6.4.3 LSTM 与 GRU
本节定位
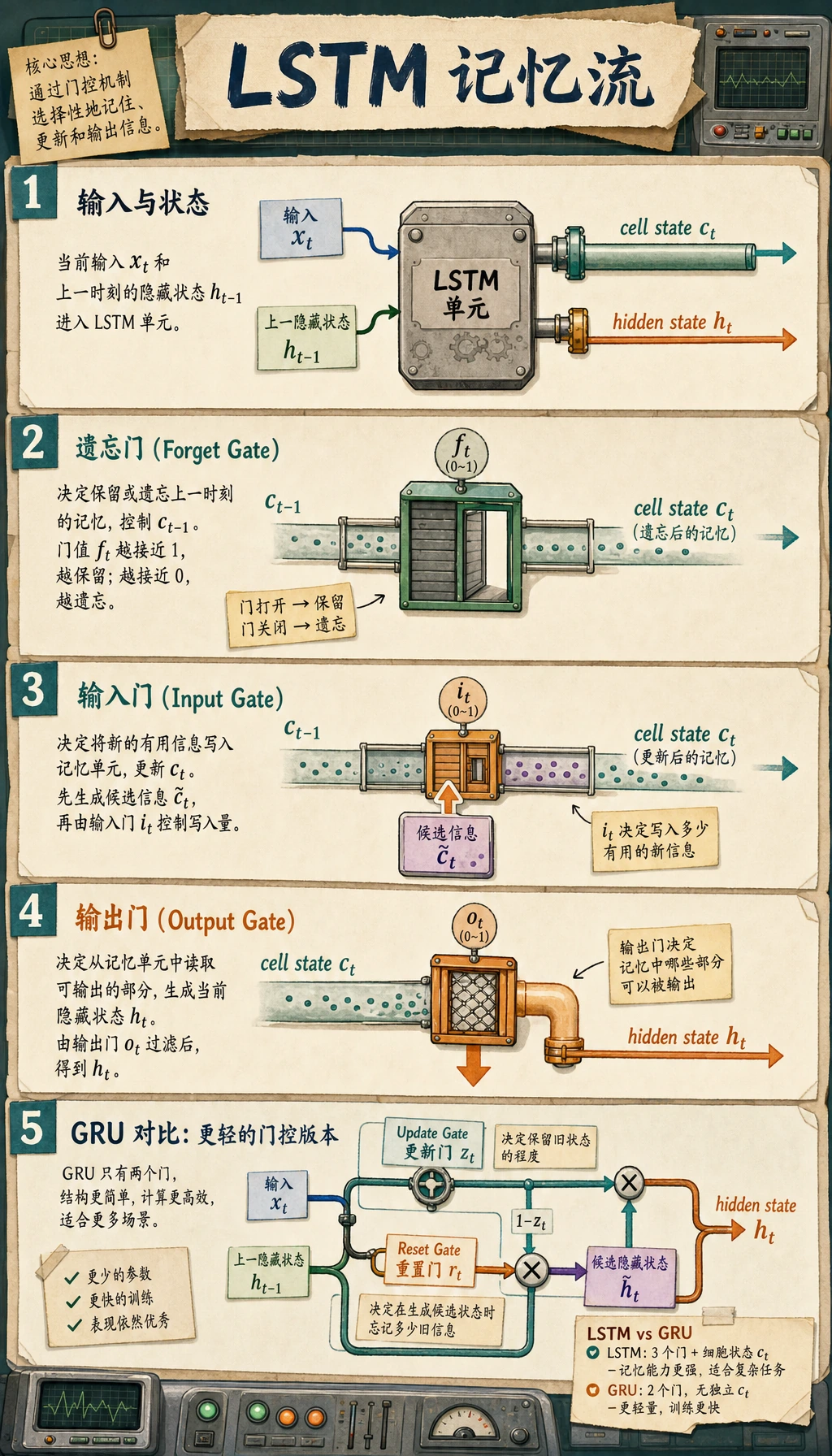
普通 RNN 有记忆,但这份记忆很容易被覆盖。LSTM 和 GRU 加入门控,让模型学习哪些该保留、哪些该忘掉、哪些该作为输出暴露出去。
学习目标
- 解释普通 RNN 为什么难处理长依赖。
- 理解 LSTM 的 cell state
c_t和 hidden stateh_t。 - 解释 forget、input、output、update、reset 这些 gate。
- 跑通 PyTorch 的
nn.LSTM和nn.GRUshape 检查。 - 在一个记忆任务上训练小型门控循环模型。
先看 gate 的想法
按这个方式读图:
旧记忆 -> gate 决定保留什么 -> 新信息写入 -> 输出暴露一部分记忆
gate 是模型学出来的 0 到 1 之间的值。
| gate 值 | 含义 |
|---|---|
接近 0 | 基本挡住信息 |
接近 1 | 基本让信息通过 |
这就是它和普通 RNN 的实践差别:记忆不再只是每一步被简单覆盖。
为什么普通 RNN 不够
普通 RNN 把过去压缩进一个 hidden state。短序列还可以,长序列会出现两个问题:
| 问题 | 直觉 |
|---|---|
| 早期信息被冲淡 | hidden state 被反复改写很多次 |
| 梯度消失 | 训练信号往很早的时间步回传时变弱 |
LSTM 和 GRU 不是“更深的 RNN”,而是“更会管理记忆的 RNN”。
LSTM:cell state 加三道门

LSTM 保留两种状态:
| 状态 | 作用 |
|---|---|
c_t | cell state,更像长期记忆通道 |
h_t | hidden state,当前时间步对外暴露的输出 |
三道主要的门:
| 门 | 它回答的问题 |
|---|---|
| forget gate | 旧记忆保留多少? |
| input gate | 新信息写入多少? |
| output gate | 当前暴露多少记忆? |
实验 1:标量 LSTM gate 演示
这个标量版本不用矩阵符号,更容易看清本质。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
c_prev = 0.8
forget_gate = sigmoid(1.0)
input_gate = sigmoid(0.2)
output_gate = sigmoid(0.7)
c_tilde = np.tanh(0.9)
c_t = forget_gate * c_prev + input_gate * c_tilde
h_t = output_gate * np.tanh(c_t)
print("scalar_lstm_lab")
for name, value in [
("forget_gate", forget_gate),
("input_gate", input_gate),
