6.4.3 LSTM と GRU
普通の RNN には記憶がありますが、その記憶は上書きされやすいです。LSTM と GRU は gate を追加し、何を残し、何を忘れ、何を出力として見せるかをモデルに学ばせます。
学習目標
- 普通の RNN が長期依存を苦手とする理由を説明できる。
- LSTM の cell state
c_tと hidden stateh_tを理解できる。 - forget、input、output、update、reset gate を説明できる。
- PyTorch の
nn.LSTMとnn.GRUの shape を確認できる。 - 小さな記憶タスクで gated recurrent model を学習できる。
まず gate の考え方を見る
図は次のように読みます。
古い記憶 -> gate が残すものを決める -> 新情報を書く -> 出力が記憶の一部を見せる
Gate は、モデルが学習する 0 から 1 までの値です。
| gate 値 | 意味 |
|---|---|
0 に近い | 情報をほぼ止める |
1 に近い | 情報をほぼ通す |
これが普通の RNN との実践的な違いです。記憶が毎ステップ単純に上書きされるだけではなくなります。
なぜ普通の RNN では足りないのか
普通の RNN は、過去を 1 つの hidden state に圧縮します。短い系列なら機能しますが、長い系列では 2 つの問題が出ます。
| 問題 | 直感 |
|---|---|
| 早い情報が薄まる | hidden state が何度も書き換えられる |
| 勾配消失 | 学習信号が時間を遠くさかのぼるほど弱くなる |
LSTM と GRU は「より深い RNN」ではありません。記憶を制御する設計です。
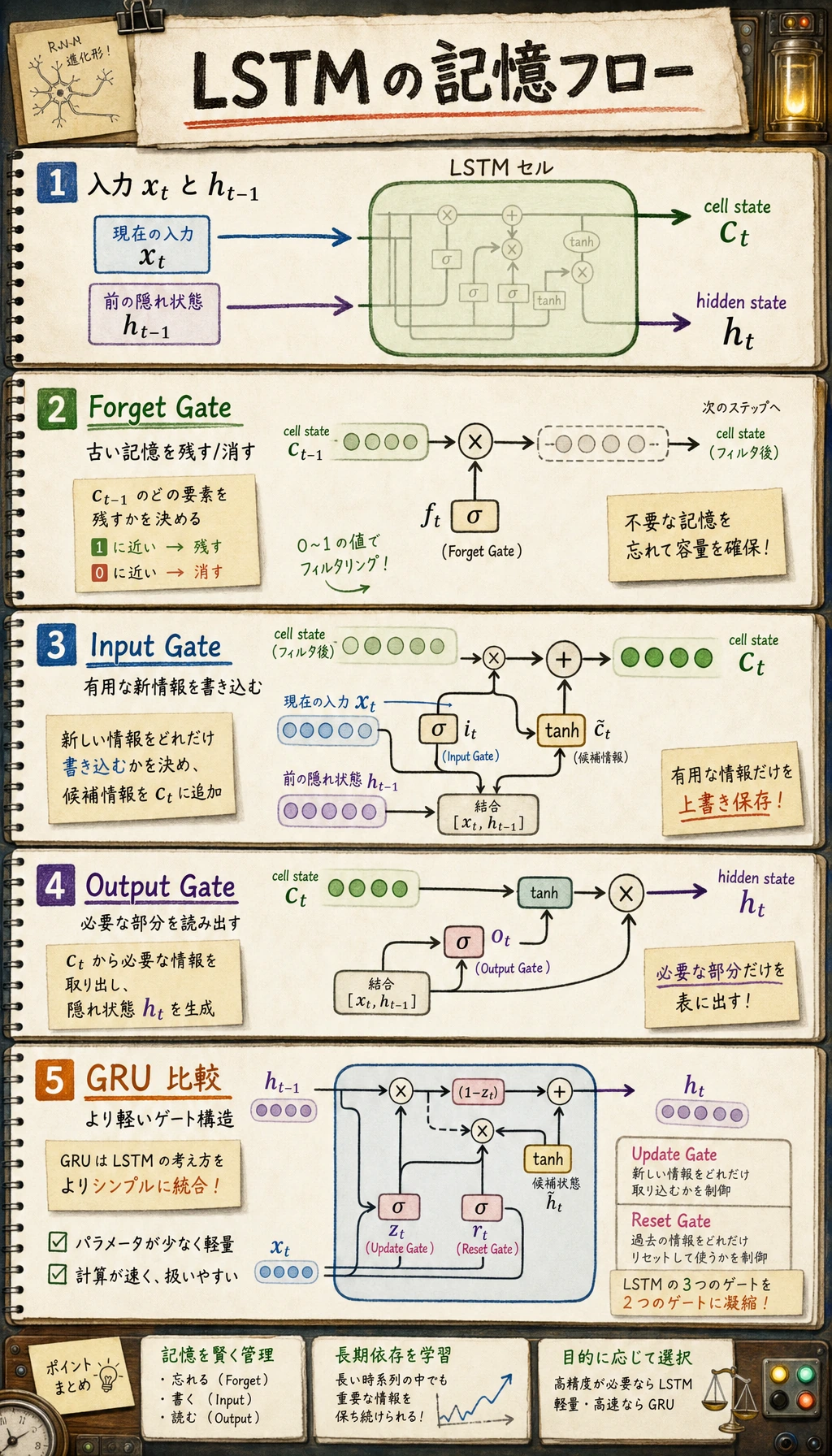
LSTM:Cell State と 3 つの Gate
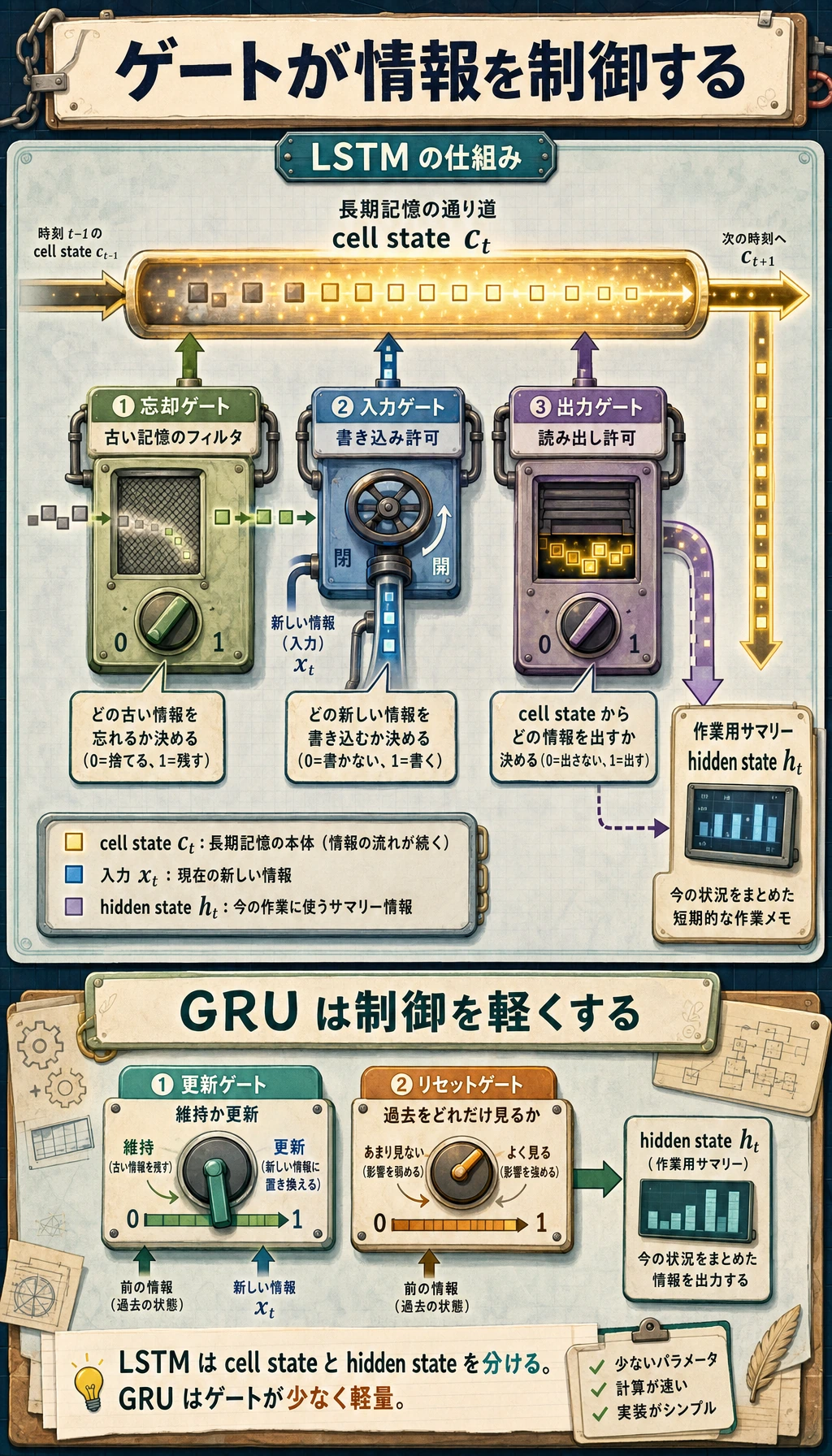
LSTM は 2 つの状態を持ちます。
| 状態 | 役割 |
|---|---|
c_t | cell state。より長期的な記憶の通り道 |
h_t | hidden state。現在のステップで外に見せる出力 |
主な 3 つの gate:
| Gate | 答える問い |
|---|---|
| forget gate | 古い記憶をどれだけ残すか |
| input gate | 新しい情報をどれだけ書くか |
| output gate | 今どれだけ記憶を外に見せるか |
実験 1:スカラー LSTM Gate デモ
