6.4.2 RNN の基礎
この節の位置づけ
CNN は空間を走査します。RNN は時間を走査します。中心アイデアはシンプルです。現在のステップを読み、前のステップから来た圧縮メモリと組み合わせ、そのメモリを更新します。
学習目標
- 系列タスクで順序が重要な理由を説明できる。
- とても小さな hidden state 更新を手計算できる。
- PyTorch の
nn.RNNの入出力 shape を読める。 - 小さな many-to-one 系列分類器を作れる。
- 普通の RNN が長期依存を苦手とする理由を理解できる。
まず hidden state のループを見る
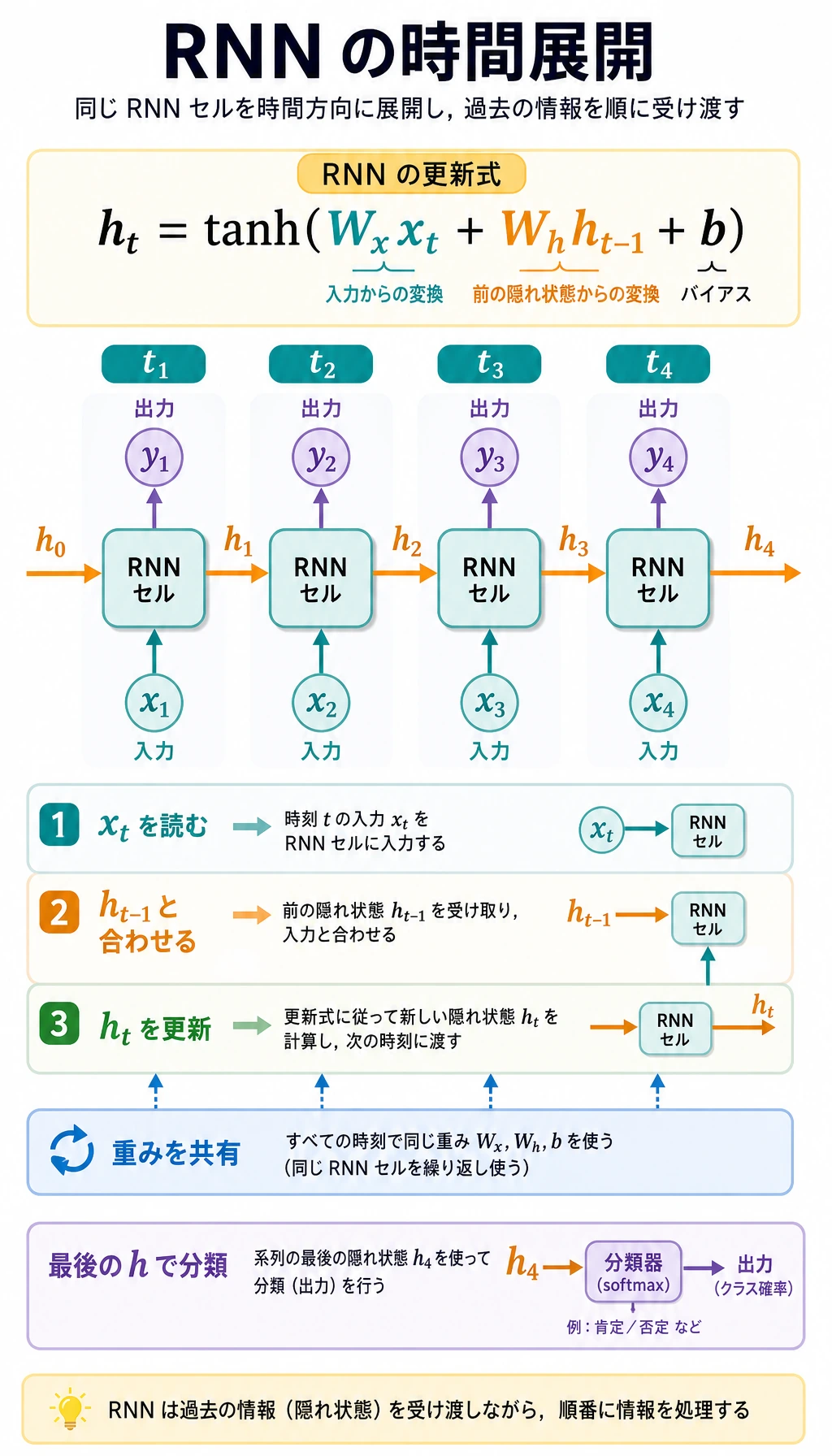
図は次のように読みます。
x_t + h_{t-1} -> RNN cell -> h_t
同じ RNN cell が各時間ステップで再利用されます。だから RNN は、長さ 5 の系列でも 50 の系列でも、位置ごとに新しいパラメータを作らずに処理できます。
なぜ系列タスクは違うのか
順序そのものが情報を持ちます。
| データ | なぜ順序が重要か |
|---|---|
| 文 | “not good” と “good, not hard” は意味が違う |
| 株価 / センサー系列 | 傾向は過去の値に依存する |
| ユーザークリック | 後の行動は前の意図に依存する |
| ログ | 同じイベントでも、前にエラーがあると意味が変わる |
MLP は固定ベクトルを処理できますが、1 ステップから次のステップへ自然に記憶を運ぶわけではありません。RNN が追加するのは、この状態です。
実験 1:hidden state を手で更新する
最小の RNN 更新は次のように書けます。
h_t = tanh(W_x * x_t + W_h * h_{t-1} + b)
まずスカラー版を動かします。
import numpy as np
x_seq = [1.0, 0.5, -1.0, 2.0]
W_x = 0.8
W_h = 0.5
b = 0.1
h = 0.0
print("manual_rnn_lab")
for t, x_t in enumerate(x_seq, start=1):
prev_h = h
h = np.tanh(W_x * x_t + W_h * h + b)
print(f"step={t} x={x_t:4.1f} prev_h={prev_h: .4f} h={h: .4f}")