("output_gate", output_gate),
("c_t", c_t),
("h_t", h_t),
]:
print(f"{name:<12} {float(value):.4f}")
预期输出:
scalar_lstm_lab
forget_gate 0.7311
input_gate 0.5498
output_gate 0.6682
c_t 0.9787
h_t 0.5028
把更新读成:
新的 cell memory = 保留一部分旧记忆 + 写入一部分新候选信息
这就是 LSTM 的核心。
GRU:更轻的门控模型
GRU 比 LSTM 更简洁。它不单独保留 cell state,而是由 hidden state 承担记忆。
| 门 | 作用 |
|---|---|
| update gate | 控制旧状态和新候选状态混合多少 |
| reset gate | 控制生成候选状态时使用多少旧状态 |
实验 2:标量 GRU gate 演示
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
h_prev = 0.7
x_t = 1.1
update_gate = sigmoid(0.8)
reset_gate = sigmoid(-0.3)
h_candidate = np.tanh(x_t + reset_gate * h_prev)
h_t = (1 - update_gate) * h_prev + update_gate * h_candidate
print("scalar_gru_lab")
for name, value in [
("update_gate", update_gate),
("reset_gate", reset_gate),
("h_candidate", h_candidate),
("h_t", h_t),
]:
print(f"{name:<12} {float(value):.4f}")
预期输出:
scalar_gru_lab
update_gate 0.6900
reset_gate 0.4256
h_candidate 0.8849
h_t 0.8276
快速记忆:
LSTM = 更显式的记忆管理
GRU = 更轻量的门控记忆管理
实验 3:PyTorch LSTM 和 GRU shape
import torch
from torch import nn
torch.manual_seed(42)
x = torch.randn(4, 6, 8)
lstm = nn.LSTM(input_size=8, hidden_size=16, batch_first=True)
gru = nn.GRU(input_size=8, hidden_size=16, batch_first=True)
lstm_out, (lstm_h, lstm_c) = lstm(x)
gru_out, gru_h = gru(x)
