前向传播与反向传播
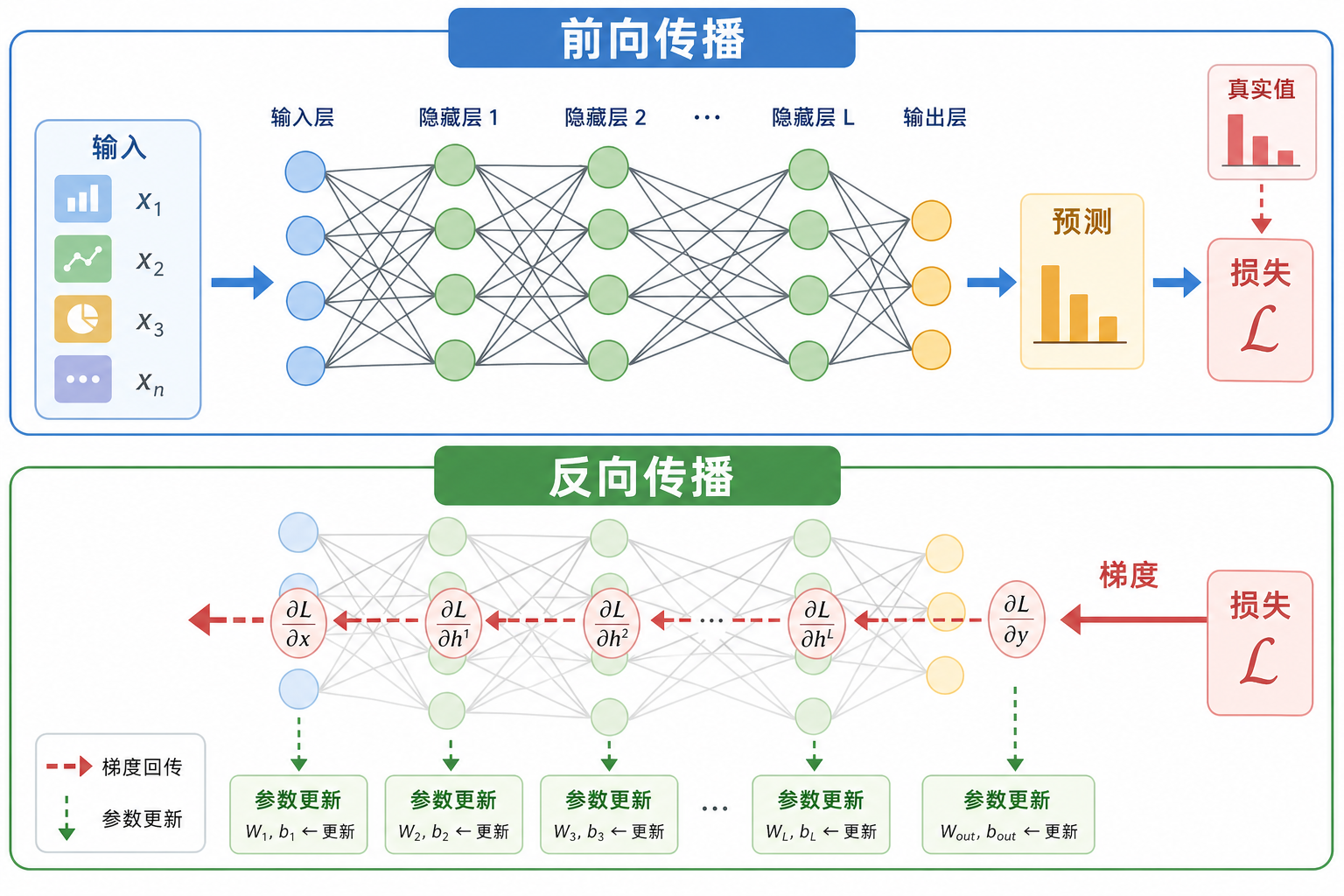
反向传播是深度学习的核心算法。你必须能手动推导一个 2 层网络的反向传播过程。本节在第 4 站"链式法则与反向传播预览"的基础上,给出完整的推导和实现。
学习目标
- 理解前向传播的完整计算过程
- 掌握常用损失函数(MSE、交叉熵)
- 🔧 能手动推导 2 层网络的反向传播
- 理解计算图的概念
先建立一张地图
这一节最容易让新人害怕的地方,是“公式一下子变多”。更适合的理解顺序是:
你可以把这节课理解成一句话:
前向传播负责算结果,反向传播负责算“该怎么改”。
这节和第 5 站、上一节是怎么接上的
如果你刚学过上一节,可以先这样理解:
- 上一节解决的是“一个神经元 / 一层网络到底在算什么”
- 这一节解决的是“它算错以后,参数到底怎么改”
如果你刚学过第 5 站,也可以这样对照:
- 第 5 站里你已经见过 loss 和梯度下降
- 这一节只是把“梯度到底从哪里来”彻底拆开给你看
所以这一节真正新增的,不是“突然很多公式”,而是:
- 训练过程里的责任分配是怎么一层层往回传的
一、前向传播
前向传播就是从输入到输出的计算过程:
1.0.1 前向传播时,最值得先盯哪四个对象?
