深度学习历史突破主线
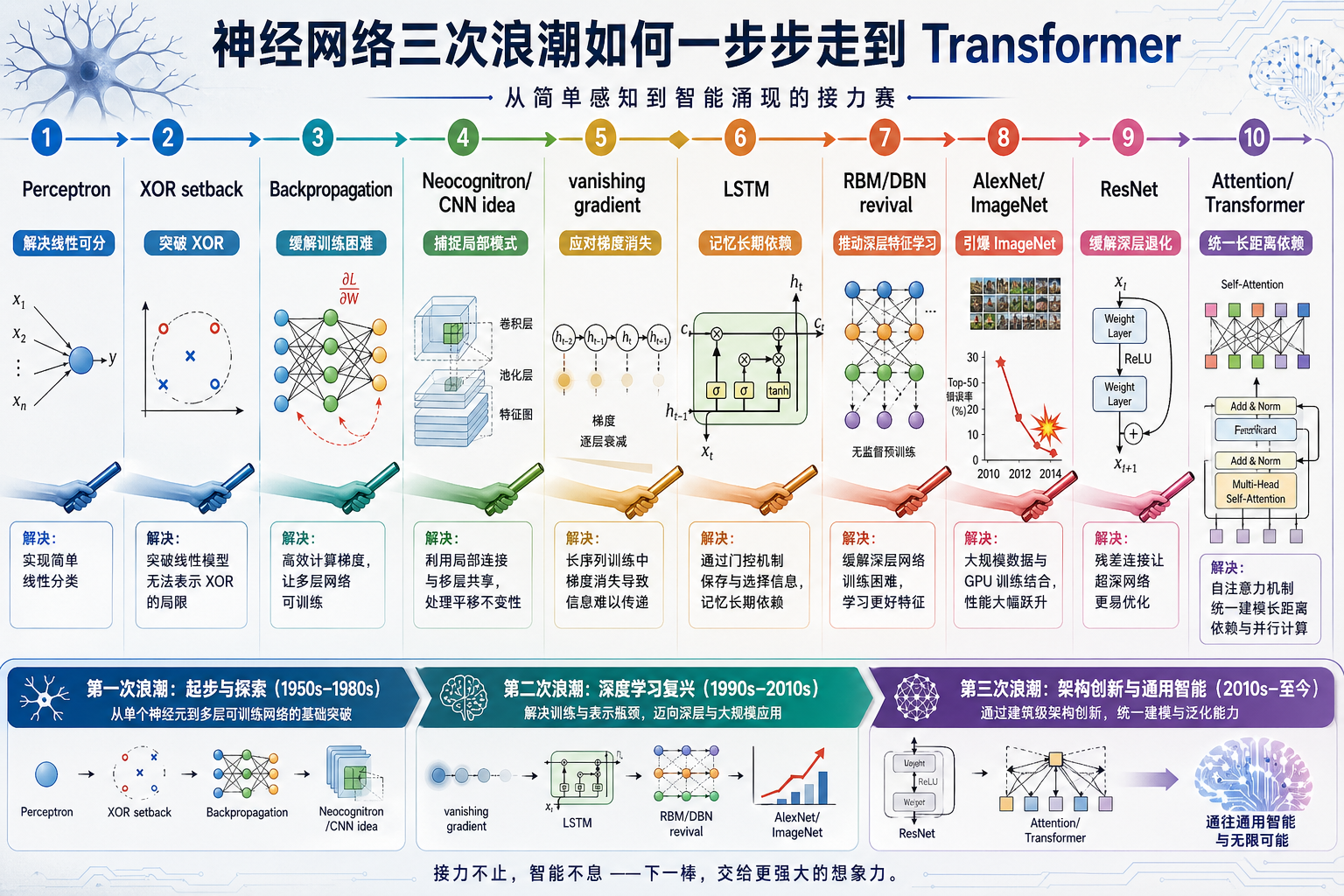
这一节帮你把第 6 章的模型名字放回历史脉络里。
你不需要背所有年份,但要看懂每一次突破都在回答一个问题:
为什么上一代方法不够用?新方法到底补上了什么?
