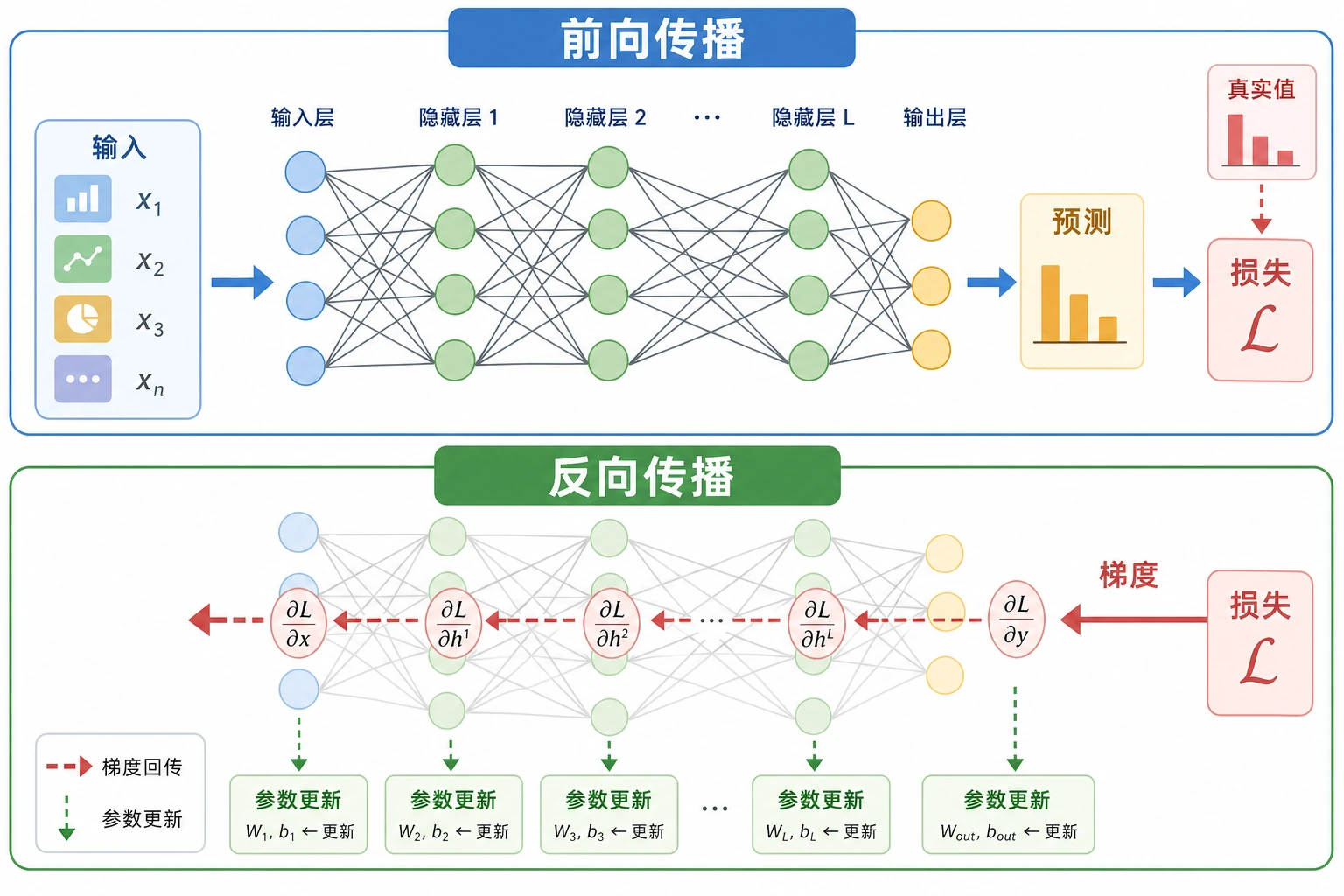
6.1.4 前向传播与反向传播
本节概览
训练神经网络就是一个循环:预测、衡量错误、计算梯度、更新参数,然后重复。
你会做出什么
这一节会运行一个很小的 PyTorch 示例,展示:
- 一次前向传播;
- binary cross-entropy loss;
loss.backward()生成的梯度;optimizer.step()带来的参数更新;- 一个 loss 持续下降的小训练循环。
环境准备
python -m pip install -U torch
运行完整实验
新建 forward_backward_lab.py:
import torch
import torch.nn as nn
torch.manual_seed(42)
x = torch.tensor([[1.0, 2.0]])
y = torch.tensor([[1.0]])
model = nn.Sequential(nn.Linear(2, 1), nn.Sigmoid())
loss_fn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
print("one_training_step")
with torch.no_grad():
before = model(x)
print("prediction_before=", round(float(before.item()), 3))
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
linear = model[0]
print("loss_before=", round(float(loss.item()), 4))
print("weight_grad=", [[round(float(v), 4) for v in row] for row in linear.weight.grad.tolist()])