第一次读网络前向代码时,可以先只盯这四类变量:
x / X:输入z:线性变换后的中间量a:过激活后的输出loss:最终误差
这样你看到任何一行代码,都更容易知道它是属于:
- 输入
- 中��间计算
- 输出
- 还是误差定义
1.1 手动计算示例
import numpy as np
# 一个极简的 2 层网络: 2→3→2
np.random.seed(0)
# 输入和权重
X = np.array([[1.0, 2.0]]) # 1 个样本, 2 个特征
W1 = np.array([[0.1, 0.3, -0.2],
[0.4, -0.1, 0.5]]) # 2×3
b1 = np.array([[0.0, 0.0, 0.0]])
W2 = np.array([[0.2, -0.3],
[0.1, 0.4],
[-0.5, 0.2]]) # 3×2
b2 = np.array([[0.0, 0.0]])
y_true = np.array([[1, 0]]) # 真实标签(one-hot)
# 前向传播
z1 = X @ W1 + b1
print(f"z1 = {z1}")
a1 = np.maximum(0, z1) # ReLU
print(f"a1 (ReLU) = {a1}")
z2 = a1 @ W2 + b2
print(f"z2 = {z2}")
# Softmax
exp_z2 = np.exp(z2 - z2.max())
a2 = exp_z2 / exp_z2.sum(axis=1, keepdims=True)
print(f"a2 (Softmax) = {a2}")
1.2 前向传播最该盯住哪三件事?
第一次看网络前向计算时,建议每一步都只问这三个问题:
- 当前张量的 shape 是什么
- 这一层做的是线性变换还是非线性变换
- 这一步输出会不会传给下一层
很多人一看到公式就晕,其实先抓住这三件事就够了。
1.3 一个更适合新人的类比:前向传播像“逐层加工”
可以先把前向传播想成工厂流水线:
- 输入原料进第一层
- 第一层加工后交给第二层
- 第二层再加工
- 最后得到成品输出
所以前向传播最重要的,不是“公式多”,而是:
- 数据在一层层流动
- 每层都在把表示改写成下一层更容易使用的形式
二、损失函数
2.1 MSE(回归)
MSE = (1/n) × Σ(yi - ŷi)²
# MSE
y_true_reg = np.array([3.0, 5.0, 2.0])
y_pred_reg = np.array([2.8, 5.2, 2.1])
mse = np.mean((y_true_reg - y_pred_reg) ** 2)
print(f"MSE = {mse:.4f}")
2.2 交叉熵(分类)
Cross-Entropy = -Σ(yi × log(ŷi))
# 交叉熵
loss = -np.sum(y_true * np.log(a2 + 1e-8))
print(f"交叉熵损失 = {loss:.4f}")
2.3 二元交叉熵(二分类)
BCE = -(y × log(ŷ) + (1-y) × log(1-ŷ))
# 二元交叉熵
y_bin = np.array([1, 0, 1, 1])
y_pred_bin = np.array([0.9, 0.1, 0.8, 0.7])
bce = -np.mean(y_bin * np.log(y_pred_bin) + (1 - y_bin) * np.log(1 - y_pred_bin))
print(f"BCE = {bce:.4f}")
损失函数选择
| 任务 | 输出层激活 | 损失函数 |
|---|---|---|
| 回归 | 无(线性) | MSE |
| 二分类 | Sigmoid | BCE |
| 多分类 | Softmax | 交叉熵 |
2.4 为什么输出层和损失函数总是一起讲?
