8.5.6 实操:第 8 章 RAG 应用完整工作坊
这个工作坊把第 8 章的主线压缩成一个可以运行的小项目。你不会一开始就接 LangChain、向量数据库或云端 API,而是先用纯 Python 做出一个透明的 RAG 闭环,让新人能看见每一步到底发生了什么。
目标不是在一页里做出最强系统,而是做出一个可以运行、可以检查、可以故意弄坏再修好,并且以后能逐步替换成真实 embedding、向量数据库、模型 API 和部署代码的小系统。
你将做出什么
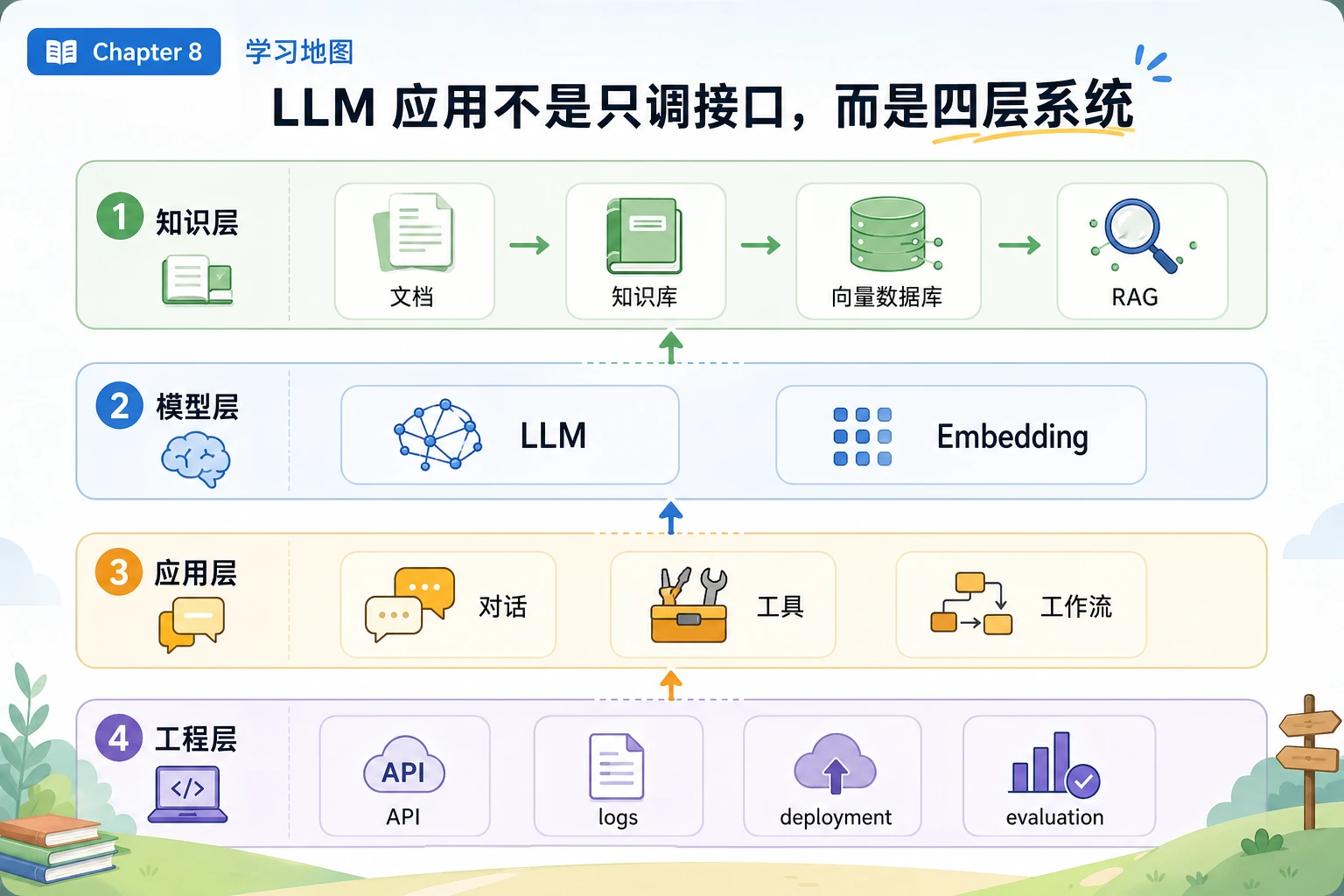
你会做一个小型知识库助手,包含这些能力:
| 能力 | 你要实现什么 | 为什么重要 |
|---|---|---|
| 文档导入 | 用结构化记录保存 4 份小文档 | RAG 必须从可控资料开始 |
| 切块 | 把每份文档切成可检索片段 | 检索通常面对的是片段,不是整座资料库 |
| 元数据 | 保留 source、roles、title、chunk_id | 引用、权限和评估都依赖元数据 |
| 检索 | 用关键词重叠给片段打分 | 新手能看懂为什么命中某个片段 |
| 权限过滤 | 对 public 用户隐藏 employee-only 片段 | 企业 RAG 不能泄露内部知识 |
| 答案生成 | 只基于检索证据回答 | 助手不能编造没有来源的内容 |
| 无答案处理 | 找不到证据时返回明确状态 | 好的 RAG 要敢于说“不知道” |
| 评估 | 跑 3 个固定测试问题 | 优化之前先要有可重复检查 |
请按顺序完成:先看图,复制代码,运行,对比输出,再读解释。不要直接跳到框架代码。框架有用,但要在你理解闭环之后再上。
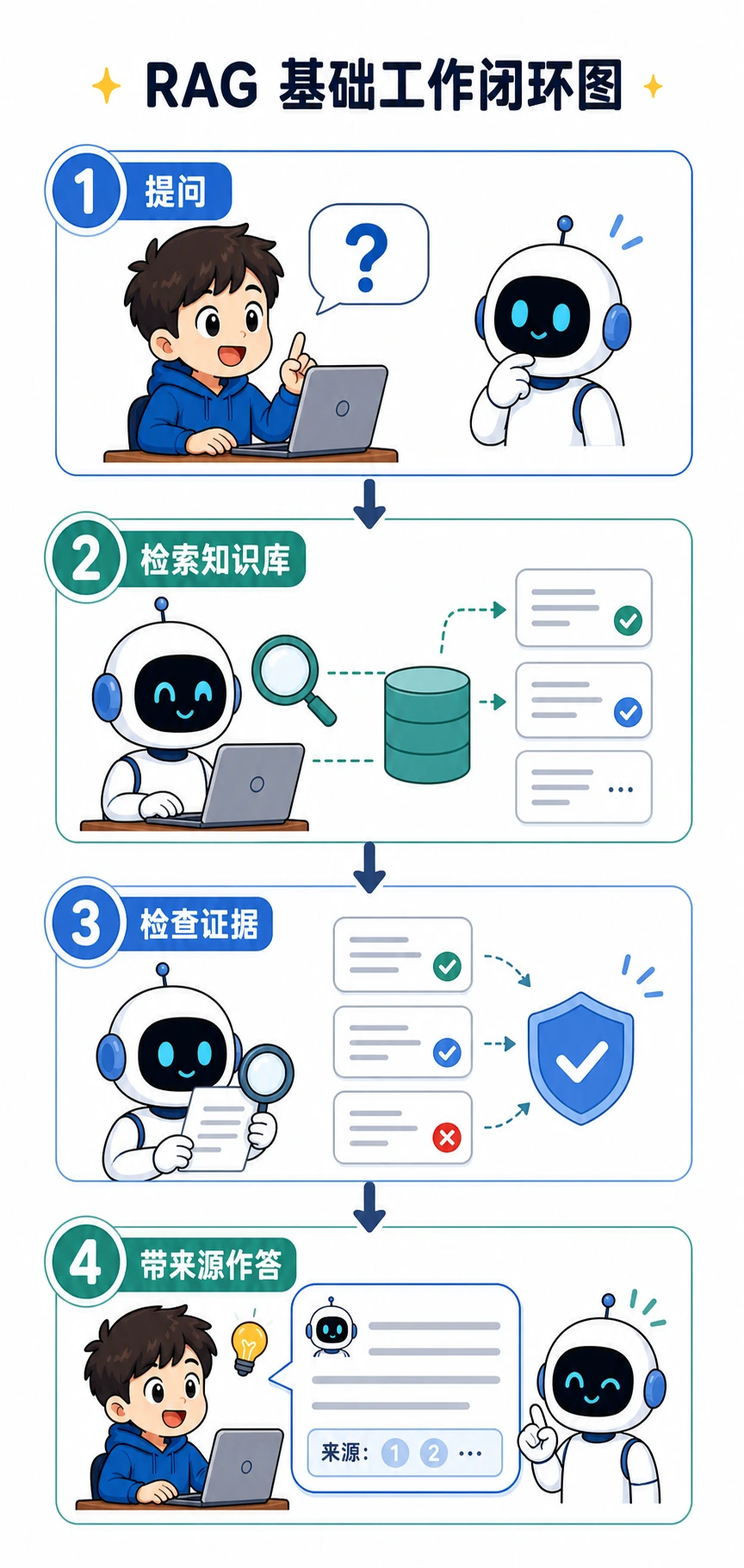
Step 0:写代码前先看懂 RAG 闭环

RAG 是 Retrieval-Augmented Generation,中文常译为“检索增强生成”。说人话就是:
- 用户提出问题。
- 系统检索相关文档片段。
- 系统把这些片段交给模型。
- 模型基于片段回答。
