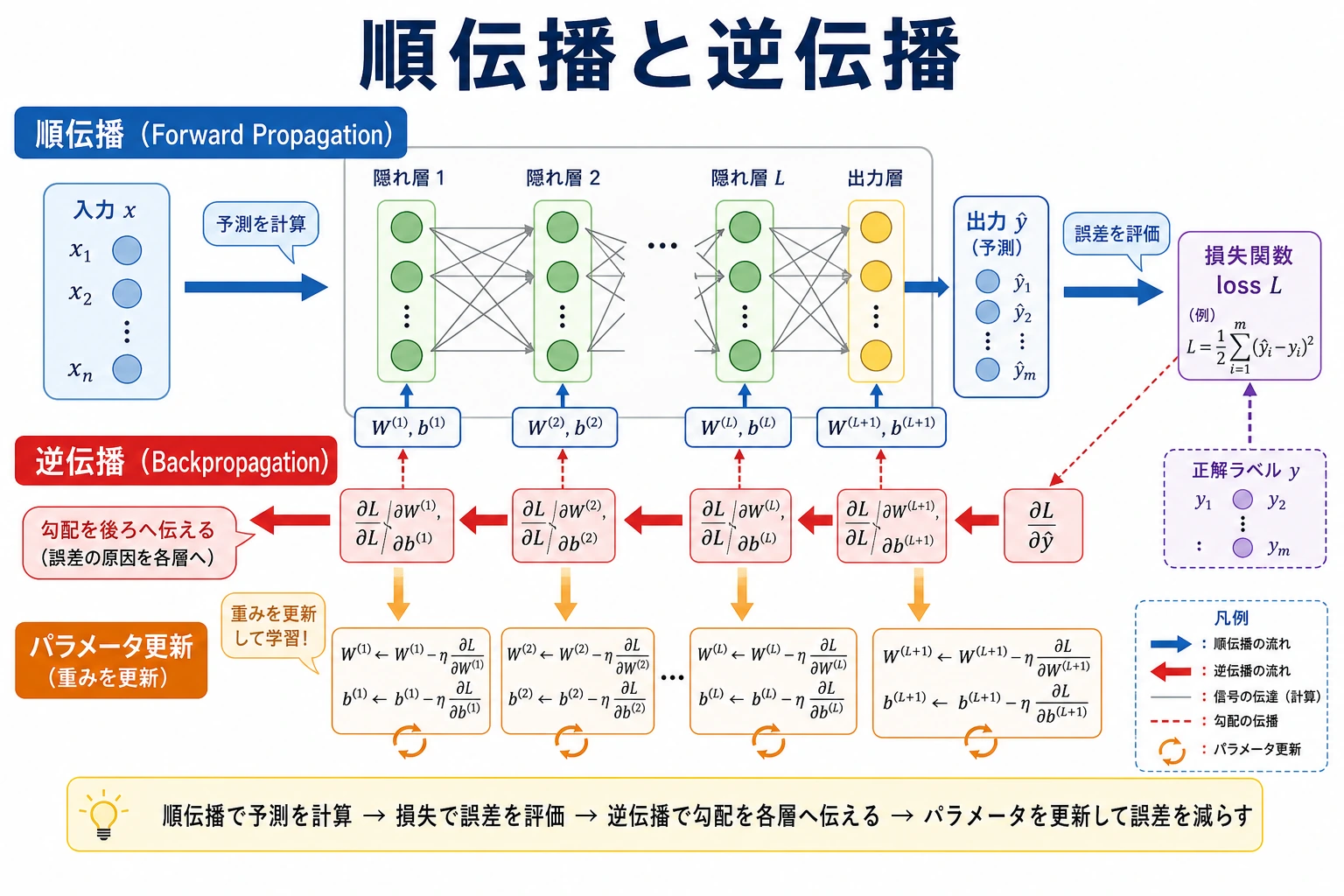
6.1.4 順伝播と逆伝播
この節の概要
ニューラルネットワークの訓練は、予測し、誤差を測り、勾配を計算し、パラメータを更新し、繰り返すループです。
作るもの
この節では、小さな PyTorch 例で次を確認します。
- 1 回の forward pass;
- binary cross-entropy loss;
loss.backward()が作る勾配;optimizer.step()によるパラメータ更新;- loss が下がるミニ訓練ループ。
セットアップ
python -m pip install -U torch
完全な実験を実行する
forward_backward_lab.py を作成します。
import torch
import torch.nn as nn
torch.manual_seed(42)
x = torch.tensor([[1.0, 2.0]])
y = torch.tensor([[1.0]])
model = nn.Sequential(nn.Linear(2, 1), nn.Sigmoid())
loss_fn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
print("one_training_step")
with torch.no_grad():
before = model(x)
print("prediction_before=", round(float(before.item()), 3))
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