このスカラー版では、行列記法なしで考え方が見えます。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
c_prev = 0.8
forget_gate = sigmoid(1.0)
input_gate = sigmoid(0.2)
output_gate = sigmoid(0.7)
c_tilde = np.tanh(0.9)
c_t = forget_gate * c_prev + input_gate * c_tilde
h_t = output_gate * np.tanh(c_t)
print("scalar_lstm_lab")
for name, value in [
("forget_gate", forget_gate),
("input_gate", input_gate),
("output_gate", output_gate),
("c_t", c_t),
("h_t", h_t),
]:
print(f"{name:<12} {float(value):.4f}")
期待される出力:
scalar_lstm_lab
forget_gate 0.7311
input_gate 0.5498
output_gate 0.6682
c_t 0.9787
h_t 0.5028
更新はこう読みます。
新しい cell memory = 古い記憶の一部を保持 + 新しい候補情報の一部を書き込み
これが LSTM の中心です。
GRU:より軽い Gate 付きモデル
GRU は LSTM より構成が軽いです。別の cell state は持たず、hidden state が記憶を担います。
| Gate | 役割 |
|---|---|
| update gate | 古い状態と新しい候補をどれだけ混ぜるかを制御 |
| reset gate | 候補を作るとき、古い状態をどれだけ使うかを制御 |
実験 2:スカラー GRU Gate デモ
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
h_prev = 0.7
x_t = 1.1
update_gate = sigmoid(0.8)
reset_gate = sigmoid(-0.3)
h_candidate = np.tanh(x_t + reset_gate * h_prev)
h_t = (1 - update_gate) * h_prev + update_gate * h_candidate
print("scalar_gru_lab")
for name, value in [