- 最终答案带引用,方便人检查来源。
新人最重要的观念是:如果最终答案错了,不要第一时间怪模型。先把检索到的片段打印出来。如果检索本身错了,生成阶段很难稳定救回来。
Step 1:创建一个小项目目录
打开终端运行:
mkdir ch08_rag_workshop
cd ch08_rag_workshop
touch rag_app_workshop.py
你只需要 Python 3.10 或更新版本。第一个脚本只使用 Python 标准库。
Step 2:复制完整离线 RAG 脚本
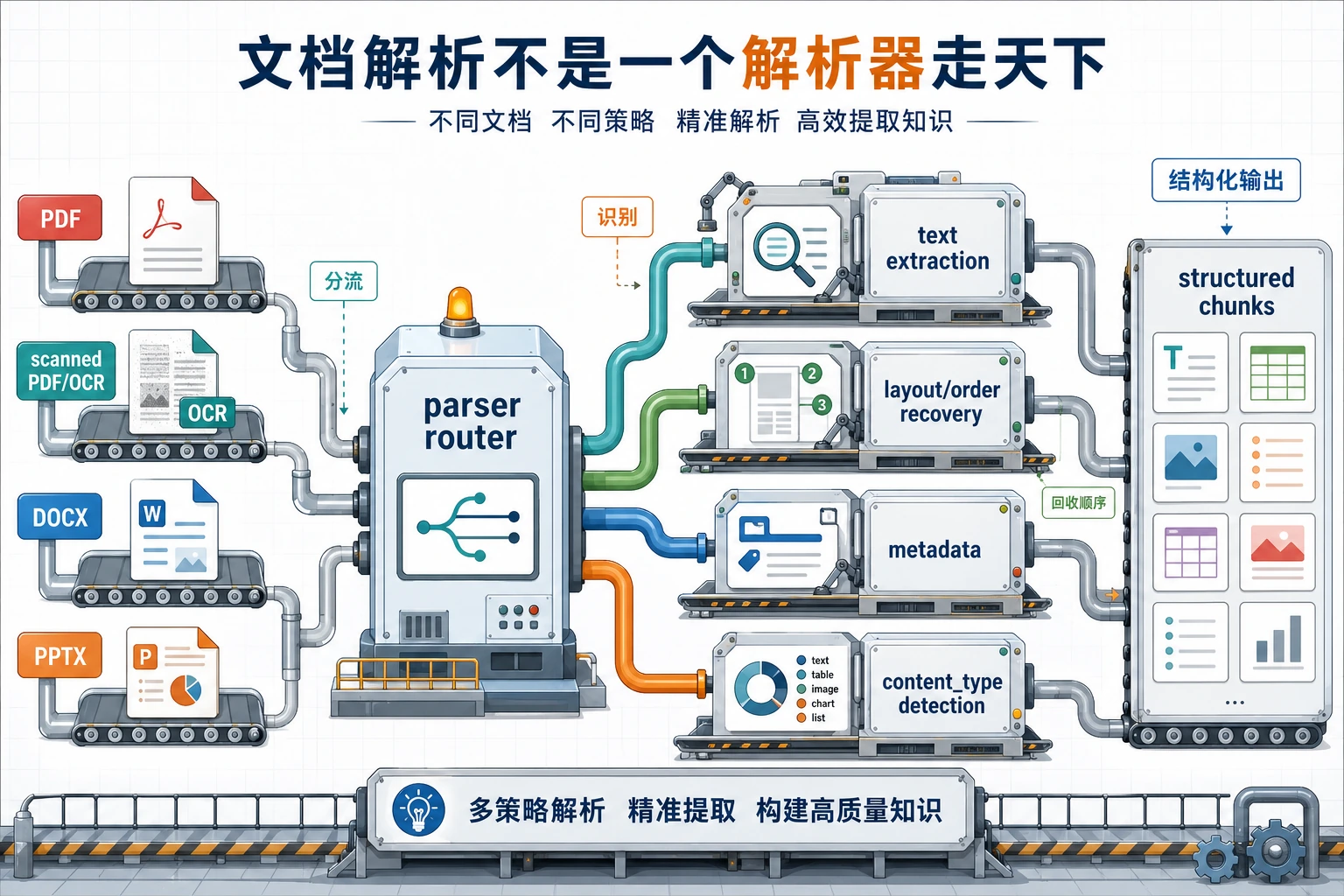
真实项目里的文档可能来自 Markdown、PDF、Word、PPT、HTML 或数据库。这个入门工作坊先用 4 份内存文档,让你看清主流程。每份文档已经带有元数据,因为后面的引用、日志、权限检查和评估都会依赖它。
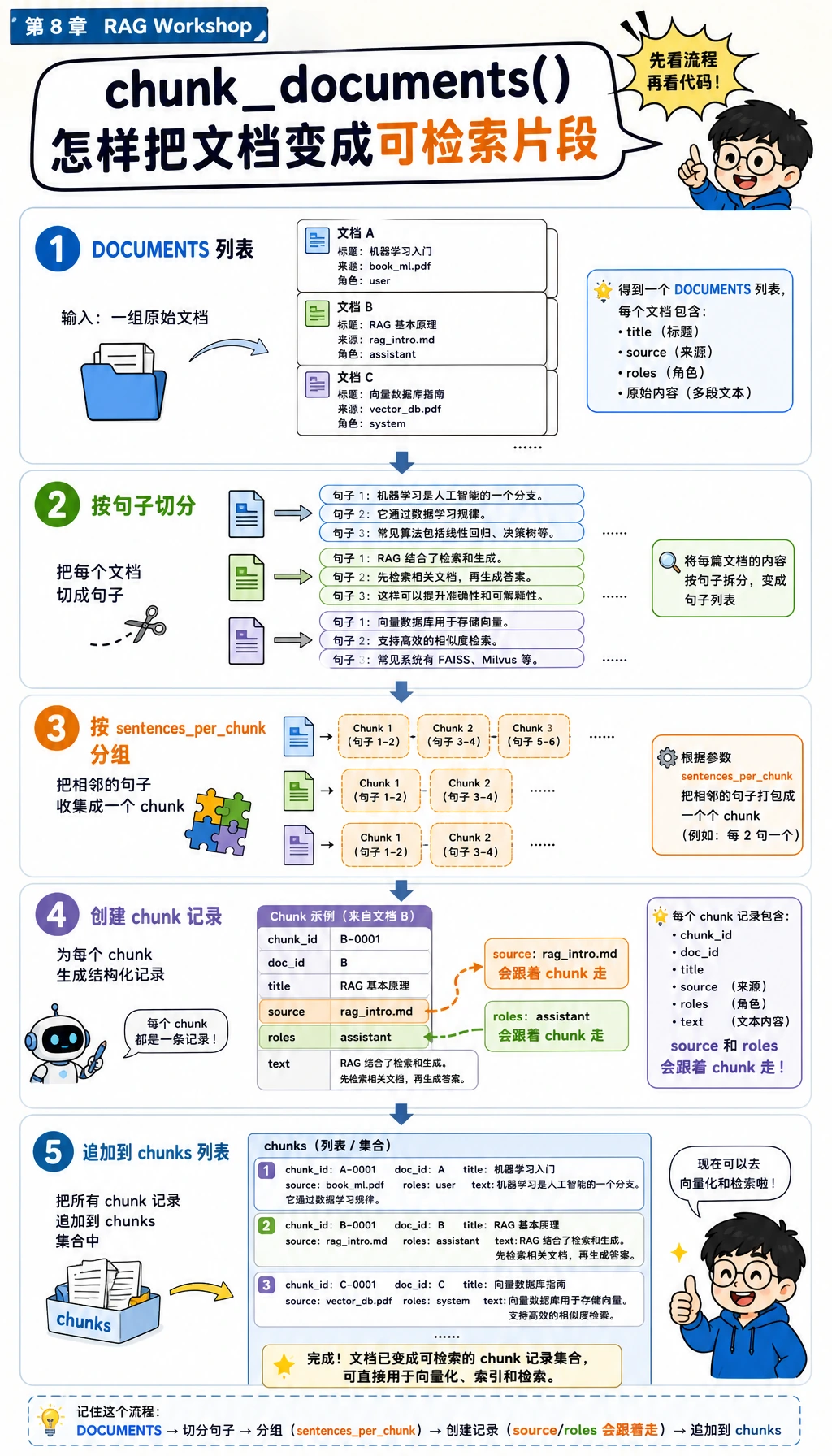
复制完整脚本前,先用下一张图只盯住 chunk_documents()。等会读代码时,视线从 DOCUMENTS 移到 sentences,再移到每条 chunk 记录。关键习惯是:source 和 roles 要跟着每个 chunk 一起走,后面检索和权限检查才安全。
把下面代码复制到 rag_app_workshop.py:
import re
from collections import Counter
DOCUMENTS = [
{
"doc_id": "refund-policy",
"title": "Course refund policy",
"source": "handbook.md#refund",
"roles": ["public"],
"text": (
"Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course. "
"Approved refunds are returned to the original payment method within 5 business days."
),
},
{
"doc_id": "api-key-setup",
"title": "API key setup guide",
"source": "setup.md#keys",
"roles": ["public"],
"text": (
"Store the API key in an environment variable named OPENAI_API_KEY before running the application. "
"Never paste production keys into Markdown files, browser screenshots, or public issue trackers."
),
},
{
"doc_id": "office-hours",
"title": "Course support hours",
"source": "support.md#hours",
"roles": ["public"],
"text": (
"Live office hours happen every Wednesday at 19:00 Taipei time. "
"Learners should bring the question, the command they ran, and the exact error output."
),
},
{
"doc_id": "private-roadmap",
"title": "Private product roadmap",
"source": "internal.md#roadmap",
"roles": ["employee"],
"text": (
"The beta roadmap targets a private release in Q4 after security review is complete. "
"Only employees may view roadmap dates before the public announcement."
