6.2.4 Autograd 自動微分
autograd は、順伝播の計算を勾配へ変えるエンジンです。大事なのは backward() を暗記することではなく、どの計算グラフが記録され、勾配がどこに保存され、いつ累積し、いつ追跡を止めるべきかを理解することです。
学習目標
requires_grad=Trueが何を変えるのか説明できる。loss.backward()を実行し、.gradを確認できる。backward()は勾配を計算するだけで、パラメータを更新しないと理解する。zero_grad()で勾配累積のバグを避ける。- 適切な場所で
torch.no_grad()とdetach()を使う。
まず計算グラフを見る
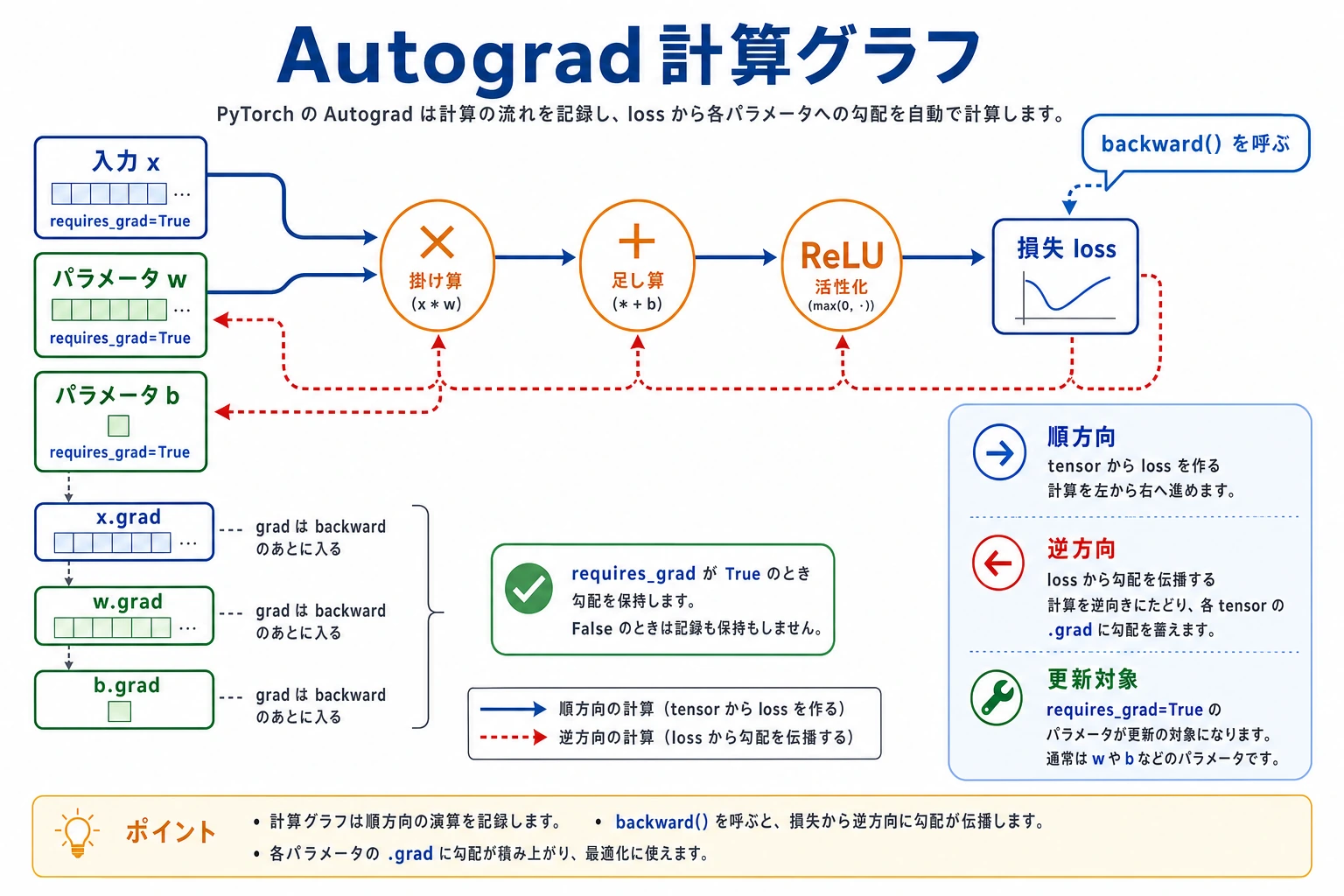
この順番で読みます。
パラメータ -> 順伝播の演算 -> loss -> backward() -> parameter.grad -> optimizer step
Autograd は loss を作る演算を記録します。backward() を呼ぶと、PyTorch はその記録されたグラフを逆向きにたどり、連鎖律を適用します。
実験 1: 1 つのパラメータ、1 つの勾配
まず 1 つの数から始めると、仕組みが見えやすいです。
import torch
w = torch.tensor(2.0, requires_grad=True)
loss = (w * 3 - 10) ** 2
print("loss:", loss.item())
loss.backward()
print("w.grad:", w.grad.item())
期待される出力:
loss: 16.0
w.grad: -24.0
何が起きたか:
wはrequires_grad=Trueなので、学習対象の値です。lossはwから作られるため、PyTorch はwからlossまでの経路を記録します。loss.backward()は、wが変わると loss がどう変わるかを計算します。- 結果は
w.gradに保存されます。
計算の流れは次のとおりです。
w -> w * 3 -> w * 3 - 10 -> square -> loss
実験 2: 勾配は更新ではない
backward() は勾配を計算するだけです。更新ステップは別に必要です。
import torch
w = torch.tensor(2.0, requires_grad=True)
lr = 0.1
print("single_parameter_training")
for step in range(1, 6):
loss = (w * 3 - 10) ** 2
loss.backward()
with torch.no_grad():
w -= lr * w.grad
print(
f"step={step} "
f"w={w.item():.4f} "
f"loss={loss.item():.4f} "
f"grad={w.grad.item():.4f}"
)
w.grad.zero_()
期待される出力:
single_parameter_training
