6.1.6 正則化
この節の概要
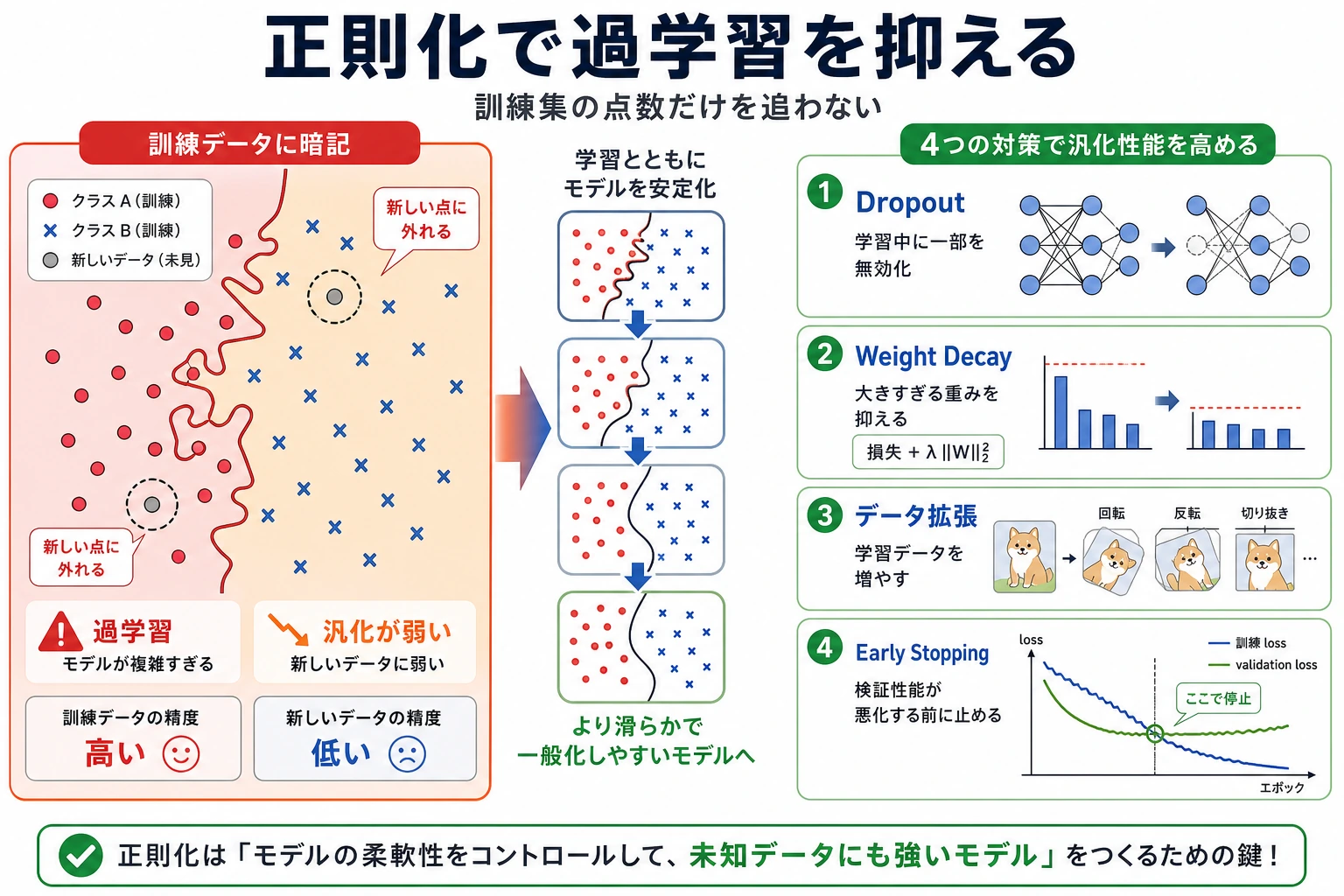
正則化は、training loss をできるだけ低くするためだけのものではありません。validation や未来のデータでよく汎化させるためのものです。
作るもの
この節では、PyTorch 実験で次を比較します。
- 正則化なし;
- dropout;
- weight decay;
- dropout + weight decay;
best_epochによる early stopping の挙動。
セットアップ
python -m pip install -U torch scikit-learn
完全な実験を実行する
regularization_lab.py を作成します。
import torch
import torch.nn as nn
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def make_data():
X, y = make_moons(n_samples=500, noise=0.28, random_state=42)
X = StandardScaler().fit_transform(X)
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.35, random_state=42, stratify=y
)
return (
torch.tensor(X_train, dtype=torch.float32),
torch.tensor(y_train.reshape(-1, 1), dtype=torch.float32),
torch.tensor(X_val, dtype=torch.float32),
torch.tensor(y_val.reshape(-1, 1), dtype=torch.float32),
)
class MLP(nn.Module):
def __init__(self, dropout=0.0):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 32), nn.ReLU(), nn.Dropout(dropout),
nn.Linear(32, 32), nn.ReLU(), nn.Dropout(dropout),
nn.Linear(32, 1),
)
def forward(self, x):
return self.net(x)
def accuracy(logits, y):
pred = (torch.sigmoid(logits) >= 0.5).float()
return (pred == y).float().mean().item()
def train_case(name, dropout=0.0, weight_decay=0.0, epochs=120):
torch.manual_seed(42)
X_train, y_train, X_val, y_val = make_data()
model = MLP(dropout=dropout)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.01, weight_decay=weight_decay)
best_val = 10**9
patience = 0
best_epoch = 0
for epoch in range(1, epochs + 1):
model.train()