),
},
]
STOPWORDS = {
"a", "an", "and", "are", "as", "at", "be", "before", "by", "do", "does",
"for", "from", "has", "have", "how", "in", "is", "it", "of", "on", "or",
"should", "the", "they", "to", "what", "when", "where", "which", "with",
}
def normalize(text):
tokens = []
for token in re.findall(r"[a-z0-9]+", text.lower()):
if len(token) > 3 and token.endswith("s"):
token = token[:-1]
if token not in STOPWORDS:
tokens.append(token)
return tokens
def chunk_documents(documents, sentences_per_chunk=2):
chunks = []
for doc in documents:
sentences = [s.strip() for s in re.split(r"(?<=[.!?])\s+", doc["text"]) if s.strip()]
for start in range(0, len(sentences), sentences_per_chunk):
chunk_text = " ".join(sentences[start : start + sentences_per_chunk])
chunks.append(
{
"chunk_id": f"{doc['doc_id']}#{start // sentences_per_chunk + 1}",
"doc_id": doc["doc_id"],
"title": doc["title"],
"source": doc["source"],
"roles": doc["roles"],
"text": chunk_text,
}
)
return chunks
def keyword_score(query, chunk):
query_terms = set(normalize(query))
chunk_terms = Counter(normalize(chunk["title"] + " " + chunk["text"]))
return sum(chunk_terms[term] for term in query_terms)
def retrieve(query, chunks, role="public", top_k=2):
allowed_hits = []
blocked_hits = []
for chunk in chunks:
score = keyword_score(query, chunk)
if score == 0:
continue
hit = {**chunk, "score": score}
if "public" in chunk["roles"] or role in chunk["roles"]:
allowed_hits.append(hit)
else:
blocked_hits.append(hit)
allowed_hits.sort(key=lambda hit: (-hit["score"], hit["chunk_id"]))
blocked_hits.sort(key=lambda hit: (-hit["score"], hit["chunk_id"]))
return {"hits": allowed_hits[:top_k], "blocked": blocked_hits[:top_k]}
def build_answer(query, retrieval):
hits = retrieval["hits"]
if not hits:
status = "blocked_by_permission" if retrieval["blocked"] else "no_evidence"
return {
"status": status,
"answer": "I do not have enough permitted evidence to answer this question.",
"citations": [],
}
top = hits[0]
first_sentence = re.split(r"(?<=[.!?])\s+", top["text"])[0]
return {
"status": "answered",
"answer": f"Based on {top['source']}: {first_sentence}",
"citations": [top["source"]],
}
def rag_answer(query, chunks, role="public"):
retrieval = retrieve(query, chunks, role=role, top_k=2)
answer = build_answer(query, retrieval)
return {"query": query, "role": role, "retrieval": retrieval, **answer}
EVAL_CASES = [
{
"name": "refund_window",
"question": "How many days do learners have for refunds?",
"role": "public",
"expected_status": "answered",
"expected_source": "handbook.md#refund",
},
{
"name": "api_key_setup",
"question": "Where should I store the API key?",
"role": "public",
"expected_status": "answered",
"expected_source": "setup.md#keys",
},
{
"name": "private_block",
"question": "What is the private beta roadmap for Q4?",
"role": "public",
"expected_status": "blocked_by_permission",
"expected_source": None,
},
]
def evaluate(chunks):
rows = []
passed = 0
for case in EVAL_CASES:
result = rag_answer(case["question"], chunks, role=case["role"])
status_ok = result["status"] == case["expected_status"]
citation_ok = case["expected_source"] is None or case["expected_source"] in result["citations"]
ok = status_ok and citation_ok
passed += int(ok)
rows.append({"name": case["name"], "ok": ok, "status": result["status"], "citations": result["citations"]})
return passed, rows
def main():
chunks = chunk_documents(DOCUMENTS)
print("STEP 1: parse and chunk documents")
print(f"chunks: {len(chunks)}")
print(f"first_chunk: {chunks[0]['chunk_id']} -> {chunks[0]['title']}")
print()
print("STEP 2: answer with citations")
result = rag_answer("How many days do learners have for refunds?", chunks)
print(f"question: {result['query']}")
print(f"status: {result['status']}")
print(f"answer: {result['answer']}")
print(f"citations: {', '.join(result['citations'])}")
print()
print("STEP 3: permission and no-evidence checks")
private_result = rag_answer("What is the private beta roadmap for Q4?", chunks, role="public")
unknown_result = rag_answer("What is the cafeteria menu today?", chunks, role="public")
print(f"private_question_as_public: {private_result['status']}")
print(f"unknown_question: {unknown_result['status']}")
print()
print("STEP 4: mini evaluation")
passed, rows = evaluate(chunks)
for row in rows:
mark = "PASS" if row["ok"] else "FAIL"
citations = ", ".join(row["citations"]) if row["citations"] else "none"
print(f"{row['name']}: {mark} ({row['status']}, {citations})")
print(f"passed: {passed}/{len(rows)}")
if __name__ == "__main__":
main()
Step 3:运行并对比输出
运行:
python3 rag_app_workshop.py
预期输出:
STEP 1: parse and chunk documents
chunks: 4
first_chunk: refund-policy#1 -> Course refund policy
STEP 2: answer with citations
question: How many days do learners have for refunds?
status: answered
answer: Based on handbook.md#refund: Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course.