print("shape_lab")
print("lstm_out:", tuple(lstm_out.shape))
print("lstm_h :", tuple(lstm_h.shape))
print("lstm_c :", tuple(lstm_c.shape))
print("gru_out :", tuple(gru_out.shape))
print("gru_h :", tuple(gru_h.shape))
预期输出:
shape_lab
lstm_out: (4, 6, 16)
lstm_h : (1, 4, 16)
lstm_c : (1, 4, 16)
gru_out : (4, 6, 16)
gru_h : (1, 4, 16)
最明显的 API 差异:
- LSTM 返回
(h, c); - GRU 只返回
h。
实验 4:训练一个记忆任务
标签取决于序列第一个值。中间值是噪声,所以模型必须保留早期信息。
import torch
from torch import nn
torch.manual_seed(42)
def build_dataset(n=160, seq_len=10):
X, y = [], []
for _ in range(n):
first = 1.0 if torch.rand(1).item() > 0.5 else -1.0
seq = torch.randn(seq_len, 1) * 0.25
seq[0, 0] = first
X.append(seq)
y.append(1 if first > 0 else 0)
return torch.stack(X), torch.tensor(y)
X, y = build_dataset()
class GRUClassifier(nn.Module):
def __init__(self):
super().__init__()
self.gru = nn.GRU(input_size=1, hidden_size=8, batch_first=True)
self.fc = nn.Linear(8, 2)
def forward(self, x):
out, h = self.gru(x)
return self.fc(h[-1])
model = GRUClassifier()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
for epoch in range(1, 81):
logits = model(X)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch == 1 or epoch % 20 == 0:
acc = (logits.argmax(1) == y).float().mean().item()
print(f"memory epoch={epoch:02d} loss={loss.item():.4f} acc={acc:.3f}")
