E.A.6 Model Serving
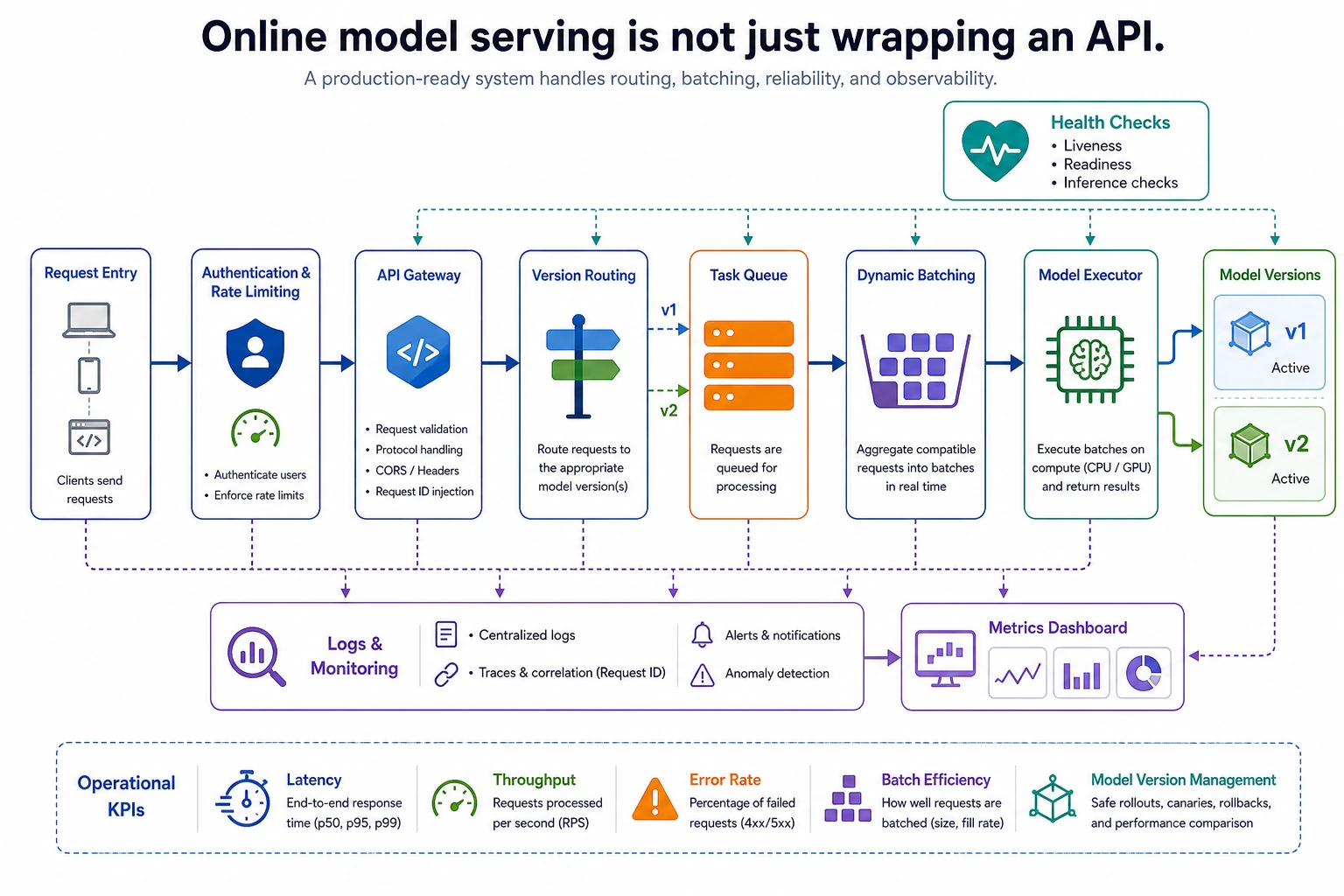
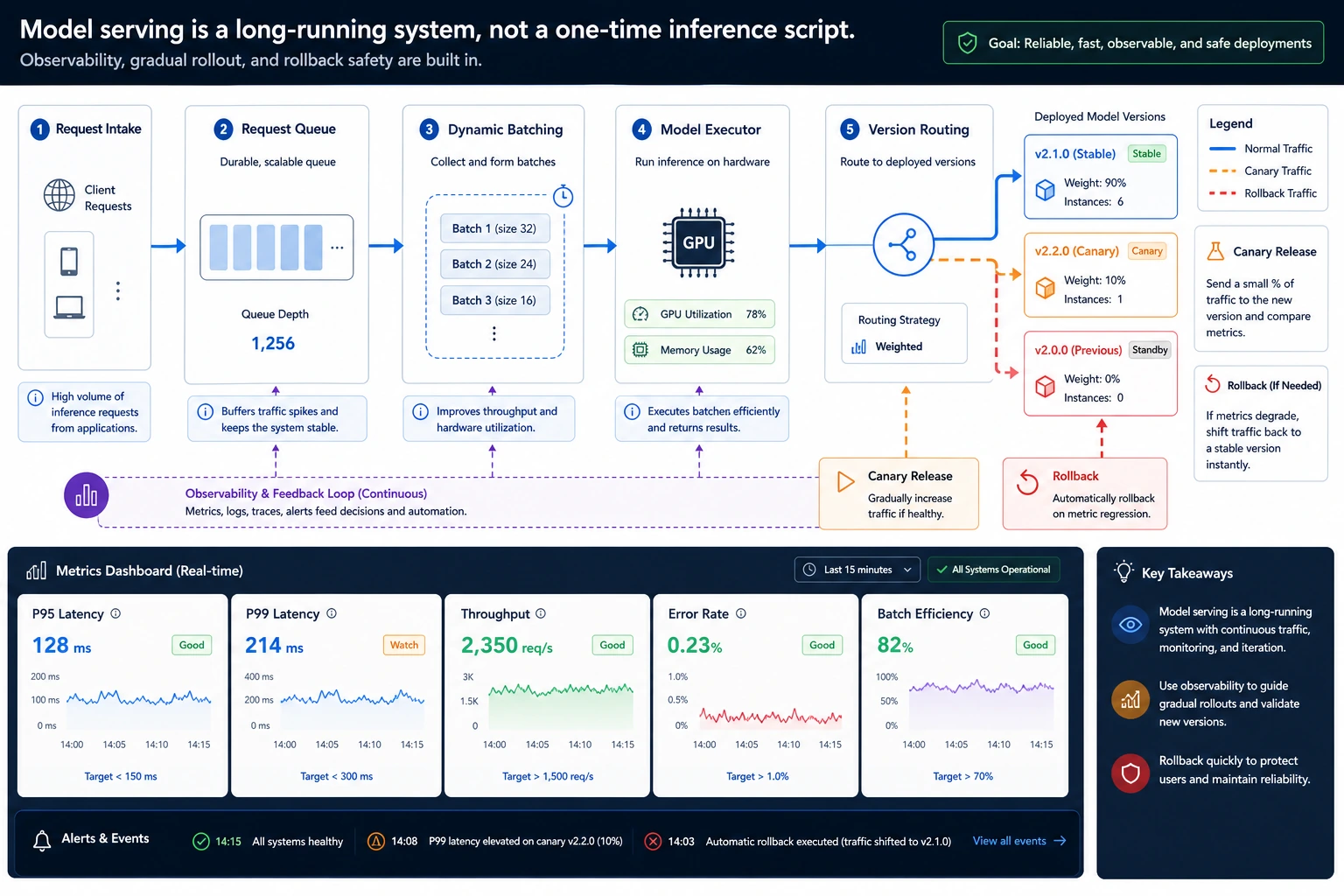
Serving a model is different from calling a model once. A service receives many requests, queues them, batches them, sends them to the right model version, records metrics, and stays recoverable when a version fails.
What You Need
- Python 3.10+
- No external packages
- Basic understanding of dictionaries and lists
Key Terms
- Queue: temporary waiting area for requests.
- Batch: multiple requests processed together.
- Version routing: sending traffic to
v1,v2, or a canary model. - P95 latency: 95% of requests finish within this time.
- Rollback: switching traffic back to a safer version.
Run A Tiny Serving Loop
Create serving_loop.py:
requests = [
{"id": 1, "version": "v1", "text": "refund"},
{"id": 2, "version": "v1", "text": "invoice"},
{"id": 3, "version": "v2", "text": "change address"},
{"id": 4, "version": "v2", "text": "shipping"},
{"id": 5, "version": "v1", "text": "certificate"},
]
batches = {}
for request in requests:
batches.setdefault(request["version"], []).append(request)
for version, items in batches.items():
print(version, "batch_size=", len(items), "ids=", [item["id"] for item in items])
for item in items:
item["answer"] = f"{version}:{item['text']}:ok"
print("answers:")
for request in requests:
print(request["id"], request["answer"])
Run it:
python serving_loop.py
Expected output:
v1 batch_size= 3 ids= [1, 2, 5]
v2 batch_size= 2 ids= [3, 4]
