6.4.4 序列建模实战
本节定位
这一节把序列建模变成一个小项目:把连续序列切成滑动窗口样本,训练 LSTM,对比 naive baseline,并检查验证集预测。
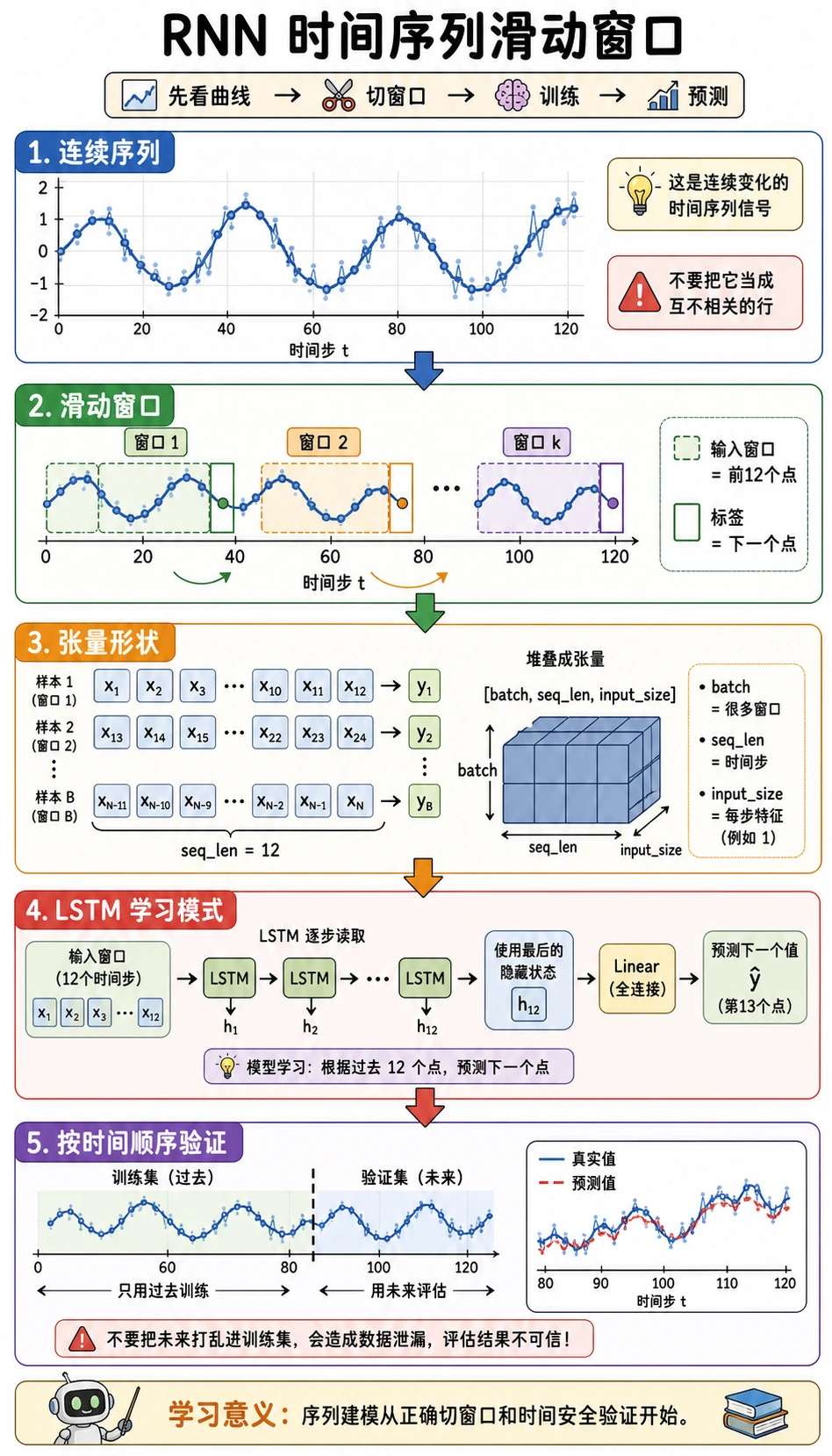
学习目标
- 把连续时间序列转换成监督学习样本。
- 保持 LSTM 输入为
[batch, seq_len, input_size]。 - 按时间顺序切分验证集,避免未来信息泄漏。
- 训练 LSTM 预测器,并和 naive baseline 对比。
- 读懂验证 loss 和预测样本。
核心流程
连续序列 -> 滑动窗口 -> 时间顺序切分 -> LSTM -> 验证 MSE -> 预测检查
时间序列默认不要随机切分。如果未来数据泄漏进训练集,验证结果会过于乐观。
一分钟看懂滑动窗口
如果 window_size = 3:
series: [1, 2, 3, 4, 5, 6]
X[0] = [1, 2, 3] -> y[0] = 4
X[1] = [2, 3, 4] -> y[1] = 5
X[2] = [3, 4, 5] -> y[2] = 6
这就是连续序列变成训练样本的方式。
完整实验:LSTM 预测
合成序列由两个波形和噪声组成。它仍然很小,但比完美正弦波更接近真实数据。
import numpy as np
import torch
from torch import nn
np.random.seed(42)
torch.manual_seed(42)
def make_windows(series, window_size):
X, y = [], []
for i in range(len(series) - window_size):
X.append(series[i : i + window_size])
y.append(series[i + window_size])
X = torch.tensor(np.array(X), dtype=torch.float32).unsqueeze(-1)
y = torch.tensor(np.array(y), dtype=torch.float32).unsqueeze(-1)
return X, y
t = np.arange(0, 220)
series = (
np.sin(t * 0.12)
+ 0.25 * np.sin(t * 0.03)
+ np.random.randn(len(t)) * 0.04
).astype(np.float32)
window_size = 16
X, y = make_windows(series, window_size)
split = int(len(X) * 0.8)
X_train, X_val = X[:split], X[split:]
y_train, y_val = y[:split], y[split:]
print("window_lab")
print("X:", tuple(X.shape), "y:", tuple(y.shape))
print("train:", tuple(X_train.shape), "val:", tuple(X_val.shape))
naive_val = ((X_val[:, -1, :] - y_val) ** 2).mean().item()