一、先抓住深度学习历史的三次气氛变化
深度学习不是一路顺风顺水发展起来的。它更像经历了几次“燃起希望、遇到瓶颈、等待条件成熟、再次爆发”的循环。
| 阶段 | 当时的期待 | 主要瓶颈 | 后来的突破 |
|---|---|---|---|
| 第一波神经网络 | 感知器让机器能从数据学规则 | 单层模型表达能力有限,XOR 做不了 | 多层网络和反向传播 |
| 第�二波神经网络 | 反向传播让多层网络能训练 | 梯度消失、数据少、算力弱 | LSTM、初始化、预训练思想 |
| 深度学习复兴 | 数据、GPU、网络结构一起成熟 | 深层网络训练困难、序列建模瓶颈 | AlexNet、ResNet、Attention、Transformer |
这条历史线和第 6 章学习顺序高度对应:
| 历史问题 | 本章对应学习 |
|---|---|
| 单个神经元能做什么 | 1.4 从神经元到 MLP |
| 多层网络怎么训练 | 1.5 前向传播与反向传播 |
| 训练为什么不稳定 | 1.6 优化器、1.7 正则化、1.8 初始化 |
| CNN 为什么适合图像 | 3.2 卷积操作原理、3.4 经典 CNN |
| 图像为什么适合 CNN | 第三章 CNN |
| 序列为什么需要记忆机制 | 第四章 RNN / LSTM |
| 长依赖和并行训练怎么办 | 第五章 Attention / Transformer |
二、1943~1958:从人工神经元到感知器
1943 年,McCulloch 和 Pitts 提出了人工神经元的早期抽象:神经元可以接收输入,经过简单计算后输出结果。这个想法很粗糙,但它第一次把“大脑式计算”翻译成了可计算模型。
1958 年,Rosenblatt 提出感知器。感知器真正让人兴奋的地方是:
机器不只是执行人写好的规则,而是可以从样本中调整参数。
对新人来说,可以把感知器理解成最小神经元模型��:
输入特征 -> 加权求和 -> 激活判断 -> 输出类别
它和第 5 章线性模型很像,但它打开了神经网络这条路线:如果一个神经元能学一点规律,那很多神经元、多层结构能不能学更复杂的规律?
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 1.4 从神经元到 MLP | 神经元、权重、偏置、激活函数 |
| 第 5 章逻辑回归 | 线性打分和分类概率如何连接 |
三、1969:XOR 问题让第一波神经网络热潮冷下来
感知器的局限很快暴露出来。Minsky 和 Papert 指出,单层感知器无法解决 XOR 这种非线性可分问题。
XOR 的关键不是它有多复杂,而是它提醒大家:
只靠一条直线分不开的数据,单层模型学不了。
这件事的历史影响很大,因为它说明早期神经网络的表达能力远远不够。第一波神经网络热潮因此明显降温。
但从今天学习角度看,XOR 反而是一个特别好的教学例子:
| 问题 | 为什么重要 |
|---|---|
| 单层模型分不开 XOR | 说明线性边界有局限 |
| 加隐藏层可以解决 | 说明多层网络能组合出非线性 |
| 需要非线性激活 | 说明激活函数不是装饰,而是表达能力来源 |
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 1.4 从神经元到 MLP | 为什么多层和激活函数重要 |
| 第 5 章任务类型和决策边界 | 为什么线性模型不是万能 |
四、1980:新认知机提前埋下 CNN 的关键思想
在 AlexNet 之前很久,Fukushima 在 1980 年提出的新认知机(Neocognitron)就已经包含了后来 CNN 里非常重要的味道:
- 局部感受野:不用每个像素都和所有位置相连,而是先看局部区域
- 层级特征:先看简单边缘,再逐渐组合成更复杂形状
- 空间不变性直觉:同一个特征在不同位置出现,也应该能被识别
对新人来说,可以把它理解成:
图像不是一堆孤立像素,而是由局部纹理、边缘、形状一层层组合出来的。
新认知机没有直接变成今天的主流工程框架,但它让 CNN 的核心直觉很早就出现了。后来 LeNet、AlexNet、ResNet 继续把这条路线推向可训练、可扩展、可落地。