citations: handbook.md#refund
STEP 3: permission and no-evidence checks
private_question_as_public: blocked_by_permission
unknown_question: no_evidence
STEP 4: mini evaluation
refund_window: PASS (answered, handbook.md#refund)
api_key_setup: PASS (answered, setup.md#keys)
private_block: PASS (blocked_by_permission, none)
passed: 3/3
如果你的输出一致,说明你已经跑通第 8 章最小闭环:资料进入系统,生成 chunk,执行检索,完成权限过滤,给出带引用答案,并用评估样例验证行为。
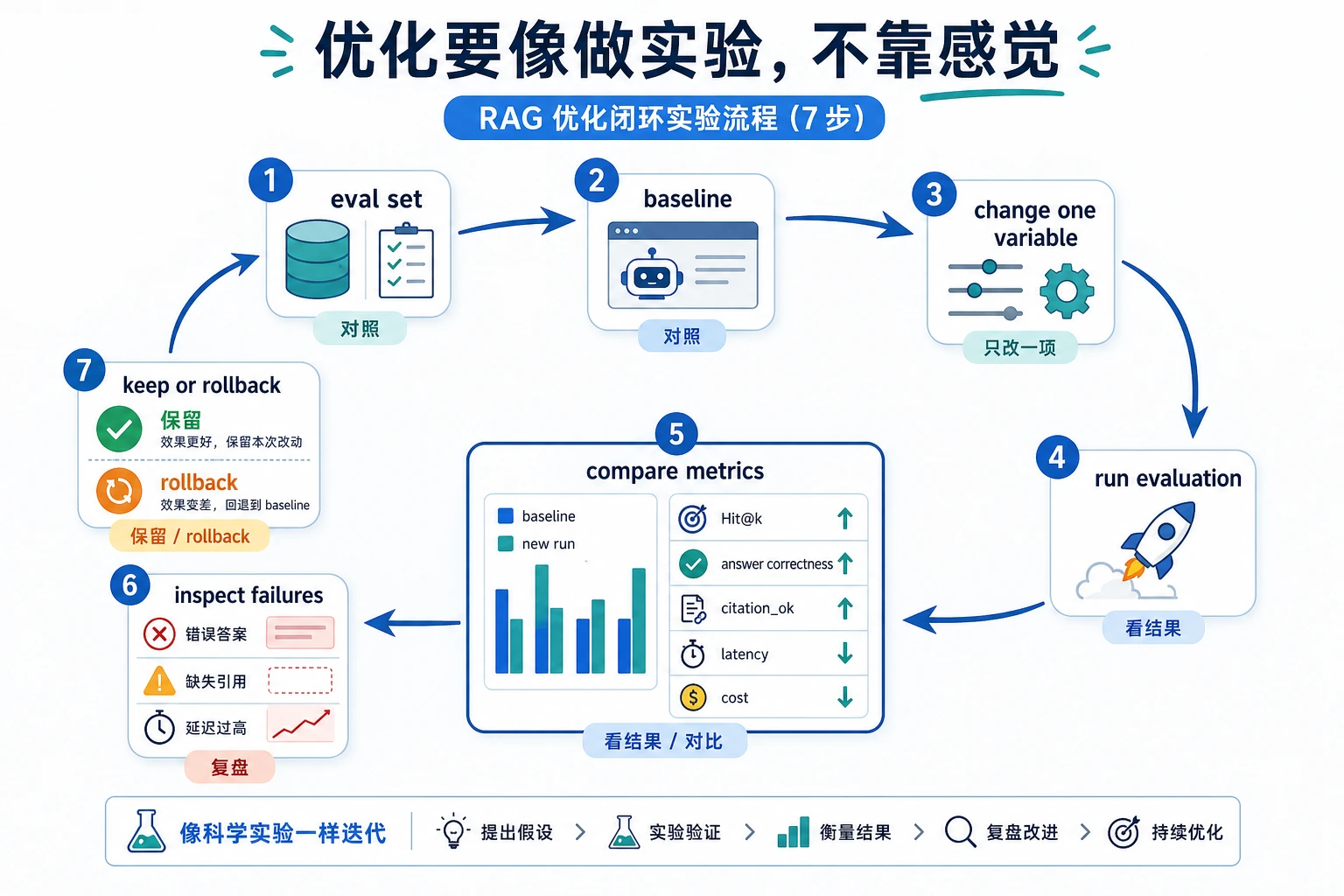
请用这张图读评估部分。evaluate() 不是靠感觉判断答案好坏,而是逐条运行 EVAL_CASES,检查 status,检查 citations,再统计 PASS/FAIL。注意 private_block 没有 citation 也可以 PASS,因为预期行为就是 blocked_by_permission。

Step 4:像看流水线一样读代码
请按这个顺序读脚本:
| 代码位置 | 要看什么 | 新手解释 |
|---|---|---|
DOCUMENTS | doc_id、source、roles、text | 这是你的小知识库 |
chunk_documents() | 文档怎样变成 chunk 记录 | chunk 是后续检索的单位 |
normalize() | 文本怎样变成可比较 token | 检索需要统一的匹配形式 |
keyword_score() | 片段怎样得到分数 | 分数越高,说明命中的查询词越多 |
retrieve() | 允许命中和被权限挡住的命中 | 检索质量和权限安全要分开看 |
build_answer() | 怎样处理无答案和引用 | 系统不能输出没有来源的答案 |
EVAL_CASES | 固定问题和预期行为 | 评估把“看起来还行”变成可重复检查 |
现在的检索算法故意很简单。它不是 embedding 的替代品,而是教学用的可见打分器。以后你把 keyword_score() 替换成 embedding 或混合检索时,外围的 RAG 结构仍然很相似。
Step 5:观察权限和引用行为

现在把视角放大到 retrieve() 里的分支判断。命中关键词的 chunk 还不能自动成为证据,它必须先通过角色检查。如果命中了但当前用户无权访问,它会进入 blocked_hits,而不是进入 answer context。
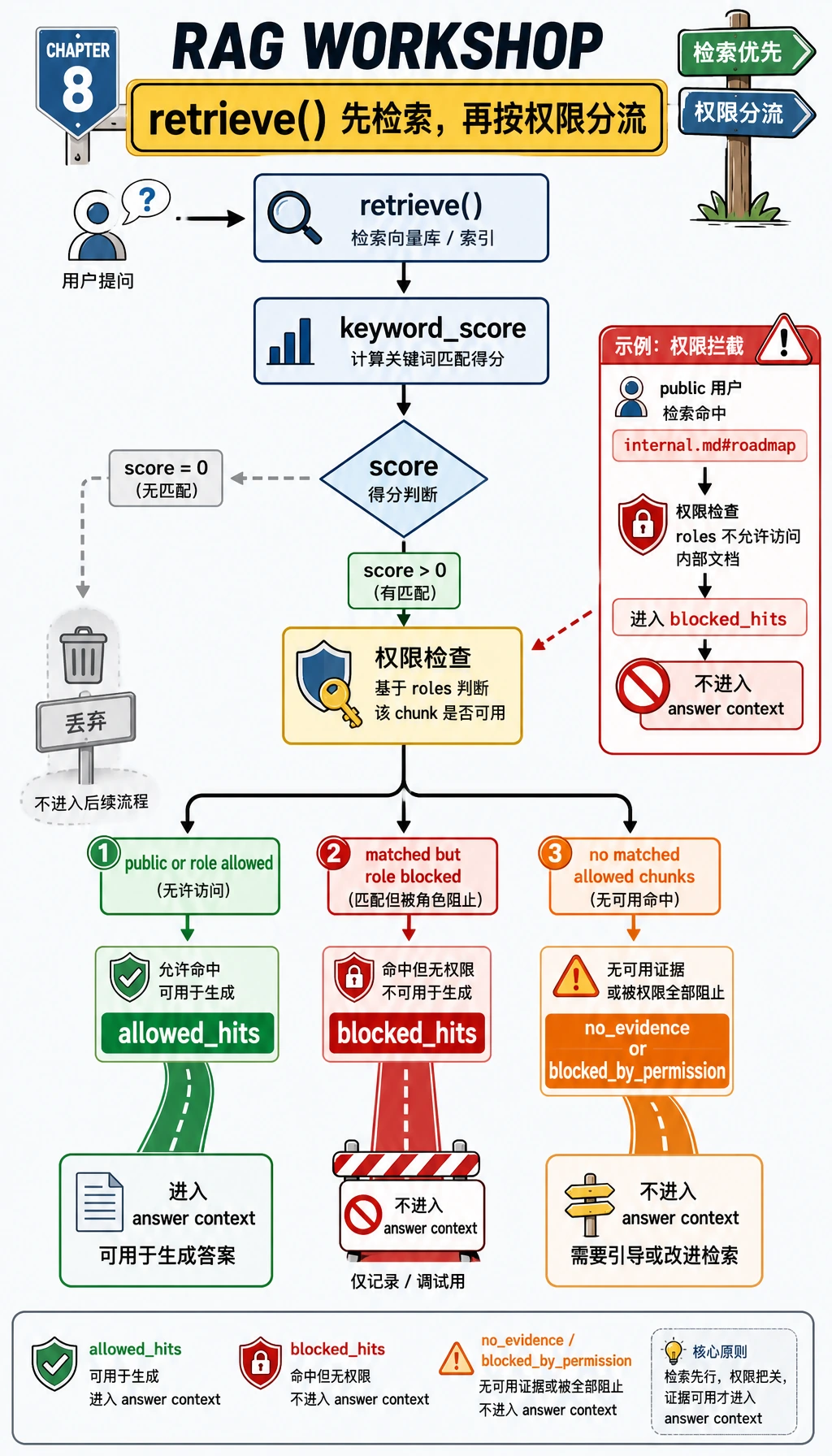
看这份文档:
{
"doc_id": "private-roadmap",
"source": "internal.md#roadmap",
"roles": ["employee"],
"text": "The beta roadmap targets a private release in Q4 ..."