print("bias_grad=", [round(float(v), 4) for v in linear.bias.grad.tolist()])
optimizer.step()
with torch.no_grad():
after = model(x)
new_loss = loss_fn(after, y)
print("prediction_after=", round(float(after.item()), 3))
print("loss_after=", round(float(new_loss.item()), 4))
print("mini_training_loop")
for step in range(1, 6):
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"step={step} loss={loss.item():.4f} pred={pred.item():.3f}")
运行:
python forward_backward_lab.py
预期输出:
one_training_step
prediction_before= 0.825
loss_before= 0.1927
weight_grad= [[-0.1753, -0.3505]]
bias_grad= [-0.1753]
prediction_after= 0.888
loss_after= 0.1183
mini_training_loop
step=1 loss=0.1183 pred=0.888
step=2 loss=0.0861 pred=0.918
step=3 loss=0.0678 pred=0.934
step=4 loss=0.0560 pred=0.945
step=5 loss=0.0478 pred=0.953

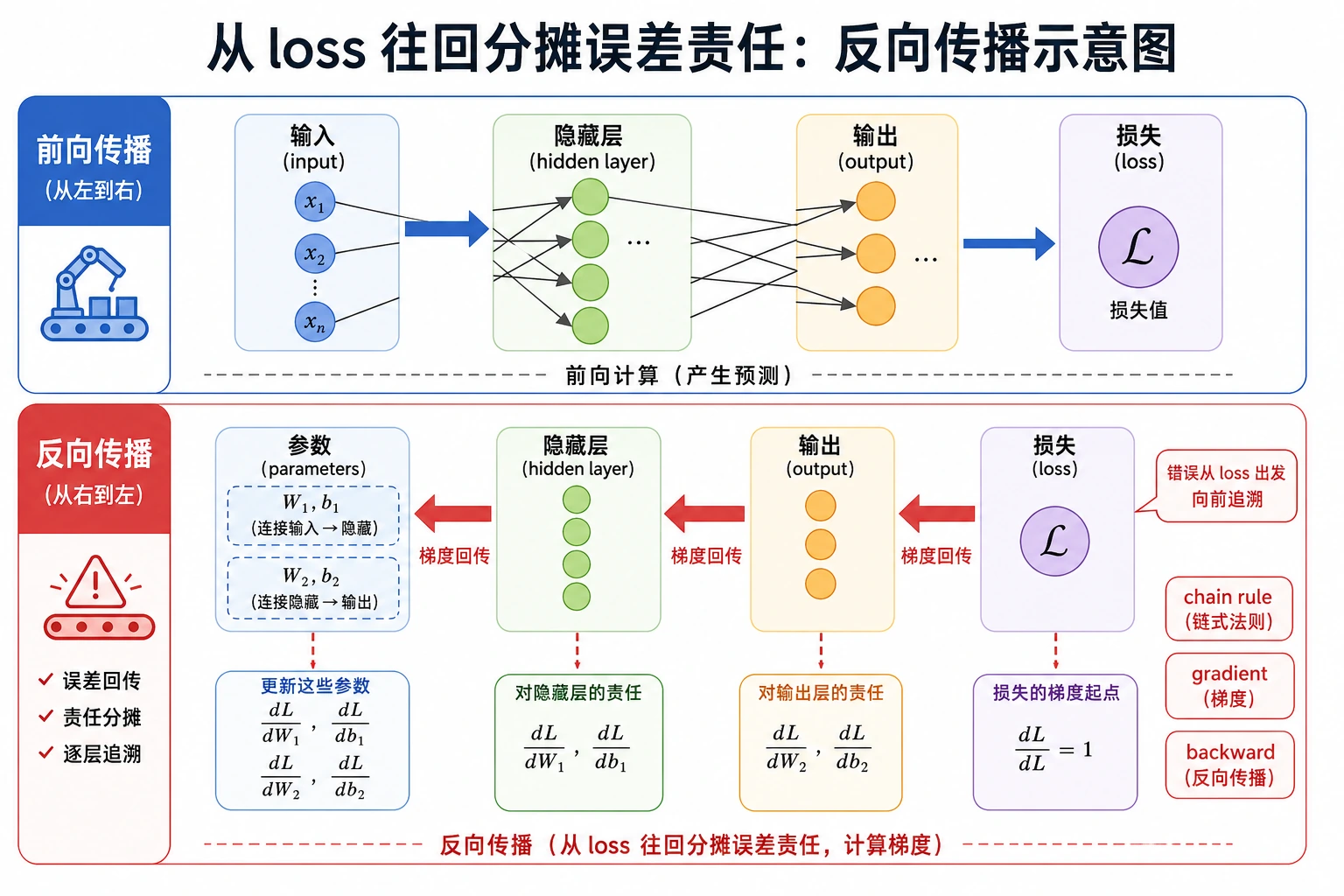
读懂五个步骤
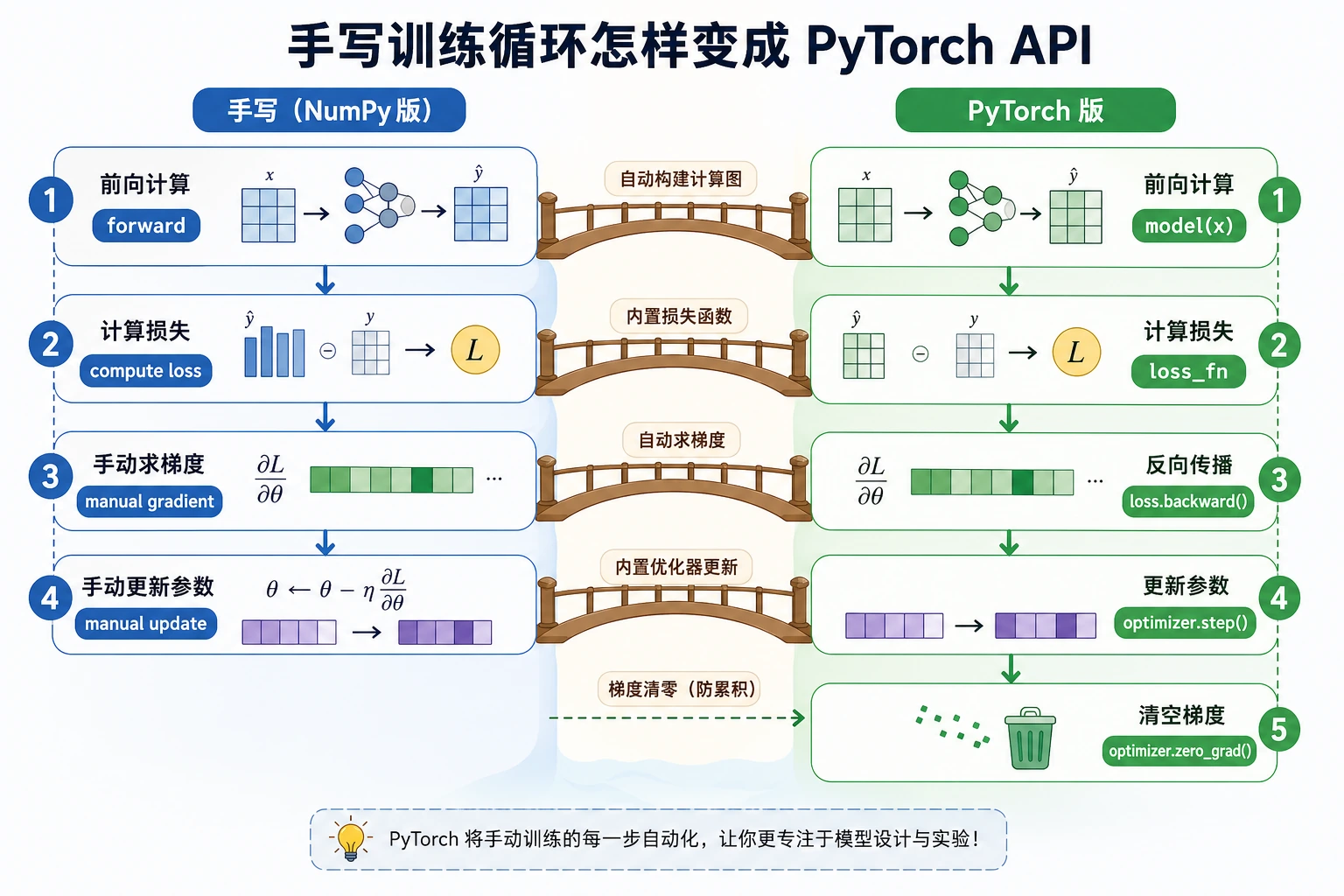
一次训练步骤有固定顺序:
| 步骤 | 代码 | 含义 |
|---|---|---|
| forward | pred = model(x) | 计算预测 |
| loss | loss = loss_fn(pred, y) | 衡量错误 |
| clear | optimizer.zero_grad() | 清掉旧梯度 |
| backward | loss.backward() | 计算梯度 |
| update | optimizer.step() | 更新参数 |
顺序很重要。忘记 zero_grad(),梯度会从前一步累加。忘记 step(),模型永远不会更新。
前向传播
前向传播就是数据从输入走到输出:
pred = model(x)
这里的模型是:
nn.Sequential(nn.Linear(2, 1), nn.Sigmoid())
线性层计算分数,Sigmoid 把它变成类似概率的值。
损失函数
目标是 1.0,初始预测是 0.825,所以模型接近但还不完美:
loss_before= 0.1927
BCELoss 是 binary cross-entropy,二元交叉熵。本例输出经过 Sigmoid,适合搭配它。
后续写 PyTorch 时,记住这个搭配:
| 输出形式 | Loss |
|---|---|
最后是 Sigmoid 概率 | nn.BCELoss() |
| 没有 Sigmoid 的 raw logits | nn.BCEWithLogitsLoss() |
| 多分类 raw logits | nn.CrossEntropyLoss() |
反向传播
loss.backward() 会填充梯度:
weight_grad= [[-0.1753, -0.3505]]