建议对应学习:
| ��对应位置 | 你要看懂什么 |
|---|---|
| 3.2 卷积操作原理 | 局部感受野、卷积核、特征图 |
| 3.4 经典 CNN 架构 | LeNet、AlexNet、ResNet 怎样继承和放大 CNN 思想 |
五、1986:反向传播让多层网络终于能有效训练
如果网络只有一层,参数怎么改还比较直观。但多层网络的问题是:前面层的参数对最终损失的影响很绕。
反向传播解决的就是这个核心问题:
把最终错误沿计算图一层层传回去,告诉每个参数该往哪个方向改。
它依赖第 4 章的链式法则,也构成第 6 章训练循环的发动机。
你可以把反向传播想成项目复盘:
| 训练动作 | 类比 |
|---|---|
| 前向传播 | 项目先做一次预测 |
| 计算 loss | 看结果和目标差多少 |
| 反向传播 | 追查每一步对错误贡献多少 |
| 优化器更新 | 根据责任分配调整参数 |
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 1.5 前向传播与反向传播 | 计算图、loss、gradient |
| PyTorch 自动求导 | loss.backward() 背后的含义 |
| 第 4 章链式法则 | 数学上为什么能反传 |
六、1989~1997:表达能力、梯度消失和 LSTM
1989 年,Cybenko 的通用逼近定理从理论上说明,带非线性的前馈网络具有很强的函数逼近能力。它给了神经网络路线一个重要信号:只要结构和训练合适,网络确实可以表示复杂函数。
但理论上能表示,不代表工程上好训练。1994 年,Bengio 等人系统指出长序列训练中的梯度消失问题。普通 RNN 在处理长文本或长时间序列时,很容易把早期信息“忘掉”,梯度也难以稳定传回很久以前的时间步。
1997 年,LSTM 用门控机制缓解了这个问题。你可以把 LSTM 想成给 RNN 加了一个更可靠的记忆本:
| 模型 | 解决的问题 |
|---|---|
| 普通 RNN | 能处理顺序,但容易忘远处信息 |
| LSTM | 用门控控制记什么、忘什么、输出什么 |
| GRU | 用更简化的门控结构实现类似能力 |
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 1.8 权重初始化 | 为什么信号和梯度稳定很重要 |
| 4.2 RNN 基础 | 序列建模和隐藏状态 |
| 4.3 LSTM 与 GRU | 门控如何缓解长期依赖 |
七、2006:RBM / DBN 让深层网络重新被重视
2006 年左右,Hinton 等人的 Deep Belief Nets 和 RBM 预训练工作让深层网络再次引起关注。那时深层网络直接训练并不容易,预训练提供了一种“先逐层学表示,再微调任务”的思路。
今天你不一定需要在项目里手写 RBM,但它的历史意义在于:
它让大家重新相信,多层表示学习可能是可行的。
这也是“深度学习复兴”的重要前奏之一。后来数据规模、GPU、初始化、正则化、优化器、网络结构一起成熟,深度学习才真正爆发。
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 训练技巧 | 为什么深层网络需要初始化、正则化和诊断 |
| 生成模型选修 | RBM、VAE、GAN 都属于学习数据分布的不同思路 |
| 第 7 章预训练 | “先学通用表示,再迁移任务”的思想延续 |
八、2012~2015:AlexNet、ImageNet 和 ResNet 让深度学习真正打穿视觉任务
2012 年,AlexNet 在 ImageNet 图像分类比赛中取得突破性成绩。这次突破不只是模型结构本身,而是多个条件同时成熟:
- 大规模标注数据集 ImageNet
- GPU 加速训练
- 更深的 CNN
- ReLU、Dropout、数据增强等��训练技巧
AlexNet 让很多人意识到:深度学习在视觉任务上真的可以明显超过传统方案。
2015 年,ResNet 用残差连接解决了深层网络难训练的问题。残差连接的直觉是:不要强迫每一层都从零学完整变换,而是让它学习“相对输入要改多少”。