}
public 用户问:
What is the private beta roadmap for Q4?
关键词检索其实能找到匹配的内部片段,但 retrieve() 会把它放进 blocked_hits,而不是 allowed_hits。所以输出是:
private_question_as_public: blocked_by_permission
真实项目里这点很重要。no_evidence 表示系统没有找到可用证据;blocked_by_permission 表示证据可能存在,但当前用户不能看。这两个状态应该用不同方式记录日志。
Step 6:加框架前,先建立 trace 思维
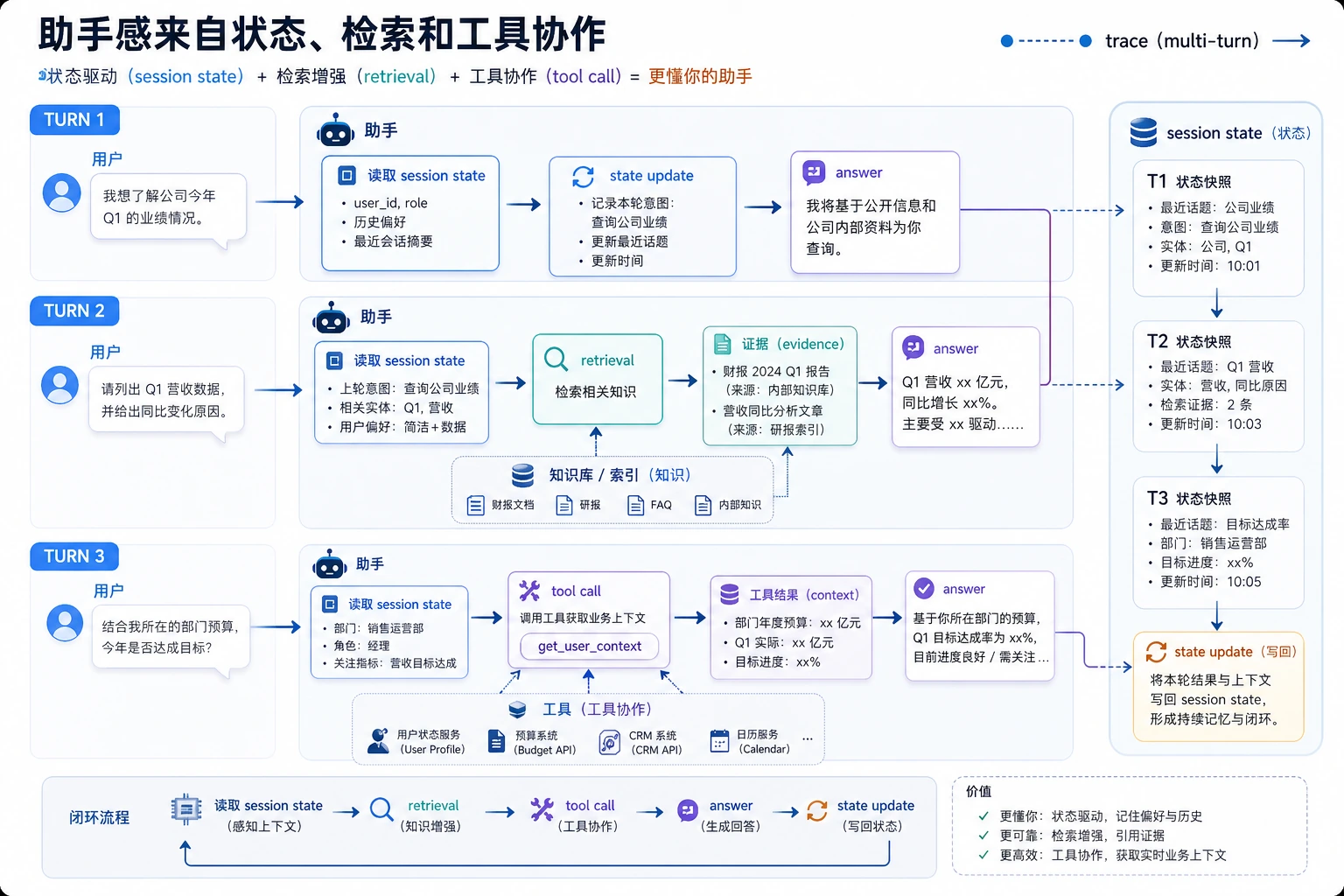
真实 LLM 应用里,trace 是一次请求的过程记录。即使你还没有写日志文件,也应该能解释这条链路:
| Trace 阶段 | 本脚本对应位置 | 以后要记录什么 |
|---|---|---|
| Input | query、role | 用户 ID、会话 ID、请求 ID |
| Parse | chunk_documents() | 文档版本、解析器名称 |
| Retrieve | retrieve() | top-k 片段、分数、查询改写 |
| Permission | allowed_hits、blocked_hits | 角色、权限策略、被挡来源数量 |
| Answer | build_answer() | 状态、引用、模型名称 |
| Evaluate | evaluate() | 通过/失败、失败原因 |
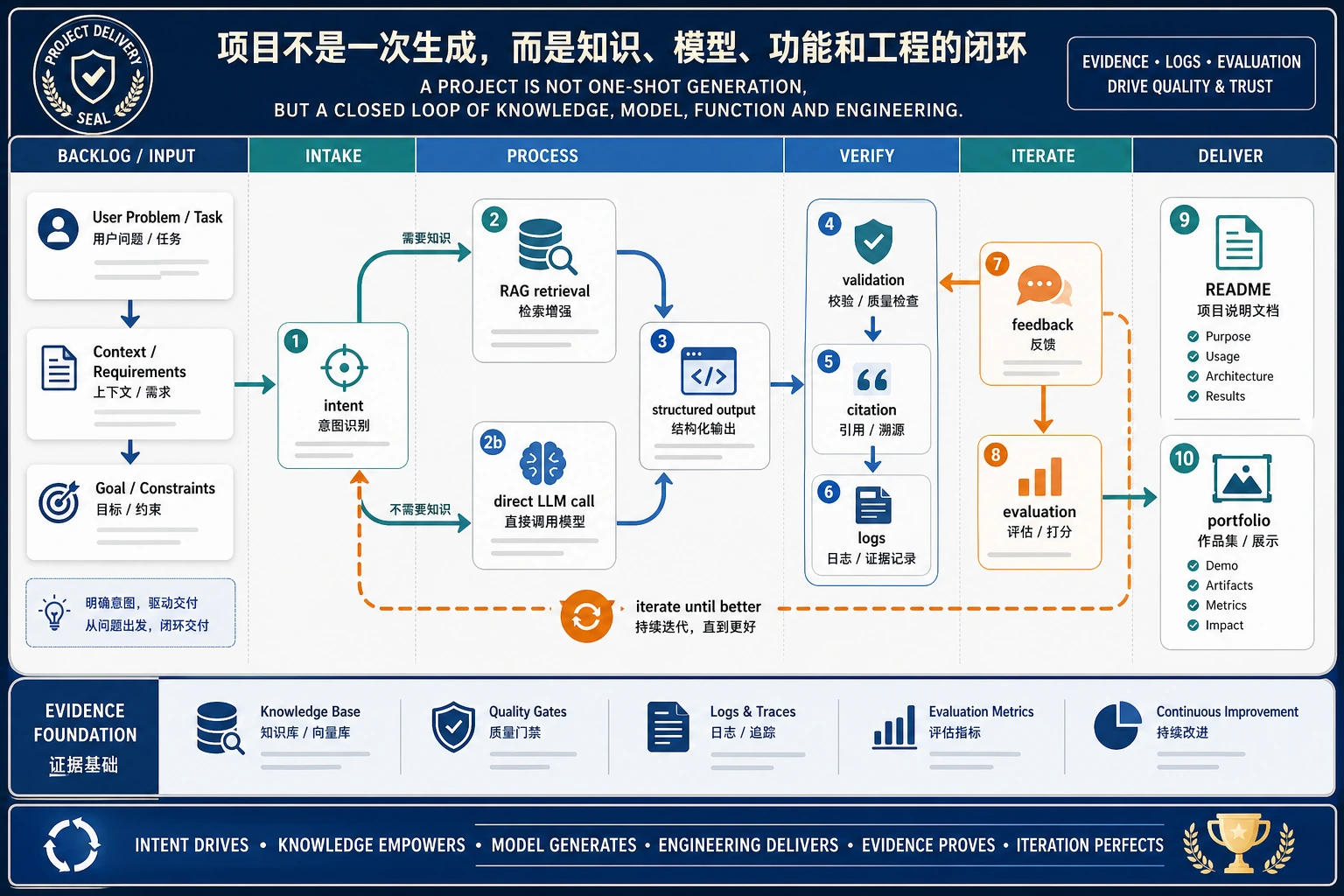
这就是为什么第 8 章是应用工程,而不只是提示词。可靠系统要能看到中间状态。
Step 7:升级到 embedding、向量数据库和 API 的路线

离线脚本跑通之后,一次只替换一个部分:
| 当前简单部分 | 以后生产部分 | 要保留的习惯 |
|---|---|---|
内存里的 DOCUMENTS | Markdown/PDF/Word 解析器加存储 | 保留来源元数据 |
| 按句子切块 | 按标题或 token 切块 | 保持 chunk ID 稳定 |
keyword_score() | embedding、混合检索或重排 | 打印 top-k 和分数 |
roles 列表 | 真实认证和授权 | 回答前先过滤 |