step=1 w=4.4000 loss=16.0000 grad=-24.0000
step=2 w=2.4800 loss=10.2400 grad=19.2000
step=3 w=4.0160 loss=6.5536 grad=-15.3600
step=4 w=2.7872 loss=4.1943 grad=12.2880
step=5 w=3.7702 loss=2.6844 grad=-9.8304
値が行ったり来たりするのは、この toy 関数では lr=0.1 が少し大きいからです。これは大事な観察です。勾配は方向とスケールを教えますが、学習率が一歩の大きさを決めます。
torch.no_grad() が必要な理由:
wの更新そのものは、次の順伝播グラフの一部ではない。- autograd に更新操作まで記録してほしくない。
- メモリを節約し、グラフ関連のエラーを避けられる。
実験 3: 勾配累積を見る
PyTorch はデフォルトで勾配を累積します。.grad を自動で上書きしません。
import torch
x = torch.tensor(3.0, requires_grad=True)
y1 = x ** 2
y1.backward()
print("after first backward:", x.grad.item())
y2 = 2 * x
y2.backward()
print("after second backward:", x.grad.item())
x.grad.zero_()
y3 = 2 * x
y3.backward()
print("after zero and third backward:", x.grad.item())
期待される出力:
after first backward: 6.0
after second backward: 8.0
after zero and third backward: 2.0
理由:
x=3のとき、x ** 2の勾配は6。2 * xの勾配は2。- 2 回目の backward 後、
.gradは6 + 2 = 8になる。 zero_()の後は、次の勾配がきれいな状態から始まる。
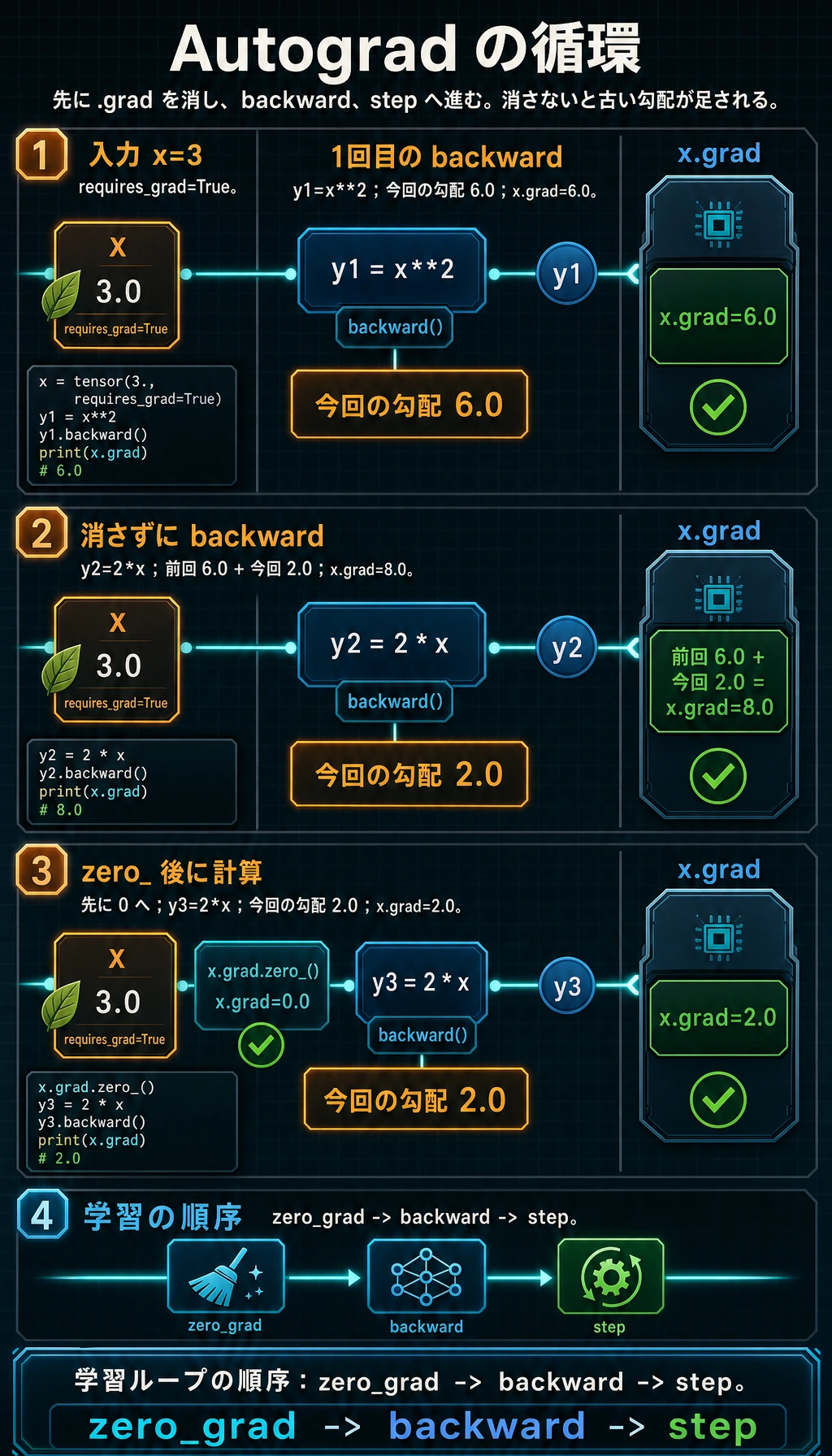
通常の学習コードで次の順番を使うのはこのためです。
optimizer.zero_grad()
loss.backward()
optimizer.step()
実験 4: 2 つのパラメータを手で学習する
今度は nn.Linear も optimizer も使わず、小さな線形モデルを手で学習します。学習ループ全体が見えるようになります。
import torch
# 目標ルール: y = 2x + 1
x = torch.tensor([1.0, 2.0, 3.0, 4.0])
y_true = torch.tensor([3.0, 5.0, 7.0, 9.0])
w = torch.tensor(0.0, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)
lr = 0.05