因为它们本来就是一组“配套设计”。
比如:
- 回归输出连续值,常配
MSE - 二分类输出概率,常配
Sigmoid + BCE - 多分类输出类别分布,常配
Softmax + CrossEntropy
所以新人第一次做任务时,一个很稳的习惯是:
- 不只问模型最后一层怎么写
- 还要一起问:损失函数该怎么配
三、反向传播——🔧 手动推导
3.1 核心思想
反向传播就是链式法则的��系统化应用——从损失出发,逐层往回算每个参数的梯度。
3.2 反向传播最适合新人的一句话解释
你完全可以先不记完整推导,只先记住:
- 输出错了多少
- 这份错误怎么一层层往前分摊
- 每一层据此知道自己该改多少
这其实就已经抓住了反向传播的第一层本质。
3.2.1 一个更直白的说法:误差责任往前分摊
如果你还是觉得“梯度”很抽象,可以先把反向传播理解成:
- 最后结果错了
- 这份错误要一步步追溯到前面每层
- 每层都分到一部分“该负责的误差”
- 然后再根据这份责任决定参数怎么改
这就是为什么反向传播看起来像“从后往前传消息”。
3.3 完整推导(2 层网络)
# 继续上面的例子,手动反向传播
# --- 输出层梯度 ---
# 对 Softmax + 交叉熵, 梯度简化为: dz2 = a2 - y_true
dz2 = a2 - y_true
print(f"dz2 = {dz2}")
# W2 梯度: dW2 = a1.T @ dz2
dW2 = a1.T @ dz2
db2 = dz2.copy()
print(f"dW2 = \n{dW2}")
# --- 隐藏层梯度 ---
# da1 = dz2 @ W2.T
da1 = dz2 @ W2.T
print(f"da1 = {da1}")
# ReLU 的导数: z1 > 0 则为 1, 否则为 0
relu_mask = (z1 > 0).astype(float)
dz1 = da1 * relu_mask
print(f"dz1 = {dz1}")
# W1 梯度: dW1 = X.T @ dz1
dW1 = X.T @ dz1
db1 = dz1.copy()
print(f"dW1 = \n{dW1}")
# --- 参数更新 ---
lr = 0.1
W2 -= lr * dW2
b2 -= lr * db2
W1 -= lr * dW1
b1 -= lr * db1
print("\n参数已更新!")
3.4 梯度计算公式总结
| 变量 | 梯度 |
|---|---|
dz2 | a2 - y(Softmax+交叉熵简化) |
dW2 | a1.T @ dz2 |
db2 | dz2 |
da1 | dz2 @ W2.T |
dz1 | da1 * relu_mask |
dW1 | X.T @ dz1 |
db1 | dz1 |
3.5 第一次自己推导时,最容易错在哪?
通常最容易错的是这三类地方:
-
shape 对不上
比如把转置漏了,a1.T @ dz2写错。 -
把
z和a混掉
尤其在激活函数求导时,常常不知道到底该对谁求导。 -
忘了这是链式法则
只盯局部一项,没把“上一层的梯度 × 当前层导数”连起来。
所以第一次做时,建议每写一步都顺手写:
- 当前变量 shape
- 当前梯度来自哪一项
四、计算图
4.1 什么是计算图?
计算图是把每一步计算拆成节点,记录谁依赖谁。反向传播时,沿着图的反方向传��递梯度。
PyTorch 就是在自动构建和遍历这个计算图——这就是 autograd 的本质。
4.3 新人最容易在这节卡住哪几步?