| 抽取式回答 | 带 grounded prompt 的模型调用 | 强制要求引用 |
EVAL_CASES | 更大的评估集和回归检查 | 改动后使用同一组问题 |
不要一次替换所有东西。如果你在同一次改动里同时换了解析、embedding、向量库、prompt 和模型,就很难判断效果变好或变差到底是谁造成的。
Step 8:可选 OpenAI Responses API 升级
离线脚本是必做的新手路径。它跑通以后,可以把 build_answer() 替换成真实模型调用。当前 OpenAI 文档建议使用 Responses API;模型页面目前把复杂推理和编码类任务的默认起点指向 gpt-5.5。请把模型名做成可配置,这样以后可以切到更便宜或课程统一指定的模型。
安装依赖:
python3 -m venv .venv
source .venv/bin/activate
pip install "openai>=2" "pydantic>=2"
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_MODEL="gpt-5.5"
创建 ask_with_openai.py:
import json
import os
from openai import OpenAI
client = OpenAI()
query = "How many days do learners have for refunds?"
context = [
{
"source": "handbook.md#refund",
"text": "Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course.",
}
]
response = client.responses.create(
model=os.getenv("OPENAI_MODEL", "gpt-5.5"),
input=[
{
"role": "system",
"content": (
"Answer only from the provided context. "
"If the context is insufficient, return status no_evidence. "
"Always include citations from the source fields."