print("two_parameter_fit")
for epoch in range(201):
y_pred = w * x + b
loss = ((y_pred - y_true) ** 2).mean()
loss.backward()
with torch.no_grad():
w -= lr * w.grad
b -= lr * b.grad
if epoch % 50 == 0:
print(
f"epoch={epoch:3d} "
f"loss={loss.item():.4f} "
f"w={w.item():.4f} "
f"b={b.item():.4f}"
)
w.grad.zero_()
b.grad.zero_()
期待される出力:
two_parameter_fit
epoch= 0 loss=41.0000 w=1.7500 b=0.6000
epoch= 50 loss=0.0030 w=2.0452 b=0.8672
epoch=100 loss=0.0007 w=2.0212 b=0.9375
epoch=150 loss=0.0001 w=2.0100 b=0.9706
epoch=200 loss=0.0000 w=2.0047 b=0.9862

パラメータは w=2 と b=1 に近づきます。ニューラルネットワークも同じループを使います。ただし、パラメータが 2 個ではなく、何百万個以上になるだけです。
requires_grad、no_grad、detach
この 3 つは関連していますが、同じものではありません。
| 道具 | 使う場面 | 効果 |
|---|---|---|
requires_grad=True | テンソルがパラメータ、または勾配が必要 | 以後の演算が追跡される |
torch.no_grad() | 推論または手動パラメータ更新 | 一時的に計算グラフの記録を止める |
tensor.detach() | グラフ履歴なしでテンソル値を使いたい | autograd から切り離されたテンソルを返す |
実行して確認します。
import torch
w = torch.tensor(5.0, requires_grad=True)
tracked = w * 2
detached = tracked.detach()
with torch.no_grad():
untracked = w * 3
print("tracked.requires_grad:", tracked.requires_grad)
print("detached.requires_grad:", detached.requires_grad)
print("untracked.requires_grad:", untracked.requires_grad)
期待される出力:
tracked.requires_grad: True
detached.requires_grad: False
untracked.requires_grad: False
実用例:
- 検証や予測では
no_grad()を使います。 - ログ記録、NumPy 変換、グラフ全体を保持したくない値の保存には