期待される出力:
manual_rnn_lab
step=1 x= 1.0 prev_h= 0.0000 h= 0.7163
step=2 x= 0.5 prev_h= 0.7163 h= 0.6953
step=3 x=-1.0 prev_h= 0.6953 h=-0.3385
step=4 x= 2.0 prev_h=-0.3385 h= 0.9106
注目する依存関係はこれです。
新しい h は、現在の x と前の h に依存する
これが RNN の中心です。
実験 2:PyTorch RNN の shape を読む
batch_first=True を使うと、入力 shape が読みやすくなります。
[batch, seq_len, input_size]
実行します。
import torch
torch.manual_seed(42)
x = torch.randn(2, 5, 4)
rnn = torch.nn.RNN(input_size=4, hidden_size=6, batch_first=True)
out, h = rnn(x)
print("shape_lab")
print("x:", tuple(x.shape))
print("out:", tuple(out.shape))
print("h:", tuple(h.shape))
print("last_equal:", torch.allclose(out[:, -1, :], h[-1]))
期待される出力:
shape_lab
x: (2, 5, 4)
out: (2, 5, 6)
h: (1, 2, 6)
last_equal: True
丁寧に読むと:
| Tensor | Shape | 意味 |
|---|---|---|
x | [2, 5, 4] | 2 本の系列、各 5 ステップ、各ステップ 4 特徴 |
out | [2, 5, 6] | 各時間ステップの hidden output |
h | [1, 2, 6] | 1 層 RNN の最終 hidden state、batch 2、hidden size 6 |
1 層の RNN では、out[:, -1, :] は h[-1] と等しくなります。
出力パターン
| パターン | 用途 | 使う出力 |
|---|---|---|
| many-to-one | 感情、傾向クラス、スパム判定 | final hidden state |
