E.A C++ and Model Deployment Roadmap
Use this elective when a Python model already works, but latency, memory, packaging, or serving cost becomes the real problem.
See the Deployment Path First
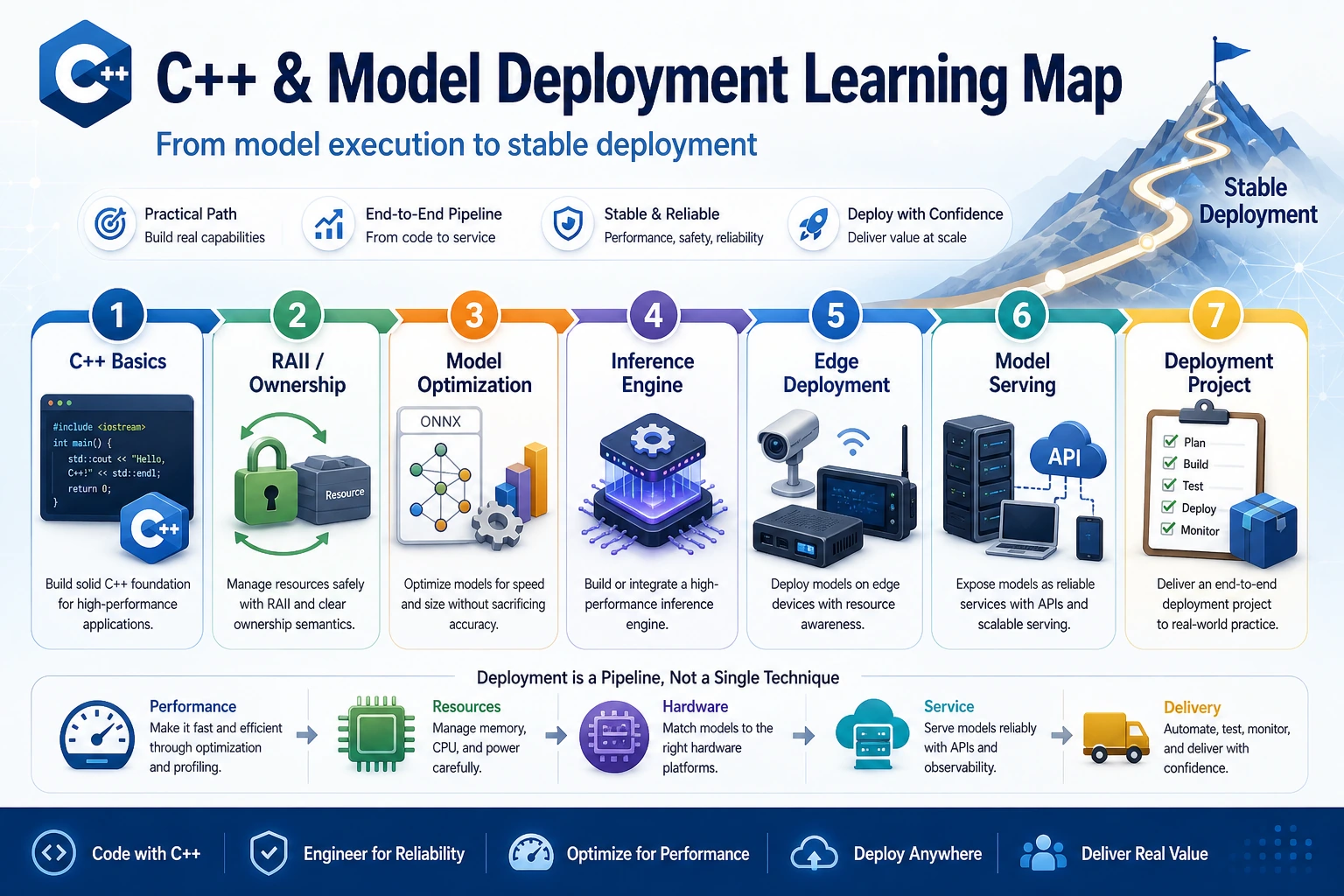
The core question is simple: can you turn model output into a fast, measurable, deployable inference path?
Run the Smallest C++ Inference Step
Create demo.cpp:
#include <iostream>
#include <vector>
int main() {
std::vector<float> logits = {1.2f, 0.3f, 2.1f};
int best_index = 0;
for (int i = 1; i < static_cast<int>(logits.size()); ++i) {
if (logits[i] > logits[best_index]) {
best_index = i;
}
}
std::cout << "best_class=" << best_index << "\n";
std::cout << "score=" << logits[best_index] << "\n";
return 0;
}
Run it:
c++ -std=c++17 demo.cpp -o demo
./demo
Expected output:
best_class=2
score=2.1
This is the smallest deployment habit: input tensor-like values, compute a decision, print a reproducible result.
Learn in This Order
| Step | Lesson | Practice Output |
|---|---|---|
| 1 | E.A.1 C++ Basics | Compile and run a tiny inference helper |
| 2 | E.A.2 Advanced C++ | Explain ownership, RAII, and safe resource release |
| 3 | E.A.3 Optimization | Compare latency, memory, and accuracy trade-offs |
| 4 | E.A.4 Inference Engines | Pick an engine based on hardware and model format |
| 5 | E.A.5 Edge Deployment | Name edge constraints and export a checklist |
| 6 | E.A.6 Model Serving | Design versioned serving with metrics |
| 7 | E.A.7 Project | Deliver a small deployment evidence pack |
Pass Check
You pass this module when you can compile one C++ example, explain the deployment trade-off, record latency or memory evidence, and connect the result to the Elective Hands-on Workshop.