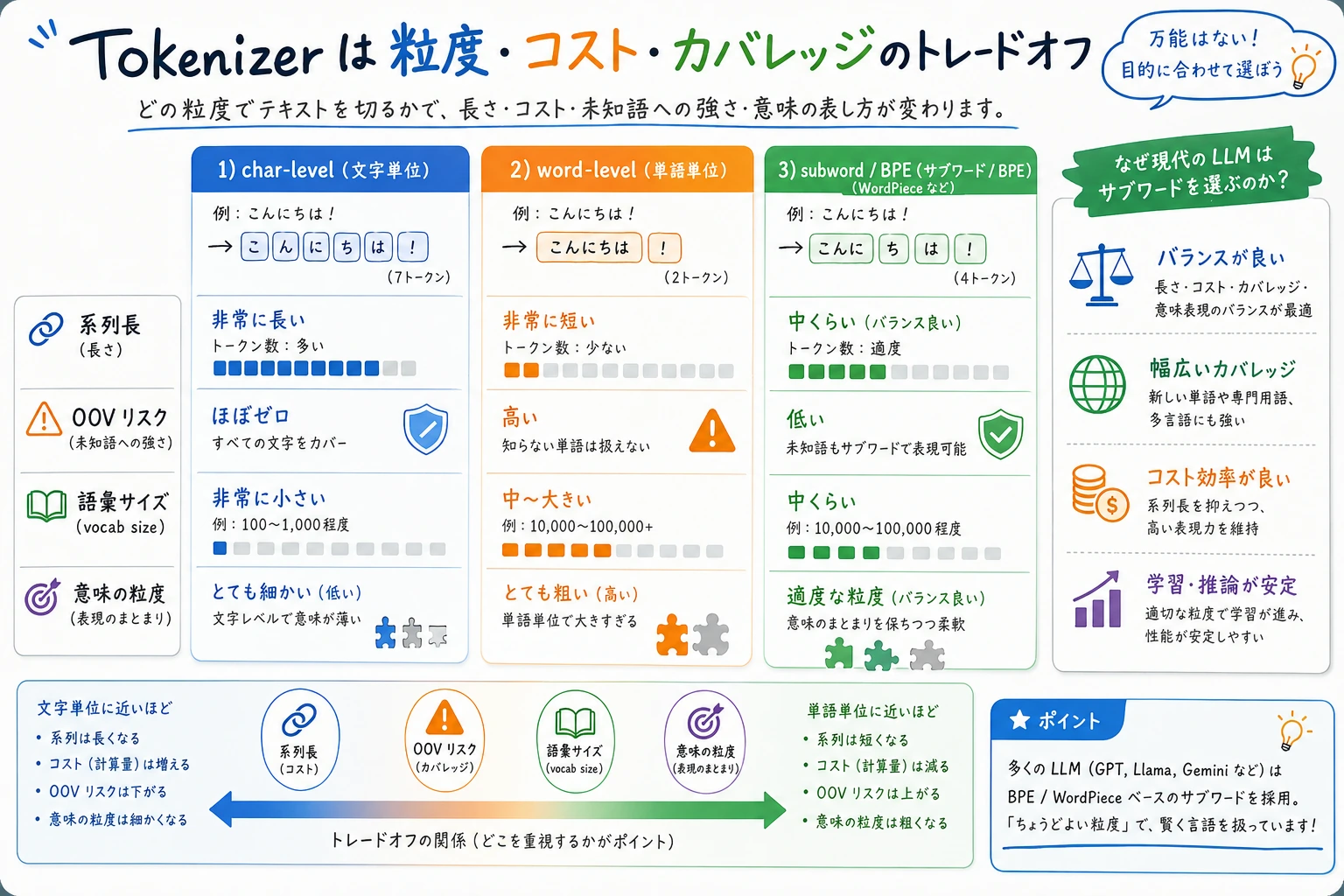
代表的な分け方は 3 つです。
| 方法 | 例 | 強み | 弱み |
|---|---|---|---|
| 文字単位 | r e f u n d | 未知語に強い | 系列が長くなりやすい |
| 単語単位 | refund policy | 意味単位として直感的 | 語彙外の単語が増える |
| サブワード単位 | token ##ization | 実務でバランスがよい | 目で読むと少し分かりにくい |
現代の LLM は多くの場合サブワード tokenization を使います。BPE、WordPiece、SentencePiece は、コーパスから再利用しやすい断片を学ぶ方法です。重要なのは、頻出断片には安定した ID を与え、珍しい単語も小さな断片で表せるようにすることです。
実験 1:小さな WordPiece 風 Tokenizer を作る
まずこれを動かします。小さいので行ごとに追えますが、実際のモデル API に出てくる重要なオブジェクトを含んでいます。
import re
VOCAB = {
"[PAD]": 0,
"[UNK]": 1,
"[CLS]": 2,
"[SEP]": 3,
"refund": 4,
"policy": 5,
"reset": 6,
"password": 7,
"transform": 8,
"##er": 9,
"##s": 10,
"token": 11,
"##ization": 12,
"please": 13,
"help": 14,
"need": 15,
"evidence": 16,
}
def words(text):
return re.findall(r"[A-Za-z]+", text.lower())
def split_wordpiece(word):
if word in VOCAB:
return [word]
pieces = []
start = 0
while start < len(word):
match = None
for end in range(len(word), start, -1):
piece = word[start:end] if start == 0 else "##" + word[start:end]
if piece in VOCAB:
match = piece
break
if match is None:
return ["[UNK]"]
pieces.append(match)
start = end
return pieces
def encode(text, max_length=10):
tokens = ["[CLS]"]
for word in words(text):
tokens.extend(split_wordpiece(word))
tokens.append("[SEP]")
original_len = len(tokens)
if len(tokens) > max_length:
tokens = tokens[:max_length]
tokens[-1] = "[SEP]"
input_ids = [VOCAB.get(token, VOCAB["[UNK]"]) for token in tokens]
attention_mask = [1] * len(input_ids)
while len(input_ids) < max_length:
tokens.append("[PAD]")
input_ids.append(VOCAB["[PAD]"])
attention_mask.append(0)
return {
"text": text,
"original_len": original_len,
"tokens": tokens,
"input_ids": input_ids,
"attention_mask": attention_mask,
}
for example in [
"Please help reset password",
"Transformers refund policy",
"Tokenization needs evidence",
]:
row = encode(example, max_length=10)
print("-" * 64)
print("text:", row["text"])