| many-to-many | 各 token / 各ステップへのラベル付け | 各時間ステップの out |
| sequence-to-sequence | 翻訳、要約 | encoder/decoder 構造 |
このページでは、最初に学びやすい many-to-one に集中します。
実験 3:小さな系列分類器を学習する
タスク:短い数値系列が全体として正方向か負方向かを分類します。
import torch
from torch import nn
torch.manual_seed(42)
X = torch.tensor(
[
[[1.0], [1.2], [1.3], [1.1], [1.0]],
[[-1.0], [-1.1], [-1.3], [-0.9], [-1.2]],
[[0.8], [0.7], [1.0], [0.9], [1.1]],
[[-0.6], [-0.7], [-0.9], [-1.0], [-0.8]],
]
)
y = torch.tensor([1, 0, 1, 0])
class SimpleRNNClassifier(nn.Module):
def __init__(self):
super().__init__()
self.rnn = nn.RNN(input_size=1, hidden_size=8, batch_first=True)
self.fc = nn.Linear(8, 2)
def forward(self, x):
out, h = self.rnn(x)
return self.fc(out[:, -1, :])
model = SimpleRNNClassifier()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.05)
for epoch in range(1, 101):
logits = model(X)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch == 1 or epoch % 25 == 0:
acc = (logits.argmax(1) == y).float().mean().item()
print(f"trend epoch={epoch:03d} loss={loss.item():.4f} acc={acc:.3f}")
with torch.no_grad():
result = model(X).argmax(dim=1)