answers:
1 v1:refund:ok
2 v1:invoice:ok
3 v2:change address:ok
4 v2:shipping:ok
5 v1:certificate:ok
This small script shows the core loop: requests arrive, are grouped by version, processed in batches, and returned with traceable answers.
Add A Safety Rule
Add this before the batching loop:
requests = [
{"id": 1, "version": "v1", "text": "refund"},
{"id": 2, "version": "v1", "text": "invoice"},
{"id": 3, "version": "v2", "text": "change address"},
]
healthy_versions = {"v1": True, "v2": False}
routed_requests = [
request if healthy_versions[request["version"]] else {**request, "version": "v1"}
for request in requests
]
print([request["version"] for request in routed_requests])
Expected output:
['v1', 'v1', 'v1']
Run again. Requests that asked for unhealthy v2 now route back to v1. That is the basic idea behind health checks and rollback.
Metrics To Watch First
Track these before launch:
- Queue wait time
- Average and P95 latency
- Error rate
- Average batch size
- Traffic split by model version
Common Mistakes
- Reporting only model inference time and ignoring queue, preprocessing, and network time.
- Making batches too large and hurting user-facing latency.
- Replacing the production model without version routing.
- Keeping no request IDs, which makes debugging almost impossible.
Practice
Add a latency_ms field to each request, then compute average latency per version. If v2 is slower than v1 by more than 20 ms, route all future requests back to v1.