("update_gate", update_gate),
("reset_gate", reset_gate),
("h_candidate", h_candidate),
("h_t", h_t),
]:
print(f"{name:<12} {float(value):.4f}")
期待される出力:
scalar_gru_lab
update_gate 0.6900
reset_gate 0.4256
h_candidate 0.8849
h_t 0.8276
覚え方:
LSTM = より明示的な記憶管理
GRU = より軽量な gate 付き記憶管理
実験 3:PyTorch LSTM と GRU の Shape
import torch
from torch import nn
torch.manual_seed(42)
x = torch.randn(4, 6, 8)
lstm = nn.LSTM(input_size=8, hidden_size=16, batch_first=True)
gru = nn.GRU(input_size=8, hidden_size=16, batch_first=True)
lstm_out, (lstm_h, lstm_c) = lstm(x)
gru_out, gru_h = gru(x)
print("shape_lab")
print("lstm_out:", tuple(lstm_out.shape))
print("lstm_h :", tuple(lstm_h.shape))
print("lstm_c :", tuple(lstm_c.shape))
print("gru_out :", tuple(gru_out.shape))
print("gru_h :", tuple(gru_h.shape))
期待される出力:
shape_lab
lstm_out: (4, 6, 16)
lstm_h : (1, 4, 16)
lstm_c : (1, 4, 16)
gru_out : (4, 6, 16)
gru_h : (1, 4, 16)
目に見える API の違い:
- LSTM は
(h, c)を返す。 - GRU は
hだけを返す。
実験 4:記憶タスクを学習する
ラベルは系列の最初の値で決まります。途中の値はノイズなので、モデルは初期情報を保つ必要があります。
import torch
from torch import nn
torch.manual_seed(42)
def build_dataset(n=160, seq_len=10):
X, y = [], []