),
},
{
"role": "user",
"content": json.dumps({"question": query, "context": context}, ensure_ascii=False),
},
],
text={
"format": {
"type": "json_schema",
"name": "rag_answer",
"strict": True,
"schema": {
"type": "object",
"additionalProperties": False,
"properties": {
"status": {"type": "string", "enum": ["answered", "no_evidence"]},
"answer": {"type": "string"},
"citations": {"type": "array", "items": {"type": "string"}},
},
"required": ["status", "answer", "citations"],
},
}
},
)
print(response.output_text)
运行:
python3 ask_with_openai.py
预期形状:
{"status":"answered","answer":"Refund requests are accepted within 14 days of enrollment when the learner has completed less than 20 percent of the course.","citations":["handbook.md#refund"]}
如果模型返回没有引用的文本,要把它当作检查失败。生产项目里应该校验输出、用更严格指令重试,或者返回可控错误,而不是把无来源答案直接展示给用户。
Step 9:Function Calling 与结构化输出的心智模型
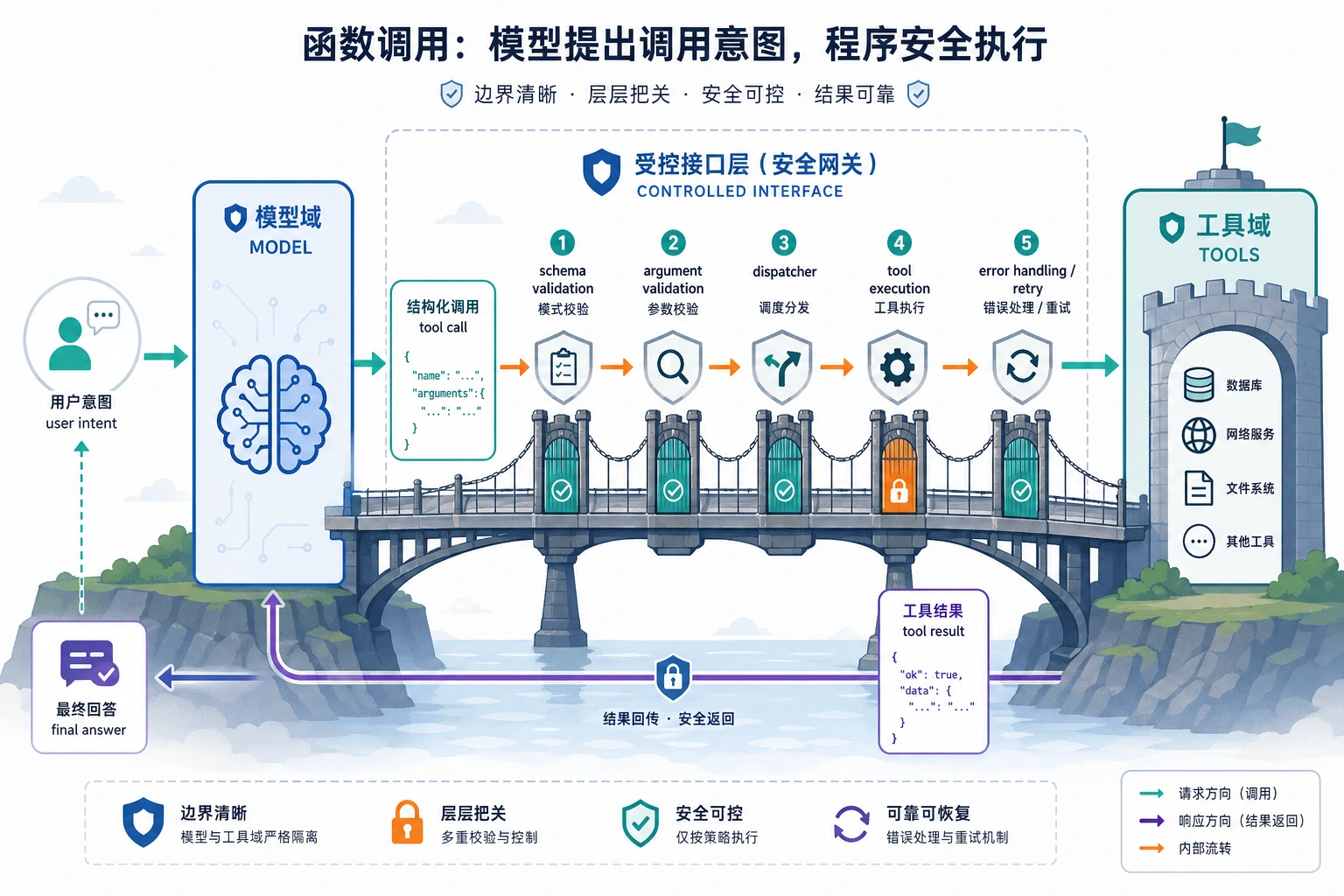
在这个工作坊里,retrieve() 是普通 Python 函数。在模型驱动的应用里,模型可能会决定调用 search_knowledge_base、get_user_profile 或 create_ticket 等工具。
安全模式是:
| 阶段 | 发生什么 | 安全点 |
|---|---|---|
| Schema | 定义工具输入字段 | 拒绝缺失字段和未知字段 |
| Validation | 检查角色、来源和允许动作 | 不要盲信模型给出的参数 |
| Dispatch | 执行真正的函数 | 控制副作用 |
| Observation | 把结果返回给模型 | 先过滤私有数据 |
| Final answer | 带引用回答或返回无答案状态 | 展示前再校验 |
离线脚本已经在训练同一个习惯:检索、权限、回答和评估必须分步骤处理。
Step 10:常见错误排查清单

| 现象 | 可能原因 | 先检查什么 | 修复方向 |
|---|---|---|---|
chunks: 0 | 文档没有正确解析 | 打印 DOCUMENTS 和句子切分结果 | 修输入文本或解析器 |
| 原文有答案但检索不到 | 查询词和 chunk 词不匹配 | 打印 normalize(query) 和 chunk token | 加同义词、embedding 或查询改写 |
| 答案没有引用 | 来源元数据丢了 | 检查 chunk 记录 | 每个 chunk 都保留 source |
| public 答案出现内部资料 | 权限过滤放在生成之后 | 检查 retrieve() 顺序 | 回答前先过滤 |
| 未知问题得到自信答案 | 缺少无答案处理 | 测试 What is the cafeteria menu today? | 命中为空时返回 no_evidence |
| 改动后评估变差 | 一次改了太多层 | 对比 git diff 和评估输出 | 一次只改一层 |
Step 11:练习任务
按顺序完成:
| 难度 | 任务 | 通过标准 |
|---|---|---|
| Easy | 新增一份 public 文档和一个评估用例 | passed 数量增加,且新引用出现 |
| Standard | 输出 logs/retrieval_logs.jsonl | 每个问题记录 query、role、status、score 和 citations |
| Standard | 新增 top_k 配置变量 | 能比较 top_k=1 和 top_k=2 的结果 |
| Challenge | 用 embedding 替换 keyword_score() | 仍然能用同一组评估用例跑通 |
| Challenge | 增加一个小型 FastAPI 接口 | /ask 返回 status、answer、citations 和 trace ID |
工作坊通关标准
当你能做到下面这些,就算完成本工作坊:
- 运行
python3 rag_app_workshop.py并得到预期输出。 - 能解释
chunk、metadata、top_k、citation、trace和evaluation set的含义。 - 能说明为什么 public 用户不能访问
internal.md#roadmap。 - 能新增一份文档和一个评估用例,并且不破坏现有检查。
- 能说清楚未来接 embedding、向量数据库或真实模型 API 时,应该先替换哪一部分。
请把这个小项目保留下来,作为第 8 章的 baseline。后面遇到 LangChain、向量数据库、部署、监控或 Agent 时,都可以回头对照这个脚本:框架替你做了哪一部分,哪些责任仍然属于你的应用代码?