with torch.no_grad():
final_acc = (model(X).argmax(1) == y).float().mean().item()
print("final_acc", round(final_acc, 3))
预期输出:
memory epoch=01 loss=0.7465 acc=0.431
memory epoch=20 loss=0.6691 acc=0.569
memory epoch=40 loss=0.0023 acc=1.000
memory epoch=60 loss=0.0001 acc=1.000
memory epoch=80 loss=0.0001 acc=1.000
final_acc 1.0
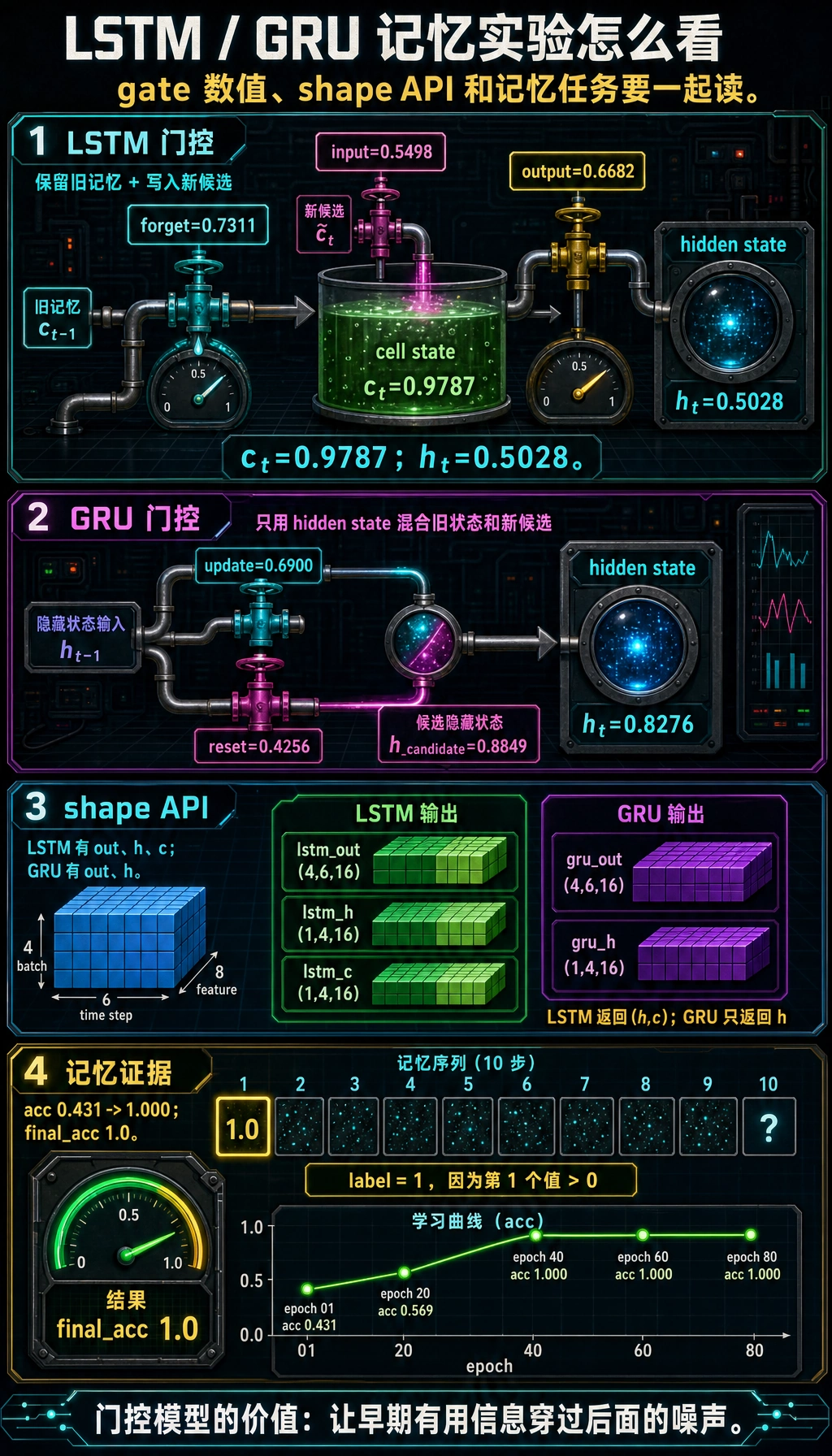
看证据,不只是看 print
gate 数值说明状态怎样被混合,shape 检查说明 PyTorch API 的返回约定,记忆曲线则证明模型学会了把第一个时间步的信号穿过后面的噪声。
这个任务很小,但它抓住了门控循环模型存在的原因:模型需要在后面一串噪声步骤中保留有用的早期信息。
LSTM 还是 GRU?
| 情况 | 推荐起点 |
|---|---|
| 快速 baseline | GRU |
| 模型预算小 | GRU |
| 长依赖是核心 | LSTM 和 GRU 都值得试 |
| 需要显式理解 cell state | LSTM |
| 现代长文本任务 | 通常优先 Transformer |
实际项目里看验证结果。架构名字没有“是否适合数据和部署约束”重要。
常见错误
| 错误 | 修复 |
|---|---|
| 以为 LSTM/GRU 只是更深的 RNN | 想成“记忆控制”,不是深度 |
搞混 out、h、c | out 是每步输出,h 是最终 hidden,c 是 LSTM cell state |
| 以为 gate 永远不会忘重要信息 | gate 是学出来的,也可能失败 |
| 不稳定序列上学习率过高 | 降低 LR,必要时做 gradient clipping |
| 只看训练准确率 | 用保留序列做验证 |
练习
- 在实验 1 中,把
sigmoid(1.0)改成sigmoid(-1.0),c_t怎么变? - 把记忆任务改成标签依赖最后一个值,会不会更容易?
- 把
GRUClassifier改成LSTMClassifier,比较输出 API。 - 把
seq_len从10增加到30,训练会不会更难? - 解释为什么 GRU 状态更少,但很多任务仍然效果不错。
小结
- LSTM 和 GRU 用 gate 控制记忆流。
- LSTM 同时有
c_t和h_t;GRU 使用更轻的 hidden-state 设计。 - gate 是
0到1之间学出来的软开关。 - LSTM 和 GRU 的选择要看验证结果。
- 门控循环模型是从普通 RNN 走向 attention 序列建模的重要桥梁。