loss = loss_fn(model(X_train), y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
val_loss = loss_fn(model(X_val), y_val).item()
if val_loss < best_val:
best_val = val_loss
best_epoch = epoch
patience = 0
else:
patience += 1
if patience >= 20:
break
model.eval()
with torch.no_grad():
train_loss = loss_fn(model(X_train), y_train).item()
val_loss = loss_fn(model(X_val), y_val).item()
train_acc = accuracy(model(X_train), y_train)
val_acc = accuracy(model(X_val), y_val)
print(
f"{name:<14} epochs={epoch:<3} best_epoch={best_epoch:<3} "
f"train_loss={train_loss:.3f} val_loss={val_loss:.3f} "
f"train_acc={train_acc:.3f} val_acc={val_acc:.3f}"
)
print("regularization_lab")
train_case("plain", dropout=0.0, weight_decay=0.0)
train_case("dropout", dropout=0.25, weight_decay=0.0)
train_case("weight_decay", dropout=0.0, weight_decay=0.05)
train_case("both", dropout=0.25, weight_decay=0.05)
実行します。
python regularization_lab.py
期待される出力:
regularization_lab
plain epochs=87 best_epoch=67 train_loss=0.141 val_loss=0.155 train_acc=0.945 val_acc=0.931
dropout epochs=101 best_epoch=81 train_loss=0.158 val_loss=0.162 train_acc=0.945 val_acc=0.943
weight_decay epochs=87 best_epoch=67 train_loss=0.141 val_loss=0.154 train_acc=0.948 val_acc=0.931
both epochs=101 best_epoch=81 train_loss=0.159 val_loss=0.162 train_acc=0.942 val_acc=0.949

結果を読む
plain モデルは training loss が低いです。
plain train_loss=0.141 val_acc=0.931
しかし、組み合わせた正則化モデルは validation accuracy が高くなっています。
both train_loss=0.159 val_acc=0.949
これが正則化のポイントです。training fit が少し悪くなっても、汎化が良くなるなら価値があります。
Dropout
nn.Dropout(0.25) は、訓練中に活性化をランダムに落とします。