print("original_len:", row["original_len"])
print("tokens:", row["tokens"])
print("input_ids:", row["input_ids"])
print("attention_mask:", row["attention_mask"])
期待される出力:
----------------------------------------------------------------
text: Please help reset password
original_len: 6
tokens: ['[CLS]', 'please', 'help', 'reset', 'password', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
input_ids: [2, 13, 14, 6, 7, 3, 0, 0, 0, 0]
attention_mask: [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
----------------------------------------------------------------
text: Transformers refund policy
original_len: 7
tokens: ['[CLS]', 'transform', '##er', '##s', 'refund', 'policy', '[SEP]', '[PAD]', '[PAD]', '[PAD]']
input_ids: [2, 8, 9, 10, 4, 5, 3, 0, 0, 0]
attention_mask: [1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
----------------------------------------------------------------
text: Tokenization needs evidence
original_len: 7
tokens: ['[CLS]', 'token', '##ization', 'need', '##s', 'evidence', '[SEP]', '[PAD]', '[PAD]', '[PAD]']
input_ids: [2, 11, 12, 15, 10, 16, 3, 0, 0, 0]
attention_mask: [1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
出力はこう読みます。
[CLS]と[SEP]は構造 token。transformersは語彙に完全形がないためtransform、##er、##sに分かれる。input_idsがモデルに渡る実際の整数。attention_mask=0は[PAD]位置を示し、モデルに無視させる。
実験 2:truncation をプロダクトリスクとして見る
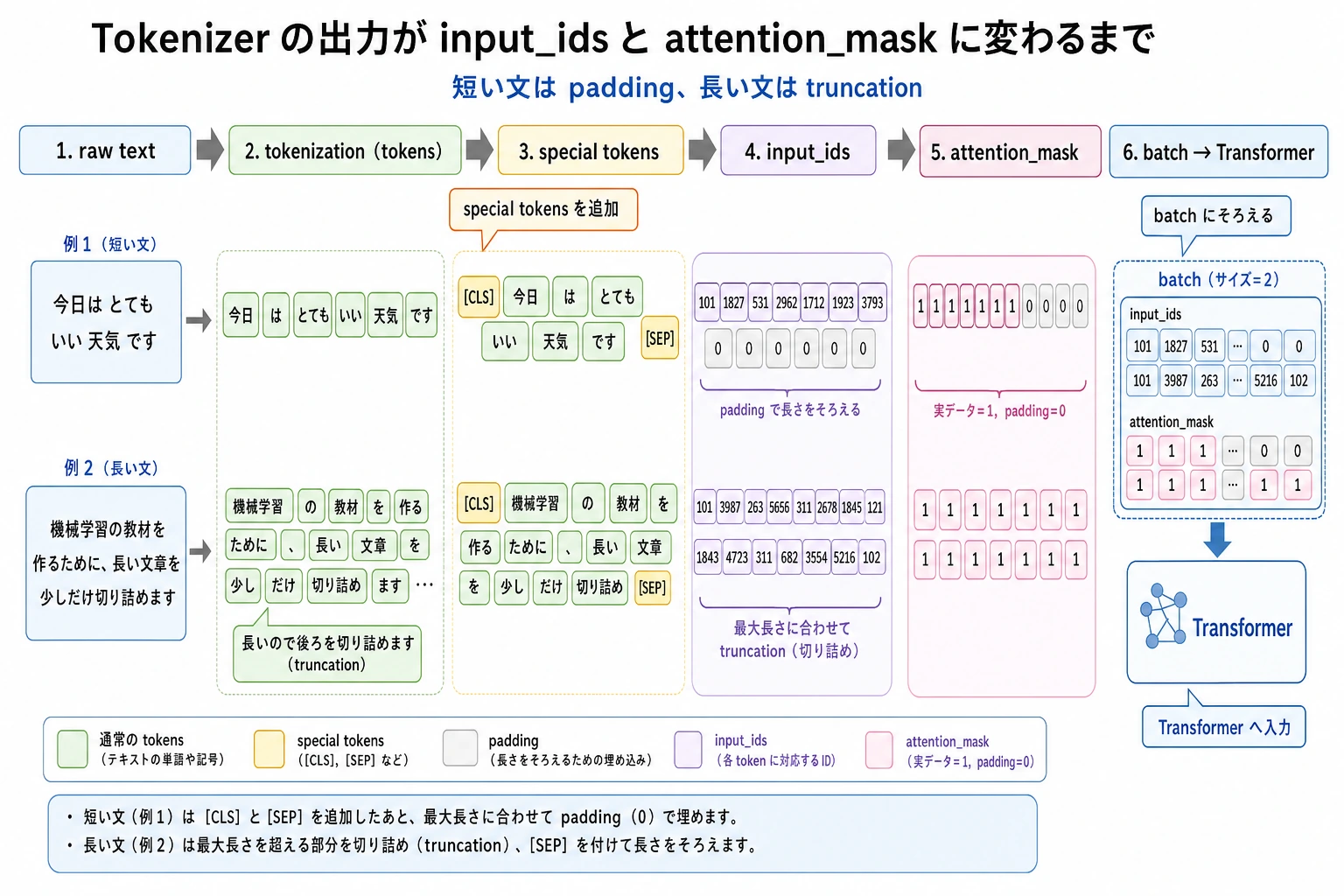
今度は context window をあえて小さくします。
row = encode("Please help reset password refund policy evidence", max_length=6)
print("original_len:", row["original_len"])
print("tokens:", row["tokens"])
print("input_ids:", row["input_ids"])
print("attention_mask:", row["attention_mask"])
期待される出力:
original_len: 9
tokens: ['[CLS]', 'please', 'help', 'reset', 'password', '[SEP]']
input_ids: [2, 13, 14, 6, 7, 3]
attention_mask: [1, 1, 1, 1, 1, 1]
refund policy evidence が消えました。実際のサポート bot では、ここにユーザーの本当の意図が含まれているかもしれません。Tokenizer は小さな前処理ではなく、コスト、検索チャンク長、prompt 設計、失敗モードに直接影響します。