detach()を使います。 - loss に勾配を返す必要があるテンソルを detach してはいけません。
よくあるエラーパターン
| 症状 | ありがちな原因 | 直し方 |
|---|---|---|
.grad が None | テンソルが勾配を必要としていない、または leaf tensor ではない | requires_grad を確認し、モデルパラメータを調べる |
| 学習が不安定になる | 勾配を消していない | backward() の前に optimizer.zero_grad() を呼ぶ |
RuntimeError: Trying to backward through the graph a second time | backward 後に同じグラフを再利用した | 順伝播をやり直す。理由が明確な場合だけ retain_graph=True を使う |
| メモリが増え続ける | 計算グラフにつながった tensor をリストに保存している | loss.item() または tensor.detach() を保存する |
| 検証が遅く、メモリを使いすぎる | 評価中も勾配を追跡している | 検証を with torch.no_grad(): で囲む |
retain_graph=True は慎重に初心者向けの多くのコードでは retain_graph=True は不要です。使いたくなったら、まず「同じ forward 結果に対して backward() を 2 回呼んでいないか?」を確認してください。
クイックデバッグチェックリスト
backward() の前:
print("loss requires_grad:", loss.requires_grad)
print("w requires_grad:", w.requires_grad)
backward() の後:
print("w.grad:", w.grad)
print("b.grad:", b.grad)
通常の学習ループの順番は次です。
forward -> loss -> zero_grad -> backward -> step
一部のコードでは zero_grad を forward の前に置きますが、核心は同じです。次の更新前に古い勾配を消します。
練習
- 実験 4 を
y = 3x - 2を学ぶように変えてください。wとbは何に近づくべきですか? - 実験 4 の
w.grad.zero_()とb.grad.zero_()を削除して、何が起きるか観察してください。 lrを0.5と0.005に変えてください。どちらが不安定で、どちらが遅いですか?- 200 epoch のあいだ
loss自体をリストに保存し、次にloss.item()を保存してください。なぜ後者のほうが安全ですか?
まとめ
- Autograd は、パラメータから loss までの計算グラフを記録します。
backward()は勾配を計算しますが、パラメータは更新しません。- 勾配はデフォルトで累積するので、次の更新前に消します。
- 推論と手動更新には
no_grad()、グラフ履歴なしの値が必要なときはdetach()を使います。