print("naive_val_mse:", round(naive_val, 4))
class LSTMForecaster(nn.Module):
def __init__(self, hidden_size=32):
super().__init__()
self.lstm = nn.LSTM(1, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMForecaster(32)
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(1, 121):
model.train()
pred = model(X_train)
loss = loss_fn(pred, y_train)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
if epoch == 1 or epoch % 30 == 0:
model.eval()
with torch.no_grad():
val_loss = loss_fn(model(X_val), y_val)
print(f"epoch={epoch:03d} train_mse={loss.item():.4f} val_mse={val_loss.item():.4f}")
model.eval()
with torch.no_grad():
val_pred = model(X_val)
print("first_5_pred:", [round(v, 3) for v in val_pred[:5, 0].tolist()])
print("first_5_true:", [round(v, 3) for v in y_val[:5, 0].tolist()])
预期输出:
window_lab
X: (204, 16, 1) y: (204, 1)
train: (163, 16, 1) val: (41, 16, 1)
naive_val_mse: 0.0115
epoch=001 train_mse=0.5168 val_mse=0.4633
epoch=030 train_mse=0.0049 val_mse=0.0046
epoch=060 train_mse=0.0032 val_mse=0.0035
epoch=090 train_mse=0.0029 val_mse=0.0032
epoch=120 train_mse=0.0028 val_mse=0.0030
first_5_pred: [0.323, 0.261, 0.145, -0.025, -0.192]
first_5_true: [0.4, 0.213, 0.045, -0.076, -0.128]
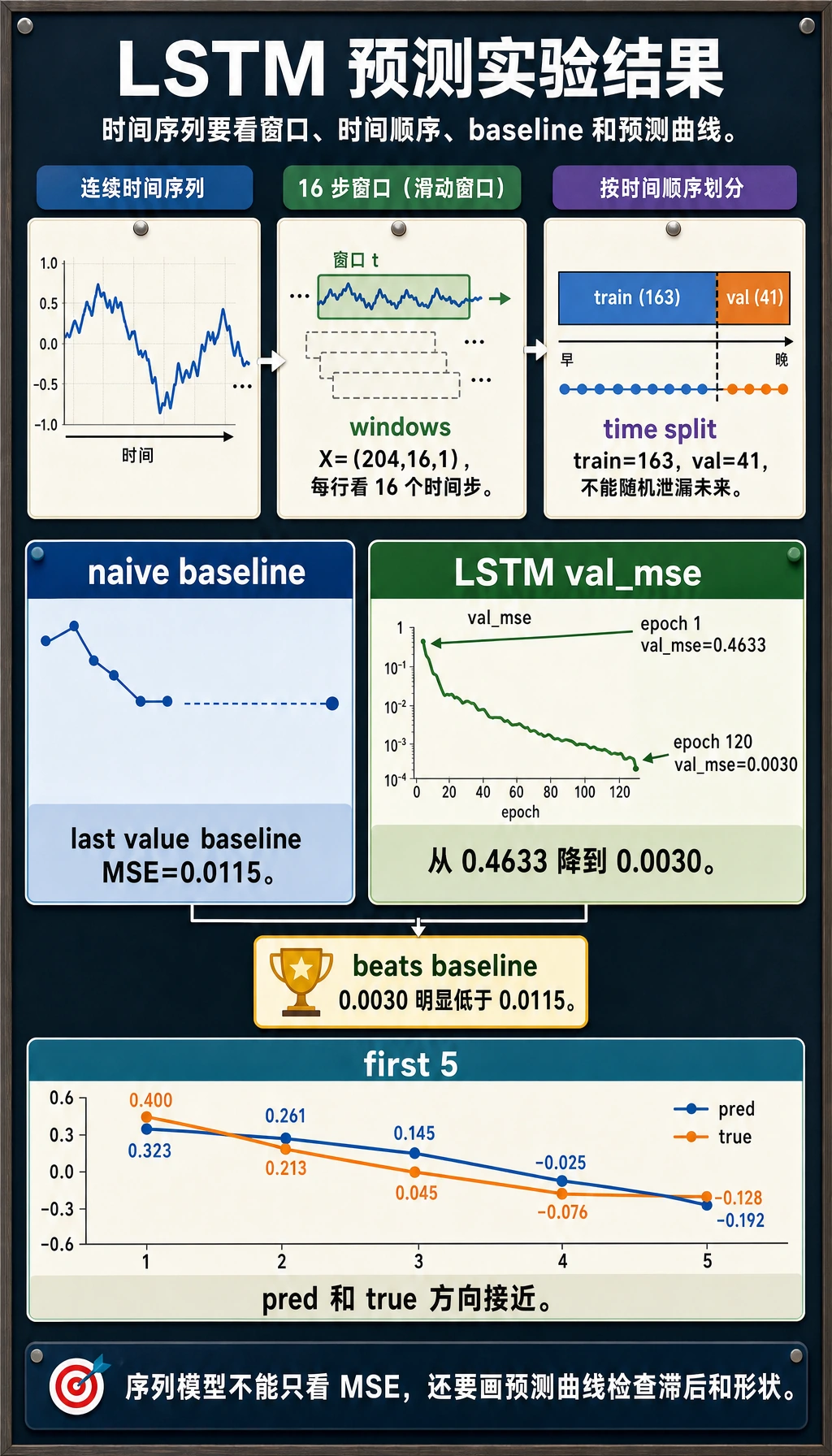
读懂输出
| 输出 | 含义 |
|---|---|
X: (204, 16, 1) | 204 个窗口,每个 16 个时间步,每步 1 个特征 |
train: (163, 16, 1) | 前 80% 窗口用于训练 |
val: (41, 16, 1) | 后面的窗口用于验证 |