実験 3:本物の Hugging Face Tokenizer を確認する
初回の tokenizer ダウンロードにはネットワークが必要です。
python -m pip install "transformers>=4.0" torch
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
batch = tokenizer(
["Please help reset password", "Tokenization needs evidence"],
padding="max_length",
truncation=True,
max_length=10,
return_tensors="pt",
)
print(batch.keys())
print(batch["input_ids"].shape)
print(tokenizer.convert_ids_to_tokens(batch["input_ids"][1]))
print(batch["attention_mask"][1].tolist())
期待される形状レベルの出力:
dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
torch.Size([2, 10])
['[CLS]', 'token', '##ization', 'needs', 'evidence', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]

正確な分割は tokenizer によって変わります。だからこそ、実際に使うモデルに付属する tokenizer を必ず確認します。
覚えておきたい用語
| 用語 | 実務上の意味 |
|---|---|
vocab | tokenizer 学習で作られた token から ID への辞書 |
| OOV | out-of-vocabulary、語彙外。[UNK] やサブワード合成で扱う |
| BPE | 頻出する文字ペアを結合して再利用可能なサブワードにする |
| WordPiece | 似たサブワード方式。BERT 系 tokenizer でよく見る |
| SentencePiece | テキストを生の文字列として扱う。多言語や空白のない言語に向く |
padding_side | padding を左に足すか右に足すか。decoder モデルでは重要なことがある |
| context length | 入力と生成出力が共有する最大 token 予算 |
| chat template | tokenizer レベルの会話フォーマット。役割 token と境界 token を追加する |
デバッグチェックリスト
Prompt の挙動が変なときは、モデルを疑う前に tokenizer を見ます。
- 完全な prompt の tokens と token IDs を出力する。
- 生のユーザー文ではなく、chat template 適用後の token 数を数える。
- truncation が指示、検索証拠、最新質問を削っていないか確認する。
- decoder モデルを batch 化するときは padding 方向と
attention_maskを確認する。 - 中国語、英語、コード、emoji 入力を比較する。token 数は大きく違うことがある。
練習
VOCABからtransformを削除し、Transformers refund policyがどう変わるか見る。max_lengthを10から5に変え、どの有用 token が先に消えるか確認する。"##ing"を追加し、resetting passwordを表せるか試す。- 実験 3 で別のモデル tokenizer に変え、中国語、英語、コードの token 数を比べる。
- RAG prompt 用に、system 指示、検索証拠、ユーザー質問、回答スペースへ token 予算を割り振る。
まとめ
Tokenizer はただの文字分割ではありません。モデルが見える世界を決めています。
text boundary -> token boundary -> ID sequence -> attention mask -> context budget
この経路を確認できれば、多くの LLM 工程問題はモデル構造を見る前に切り分けられます。