bias_grad= [-0.1753]
梯度告诉 optimizer:如果改变某个参数,loss 会怎样变化。PyTorch 中你不需要手推每个梯度;autograd 会在前向过程中构建计算图,并在反向时使用它。
Optimizer Step
执行 optimizer.step() 后,预测更接近目标:
prediction_before= 0.825
prediction_after= 0.888
loss_after= 0.1183
这就是训练的缩小版:参数变了,预测改善了,loss 降低了。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| loss 完全不变 | 忘了 optimizer.step() | 在 backward() 后调用 step() |
| 梯度奇怪地越来越大 | 忘了 zero_grad() | 每一步都清梯度 |
grad 是 None | tensor 没接到 loss,或没 backward() | 检查计算图 |
| binary loss 报错 | 输出/目标 shape 不匹配 | 本例都用 [batch, 1] |
loss 变成 nan | 学习率太高或输入异常 | 降低 LR,检查输入 |
练习
- 把
lr=0.5改成0.05和1.0。loss 怎么变? - 移除
optimizer.zero_grad()并打印梯度。什么在累积? - 把
nn.BCELoss()换成nn.BCEWithLogitsLoss(),同时移除nn.Sigmoid()。 - 给
x和y增加一个样本,检查 shape。 - 在
optimizer.step()前后打印模型权重。
过关检查
你能解释下面几点,就完成本节:
- forward pass 计算预测;
- loss 衡量错误;
- backward pass 计算梯度;
- optimizer step 更新参数;
zero_grad()防止旧梯度累积。