for _ in range(n):
first = 1.0 if torch.rand(1).item() > 0.5 else -1.0
seq = torch.randn(seq_len, 1) * 0.25
seq[0, 0] = first
X.append(seq)
y.append(1 if first > 0 else 0)
return torch.stack(X), torch.tensor(y)
X, y = build_dataset()
class GRUClassifier(nn.Module):
def __init__(self):
super().__init__()
self.gru = nn.GRU(input_size=1, hidden_size=8, batch_first=True)
self.fc = nn.Linear(8, 2)
def forward(self, x):
out, h = self.gru(x)
return self.fc(h[-1])
model = GRUClassifier()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
for epoch in range(1, 81):
logits = model(X)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch == 1 or epoch % 20 == 0:
acc = (logits.argmax(1) == y).float().mean().item()
print(f"memory epoch={epoch:02d} loss={loss.item():.4f} acc={acc:.3f}")
with torch.no_grad():
final_acc = (model(X).argmax(1) == y).float().mean().item()
print("final_acc", round(final_acc, 3))
期待される出力:
memory epoch=01 loss=0.7465 acc=0.431
memory epoch=20 loss=0.6691 acc=0.569
memory epoch=40 loss=0.0023 acc=1.000
memory epoch=60 loss=0.0001 acc=1.000
memory epoch=80 loss=0.0001 acc=1.000
final_acc 1.0
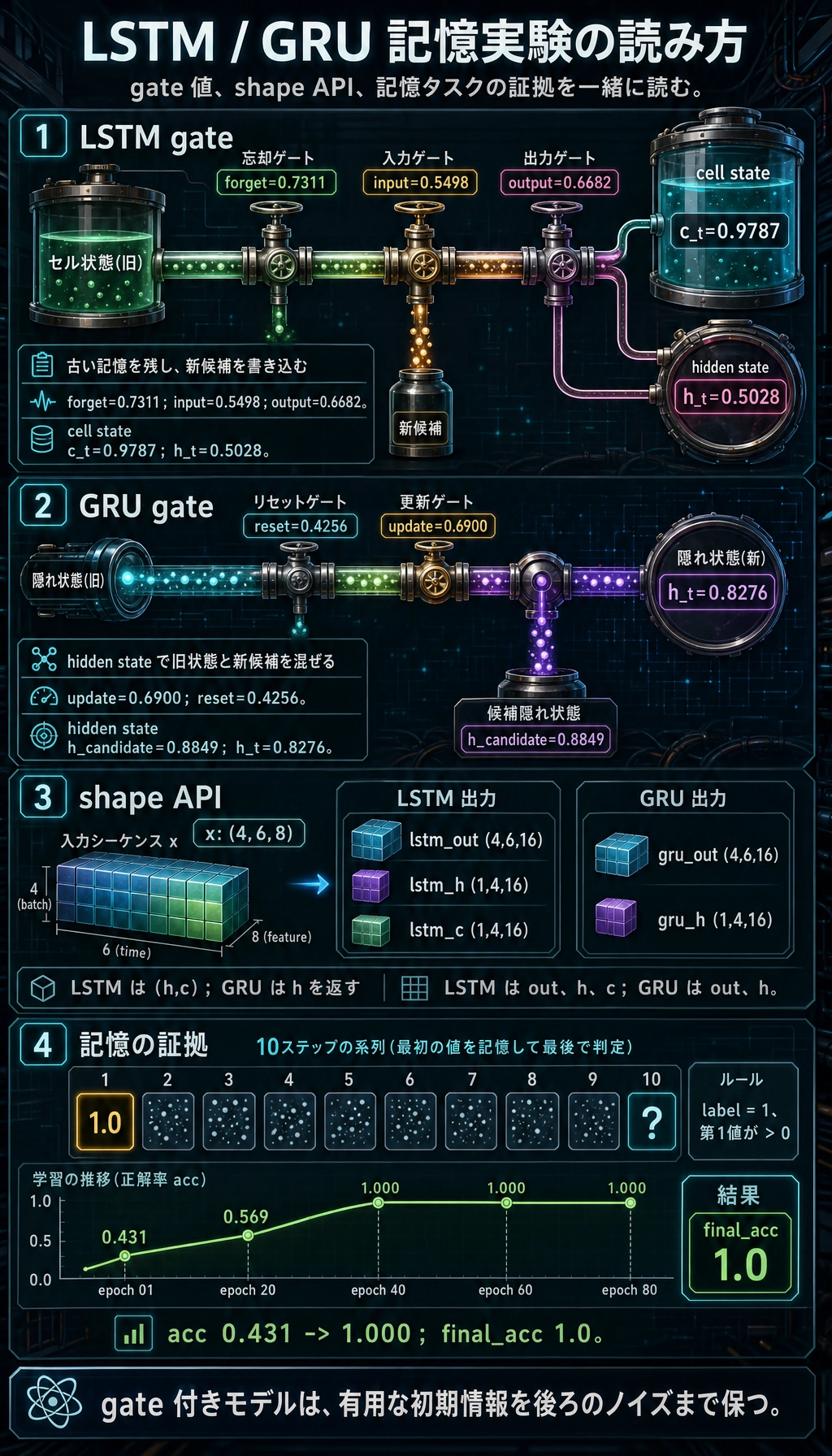