nn.Linear(2, 32), nn.ReLU(), nn.Dropout(dropout)
ネットワークが特定の隠れユニットに依存しすぎないようにします。主に隠れ層で使います。model.eval() 中は dropout は自動的に無効になります。
Weight Decay
Weight decay は optimizer が適用する L2 風の正則化です。
torch.optim.AdamW(model.parameters(), lr=0.01, weight_decay=0.05)
大きすぎる重みを抑えます。現代の PyTorch では、weight decay が適応的な勾配更新から分離されるため、古い Adam + L2 より AdamW が好まれることが多いです。
Early Stopping
実験では次を追跡しています。
best_epoch=67
Early stopping は、validation が最も良い checkpoint を保持し、validation loss がしばらく改善しなければ停止する考え方です。validation performance が止まったあとに無駄に訓練し続けるのを防ぎます。
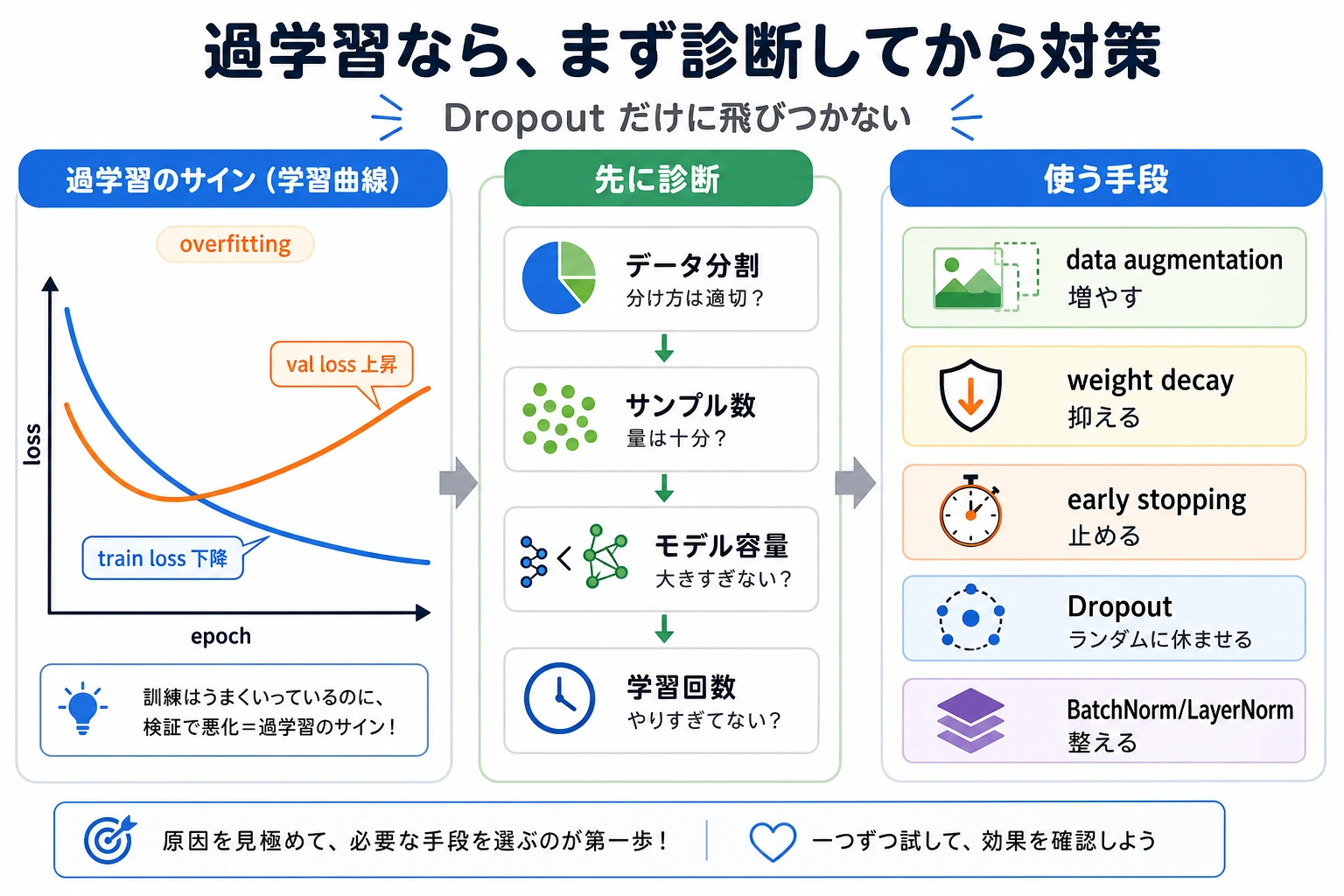
まず試すこと
| 問題 | 最初の行動 |
|---|---|
| training loss 低い、validation loss 高い | weight decay または dropout |
| validation が改善後に悪化する | early stopping |
| train も validation も underfit | 正則化を減らす、モデルを強くする |
| validation が noisy | LR を下げる、データを増やす、fold 平均を見る |
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| dropout が訓練を大きく悪化させる | dropout が高すぎる、またはモデルが小さい | dropout を下げる |
| train も validation も悪い | アンダーフィット | 正則化を減らす |
| best epoch がかなり早い | 訓練しすぎ | best checkpoint を保存する |
| weight decay が効かない | 値が小さい、またはモデルが単純 | 少しずつ増やす |
| eval 結果がランダムに変わる | model.eval() を忘れている | validation 前に eval mode にする |
練習
- dropout を
0.1、0.5、0.7に変えてください。 - weight decay を
0.001、0.01、0.1に変えてください。 - 20 epoch ごとに train loss と validation loss を表示してください。
val_lossが改善したときに best model state を保存してください。- validation 時に
model.eval()を外し、何が変わるか説明してください。
合格チェック
次を説明できれば、この節はクリアです。
- 正則化は training loss だけでなく validation performance を見る;
- dropout は訓練中に隠れ活性化をランダムに無効化する;
- weight decay は大きな重みを抑える;
- early stopping は validation の最良点を保持する;
- 正則化が強すぎるとアンダーフィットになる。