naive_val_mse | baseline:直接用最后一个观测值预测下一个值 |
val_mse | LSTM 验证误差 |
first_5_pred vs first_5_true | 快速检查方向和数值尺度 |
这次 LSTM 超过了 naive baseline(0.0030 vs 0.0115)。这很重要:一个模型至少应该打过简单 baseline,才值得继续信任。
为什么使用梯度裁剪?
RNN 风格模型有时会出现较大梯度。这一行会限制总梯度范数:
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
它不是每次都必须,但在序列模型里是一个很实用的安全习惯。
在 Notebook 里应该画什么
在 Notebook 中补上:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
plt.plot(y_val.squeeze(-1).numpy(), label="true")
plt.plot(val_pred.squeeze(-1).numpy(), label="pred")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
重点看:
- lag:预测形状对,但整体滞后;
- flatline:模型只预测平均值;
- missed peaks:窗口太短或模型太弱;
- noisy prediction:学习率、数据噪声或过拟合问题。
常见坑
| 坑 | 为什么有问题 | 修复 |
|---|---|---|
| 随机切分 train/val | 未来信息泄漏进训练 | 按时间顺序切分 |
| window 太短 | 模型看不到足够上下文 | 尝试更大 window_size |
| window 太长 | 优化更难,噪声更多 | 对比验证 loss |
| 没有 baseline | 模型看似不错但可能很平庸 | 和最后值 baseline 对比 |
| 只看 MSE | 趋势可能滞后或变平 | 画预测曲线 |
| 真实数据不做缩放 | 大范围数值会让训练不稳 | 只用训练集统计量做归一化 |
从玩具序列到真实项目
真实序列项目可能会有:
- 每个时间步多个特征;
- 缺失值处理;
- 只基于训练集的归一化;
- rolling-origin validation;
- GRU、Temporal CNN、Transformer 或统计 baseline;
- 业务指标,而不只是 MSE。
但流程不变:定义窗口、保护时间顺序、对比 baseline、检查预测。
练习
- 把
window_size改成8和32,哪个验证 MSE 更好? - 把
nn.LSTM换成nn.GRU,训练速度或曲线有什么不同? - 移除梯度裁剪,训练还稳定吗?
- 增加第二个特征,例如
np.cos(t * 0.12)。 - 实现 rolling forecast,把预测值喂回下一个窗口。
小结
- 滑动窗口把连续序列变成监督学习样本。
- 按时间验证可以避免未来信息泄漏。
- 有意义的评估必须包含 naive baseline。
- LSTM 输入使用
[batch, seq_len, input_size]。 - 曲线图和预测样本经常能暴露单个 loss 数值看不到的问题。