linear = model[0]
print("loss_before=", round(float(loss.item()), 4))
print("weight_grad=", [[round(float(v), 4) for v in row] for row in linear.weight.grad.tolist()])
print("bias_grad=", [round(float(v), 4) for v in linear.bias.grad.tolist()])
optimizer.step()
with torch.no_grad():
after = model(x)
new_loss = loss_fn(after, y)
print("prediction_after=", round(float(after.item()), 3))
print("loss_after=", round(float(new_loss.item()), 4))
print("mini_training_loop")
for step in range(1, 6):
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"step={step} loss={loss.item():.4f} pred={pred.item():.3f}")
実行します。
python forward_backward_lab.py
期待される出力:
one_training_step
prediction_before= 0.825
loss_before= 0.1927
weight_grad= [[-0.1753, -0.3505]]
bias_grad= [-0.1753]
prediction_after= 0.888
loss_after= 0.1183
mini_training_loop
step=1 loss=0.1183 pred=0.888
step=2 loss=0.0861 pred=0.918
step=3 loss=0.0678 pred=0.934
step=4 loss=0.0560 pred=0.945
step=5 loss=0.0478 pred=0.953
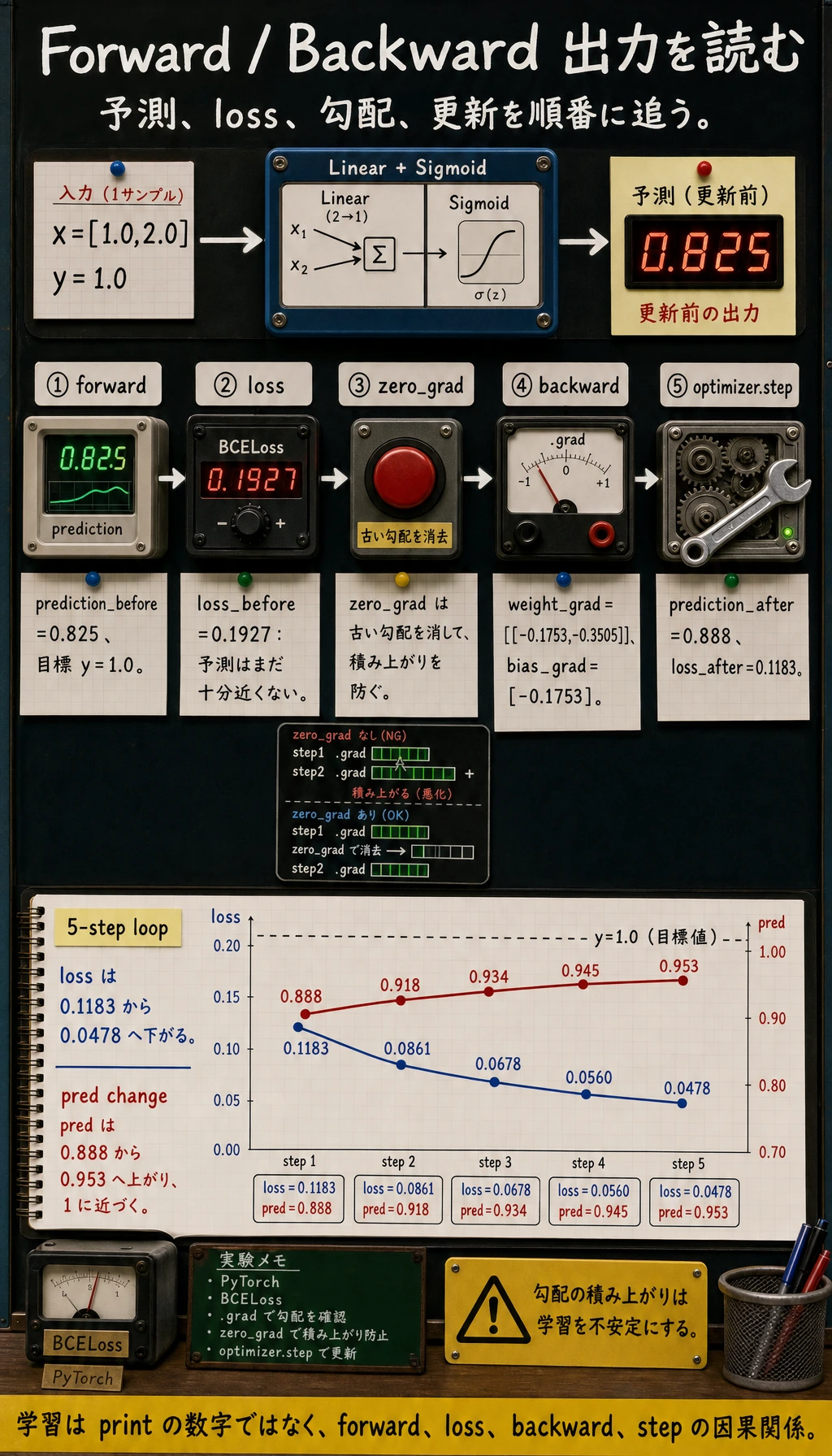
5 つの手順を読む
1 回の訓練ステップには固定の順序があります。
| 手順 | コード | 意味 |
|---|---|---|
| forward | pred = model(x) | 予測を計算する |
| loss | loss = loss_fn(pred, y) | 誤差を測る |
| clear | optimizer.zero_grad() | 古い勾配を消す |
| backward | loss.backward() | 勾配を計算する |
| update | optimizer.step() | パラメータを更新する |
順序が重要です。zero_grad() を忘れると、前の step の勾配が累積します。step() を忘れると、モデルは更新されません。
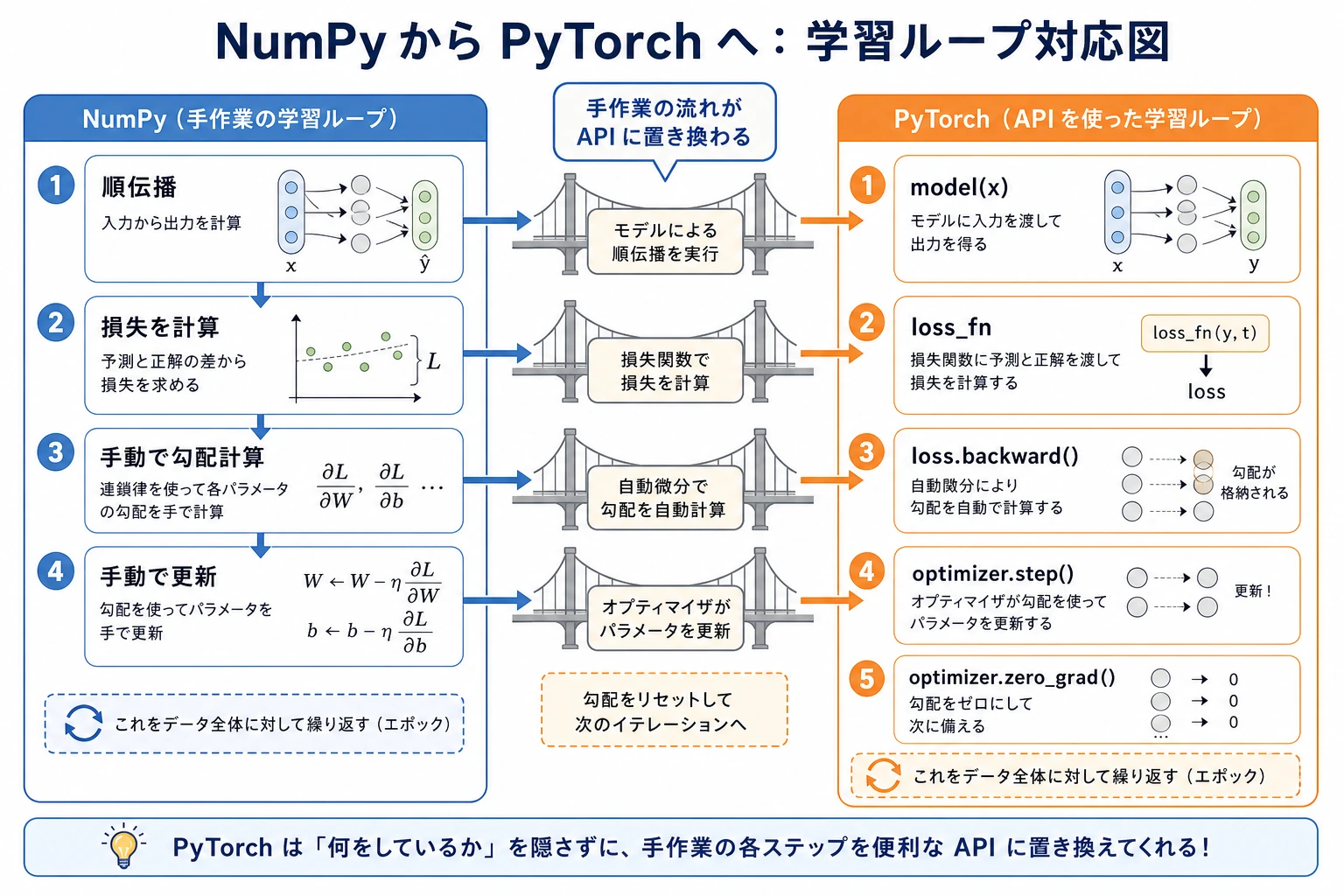
順伝播
順伝播では、データが入力から出力へ進みます。
pred = model(x)
ここでのモデルは:
nn.Sequential(nn.Linear(2, 1), nn.Sigmoid())