- 搞不清
z、a、loss分别是什么 - 不知道为什么梯度方向要从后往前传
- 只记局部公式,不知道整条链在干什么
如果你现在已经能说清:
- 前向传播是在算什么
- 损失在衡量什么
- 反向传播是在把“误差责任”往前传
那这节就已经学得很到位了。
4.2 数值验证
用微小扰动验证梯度是否正确:
def numerical_gradient(f, x, eps=1e-5):
"""数值梯度(有限差分法)"""
grad = np.zeros_like(x)
for i in range(x.size):
old_val = x.flat[i]
x.flat[i] = old_val + eps
fx_plus = f(x)
x.flat[i] = old_val - eps
fx_minus = f(x)
grad.flat[i] = (fx_plus - fx_minus) / (2 * eps)
x.flat[i] = old_val
return grad
# 验证: y = x^2, dy/dx = 2x
x = np.array([3.0])
f = lambda x: x[0]**2
print(f"解析梯度: 2×3 = 6")
print(f"数值梯度: {numerical_gradient(f, x)[0]:.6f}")
五、完整训练循环
# 完整的 2 层网络训练 (分类月牙数据)
from sklearn.datasets import make_moons
X, y = make_moons(200, noise=0.2, random_state=42)
y_onehot = np.eye(2)[y] # one-hot
# 初始化
np.random.seed(42)
W1 = np.random.randn(2, 16) * 0.5
b1 = np.zeros((1, 16))
W2 = np.random.randn(16, 2) * 0.5
b2 = np.zeros((1, 2))
lr = 0.5
losses = []
for epoch in range(1000):
# 前向
z1 = X @ W1 + b1
a1 = np.maximum(0, z1)
z2 = a1 @ W2 + b2
exp_z = np.exp(z2 - z2.max(axis=1, keepdims=True))
a2 = exp_z / exp_z.sum(axis=1, keepdims=True)
# 损失
loss = -np.mean(np.sum(y_onehot * np.log(a2 + 1e-8), axis=1))
losses.append(loss)
# 反向
dz2 = (a2 - y_onehot) / len(X)
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0, keepdims=True)
da1 = dz2 @ W2.T
dz1 = da1 * (z1 > 0)
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0, keepdims=True)
# 更新
W2 -= lr * dW2
b2 -= lr * db2
W1 -= lr * dW1
b1 -= lr * db1
# 结果
preds = np.argmax(a2, axis=1)
acc = (preds == y).mean()
print(f"最终损失: {losses[-1]:.4f}, 准确率: {acc:.1%}")
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(losses)
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Loss')
axes[0].set_title('训练损失')
axes[1].scatter(X[:, 0], X[:, 1], c=preds, cmap='coolwarm', s=10, alpha=0.7)
axes[1].set_title(f'分类结果(准确率 {acc:.1%})')
plt.tight_layout()
plt.show()
5.1 为什么这段 NumPy 训练循环很值得反复看?
因为它其实就是后面 PyTorch 训练循环的裸版本:
- 前向
- 算 loss
- 反向
- 更新
所以你现在看懂这段,后面看到:
loss.backward()optimizer.step()
时就不会觉得那是凭空发生的黑箱。
小结
| 概念 | 要点 |
|---|---|
| 前向传播 | 输入→加权求和→激活→输出→损失 |
| 损失函数 | 回归用 MSE,分类用交叉熵 |
| 反向传播 | 链式法则从后往前算梯度 |
| 计算图 | 记录计算依赖,PyTorch 自动构建 |
这节最该带走什么
如果只带走一句话,我希望你记住:
反向传播不是在制造神秘公式,而是在系统地回答“模型错了以后,每个参数各自该改多少”。
所以这一节真正要稳住的是:
- 前向是在算结果
- 损失是在定义“错得多不多”
- 反向是在分配误差责任
- 梯度最终是为了更新参数
动手练习
练习 1:手动推导(纸笔)
对一个 1→2→1 的网络(Sigmoid 激活),输入 x=0.5,目标 y=1,手动计算一轮前向+反向传播,更新参数。
练习 2:数值梯度验证
修改完整训练循环,在第一轮时用数值梯度验证 dW1 的解析梯度是否正确(误差应小于 1e-5)。