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 3.2 卷积操作原理 | CNN 为什么适合图像 |
| 3.4 经典 CNN 架构 | LeNet、AlexNet、VGG、ResNet 的演进 |
| 3.5 迁移学习 | 为什么预训练视觉模型可以迁移到新任务 |
| 第 10 章计算机视觉 | 图像分类、检测、分割如何继续发展 |
九、2017:Attention 和 Transformer 改写序列建模主线
RNN 和 LSTM 按顺序处理序列,有一个天然问题:难并行,长距离信息路径也长。Transformer 的突破在于:
用 self-attention 让序列中任意位置可以直接建立联系。
Attention Is All You Need 这篇论文不只是提出一个新模型,而是改变了后面 NLP、大模型和多模态系统的底座。
Transformer 解决了几个关键问题:
| 旧问题 | Transformer 的变化 |
|---|---|
| RNN 按顺序算,不容易并行 | Self-Attention 可以并行处理 token |
| 长距离依赖路径太长 | 注意力让远处 token 直接相互关注 |
| 不同任务结构分散 | Encoder、Decoder 和预训练范式统一很多任务 |
建议对应学习:
| 对应位置 | 你要看懂什么 |
|---|---|
| 5.2 注意力机制 | Q/K/V 和 self-attention |
| 5.3 Transformer 架构 | Block、残差、LayerNorm、FFN |
| 第 7 章大模型原理 | Transformer 如何变成 LLM 底座 |
| 第 8~9 章 RAG / Agent | 大模型如何接入知识和工具 |
十、把深度学习突破分配到第 6 章学习路径
| 历史突破 | 解决的问题 | 本课程对应章节 |
|---|---|---|
| McCulloch-Pitts / Perceptron | 神经元可计算、参数可学习 | 1.4 从神经元到 MLP |
| XOR 局限 | 单层线性模型表达能力不足 | 1.4 MLP、激活函数 |
| Neocognitron | 局部感受野和层级视觉特征 | 3.2 卷积操作、3.4 经典 CNN |
| Backpropagation | 多层网络如何分配错误并更新参数 | 1.5 前向传播与反向传播、PyTorch autograd |
| Cybenko 通用逼近 | 多层非线性网络具备强表达能力 | 1.4 MLP 背景 |
| 梯度消失 | 深层/长序列训练不稳定 | 1.8 初始化、4.3 LSTM |
| LSTM / GRU | 长序列记忆和门控控制 | 第四章 RNN 与序列模型 |
| RBM / DBN | 深层网络重新可训练的历史前奏 | 生成模型、预训练背景 |
| AlexNet / ImageNet | 数据 + GPU + CNN 打穿视觉任务 | 第三章 CNN、第 10 章视觉 |
| ResNet | 深层 CNN 训练困难 | 3.4 经典 CNN 架构 |
| Attention / Transformer | 长依赖、并行训练和统一序列建模 | 第五章 Transformer、第 7 章 LLM |
十一、学完这一节应该形成的直觉
深度学习历史不是一堆模型名字,而是一条连续的问题链:
| 老问题 | 新突破 | 你现在要练的能力 |
|---|---|---|
| 规则写不完 | 感知器和神经元 | 理解参数学习 |
| 单层模型太弱 | 多层网络和激活函数 | 理解表达能力 |
| 多层网络难训练 | 反向传播 | 理解训练循环 |
| 长序列记不住 | LSTM / GRU | 理解门控记忆 |
| 图像任务难做 | CNN / AlexNet / ResNet | 理解局部特征和深层结构 |
| 序列难并行、长依赖难 | Attention / Transformer | 理解大模型底座 |
如果你能把每个模型名都回答成“它解决了上一代什么问题”,第 6 章就不会变成架构清单,而会变成一条清晰的技术演进路线。