線形層がスコアを計算し、Sigmoid が確率らしい値に変換します。
損失関数
目標は 1.0、最初の予測は 0.825 なので、近いけれど完全ではありません。
loss_before= 0.1927
BCELoss は binary cross-entropy です。この例では出力が Sigmoid 後の確率なので、適切な組み合わせです。
今後 PyTorch を書くときは、この対応を覚えておくと安全です。
| 出力形式 | Loss |
|---|---|
最後に Sigmoid 確率 | nn.BCELoss() |
| Sigmoid なしの raw logits | nn.BCEWithLogitsLoss() |
| 多クラス raw logits | nn.CrossEntropyLoss() |
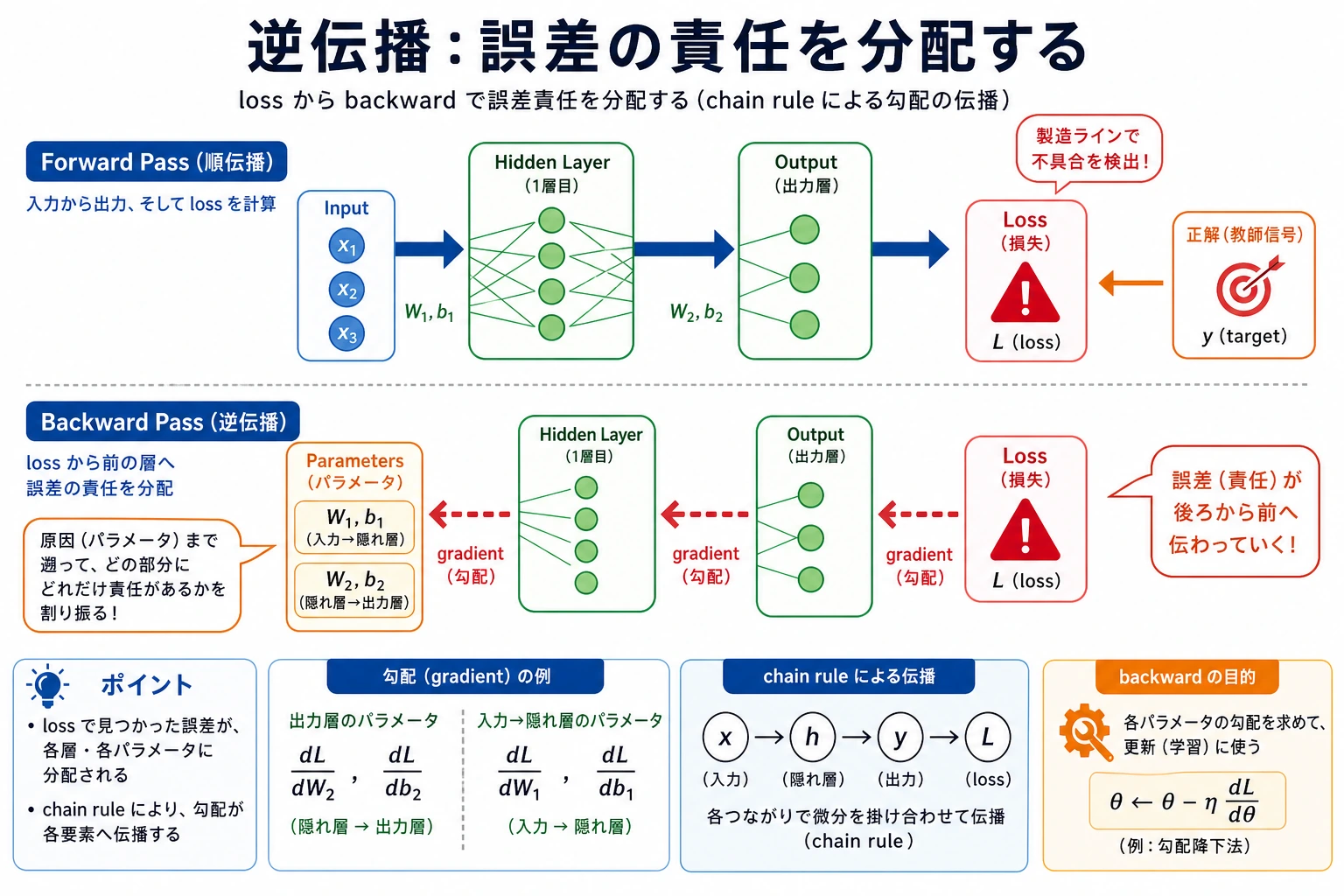
逆伝播
loss.backward() は勾配フィールドを埋めます。
weight_grad= [[-0.1753, -0.3505]]
bias_grad= [-0.1753]
勾配は、あるパラメータを変えると loss がどう変わるかを optimizer に伝えます。PyTorch では、すべての勾配を手で導出する必要はありません。autograd が forward 中に計算グラフを作り、backward で使います。
Optimizer Step
optimizer.step() のあと、予測は目標に近づきます。
prediction_before= 0.825
prediction_after= 0.888
loss_after= 0.1183
これが訓練の縮小版です。パラメータが変わり、予測が改善し、loss が下がりました。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| loss が変わらない | optimizer.step() を忘れている | backward() の後に step() を呼ぶ |
| 勾配が変に増え続ける | zero_grad() を忘れている | 毎 step で勾配を消す |
grad が None | tensor が loss につながっていない、または backward() していない | 計算グラフを確認する |
| binary loss でエラー | 出力と target の shape が違う | この例では両方 [batch, 1] にする |
loss が nan になる | 学習率が高い、または入力が不正 | LR を下げ、入力を確認する |
練習
lr=0.5を0.05と1.0に変えてください。loss はどう変わりますか?optimizer.zero_grad()を消して勾配を表示してください。何が累積しますか?nn.BCELoss()をnn.BCEWithLogitsLoss()に変え、nn.Sigmoid()を外してください。xとyにもう 1 サンプル追加し、shape を確認してください。optimizer.step()の前後でモデル重みを表示してください。
合格チェック
次を説明できれば、この節はクリアです。
- forward pass は予測を計算する;
- loss は誤差を測る;
- backward pass は勾配を計算する;
- optimizer step はパラメータを更新する;
zero_grad()は古い勾配の累積を防ぐ。