gate 値は state の混ざり方を示し、shape 確認は PyTorch API の返り値の約束を示します。記憶曲線は、最初の時間ステップの信号を後ろのノイズまで保てたことを示しています。
この task は小さいですが、gate 付き recurrent model が存在する理由をよく表しています。後ろにノイズが続いても、有用な初期情報を保つ必要があるからです。
LSTM か GRU か
| 状況 | 最初の候補 |
|---|---|
| 素早い baseline | GRU |
| モデル予算が小さい | GRU |
| 長期依存が中心 | LSTM と GRU の両方を試す価値がある |
| cell state の直感を明示的に扱いたい | LSTM |
| 現代的な長文タスク | Transformer が優先されることが多い |
実務では検証結果で比較します。アーキテクチャ名より、データとデプロイ制約に合うかどうかが重要です。
よくあるミス
| ミス | 修正 |
|---|---|
| LSTM/GRU を単に深い RNN だと思う | 深さではなく「記憶制御」と考える |
out、h、c を混同する | out は各ステップ、h は最終 hidden、c は LSTM cell state |
| gate が重要情報を絶対に忘れないと思う | gate は学習されるので失敗することもある |
| 不安定な系列に高い学習率を使う | LR を下げ、必要なら gradient clipping |
| training accuracy だけを見る | 保留した系列で検証する |
練習
- 実験 1 で
sigmoid(1.0)をsigmoid(-1.0)に変える。c_tはどう変わるか。 - 記憶タスクを、ラベルが最後の値に依存するように変える。より簡単になるか。
GRUClassifierをLSTMClassifierに置き換え、出力 API を比較する。seq_lenを10から30に増やす。学習は難しくなるか。- GRU は状態が少ないのに、多くのタスクでうまく動く理由を説明する。
まとめ
- LSTM と GRU は gate で記憶の流れを制御する。
- LSTM には
c_tとh_tがあり、GRU はより軽い hidden-state 設計を使う。 - Gate は
0から1の間で学習される soft switch。 - LSTM と GRU の選択は検証結果で判断する。
- Gate 付き recurrent model は、普通の RNN から attention ベースの系列モデルへ進む重要な橋渡しです。