print("predictions:", result.tolist())
print("truth:", y.tolist())
期待される出力:
trend epoch=001 loss=0.7726 acc=0.000
trend epoch=025 loss=0.0002 acc=1.000
trend epoch=050 loss=0.0001 acc=1.000
trend epoch=075 loss=0.0000 acc=1.000
trend epoch=100 loss=0.0000 acc=1.000
predictions: [1, 0, 1, 0]
truth: [1, 0, 1, 0]
小さな例ですが、一通りそろった RNN ループです。系列 tensor、recurrent layer、最終 hidden 表現、分類器、loss、optimizer、予測まで含まれています。
普通の RNN が苦手なところ
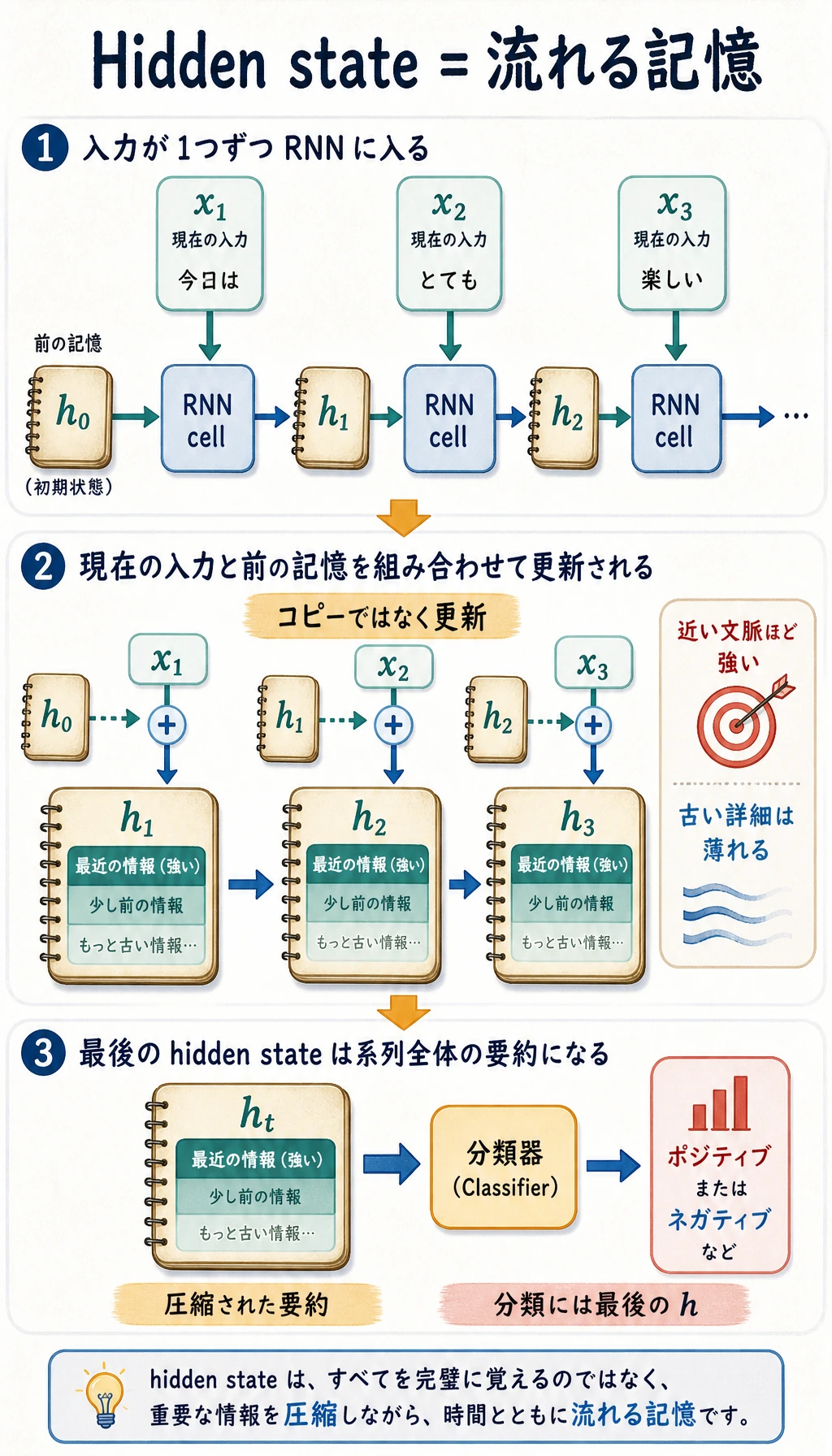
Hidden state は圧縮された記憶であり、正確な記憶ではありません。系列が長くなると、2 つの問題が出てきます。
| 問題 | 意味 |
|---|---|
| 情報の薄まり | 初期の情報を保つことが難しくなる |
| 勾配消失 | 学習信号が初期ステップへ戻るときに弱くなる |
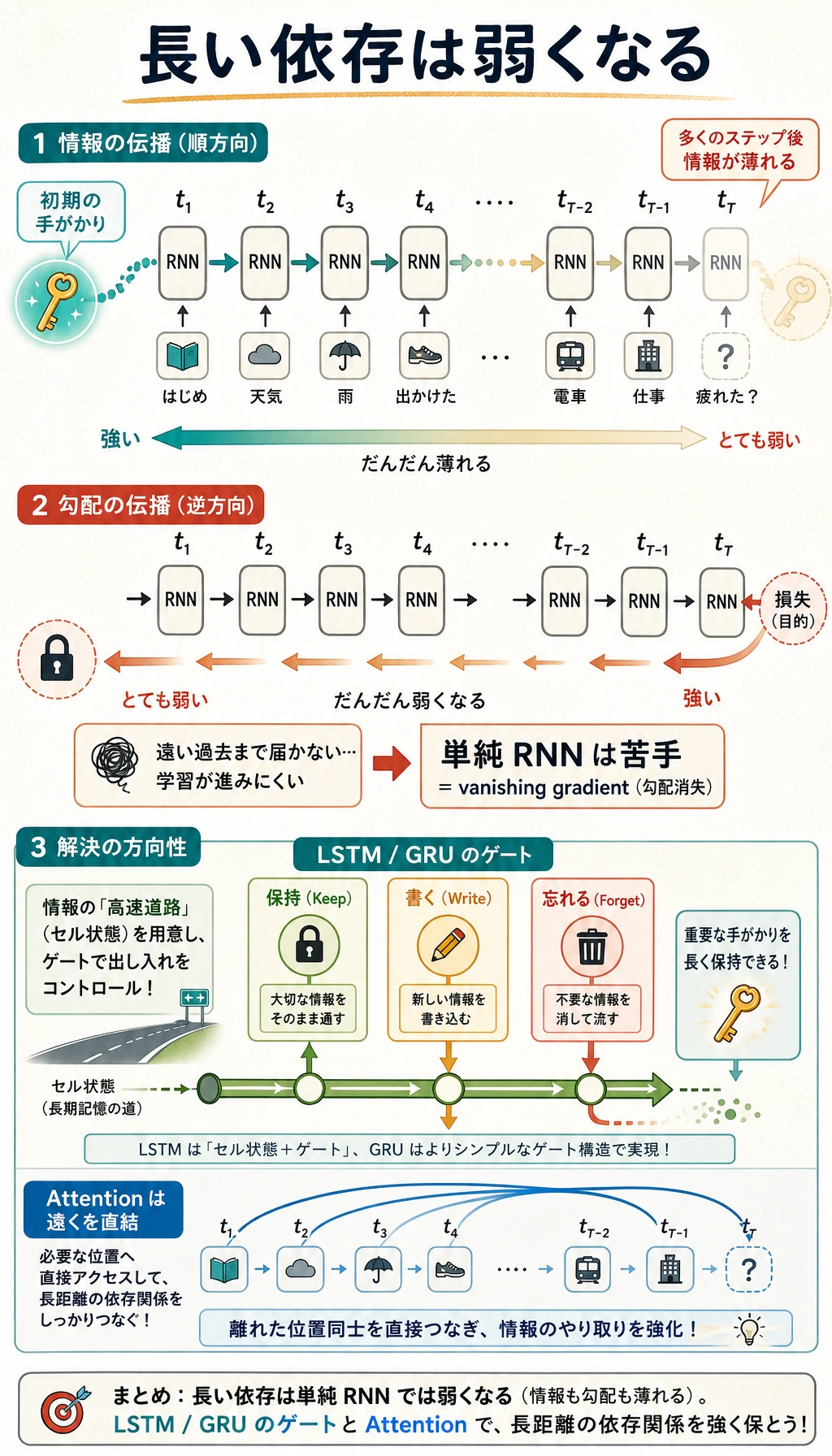
このため、LSTM と GRU には gate が追加されます。モデルが情報を保持するか、更新するか、捨てるかをよりうまく制御するためです。
よくあるミス
| ミス | 修正 |
|---|---|
| shape の順序を混同する | batch_first=True なら [batch, seq_len, input_size] |
out と h を混同する | out は各ステップ、h は各層の最終 hidden state |
CrossEntropyLoss の前に softmax する | 生の logits を loss に渡す |
| 普通の RNN が全部覚えると思う | 長期依存には LSTM/GRU や attention を使う |
| sequence length を意識しない | モデル設計前に tensor shape を表示する |
練習
- 実験 1 の
W_hを0.5から0.9に変える。hidden state はどう変わるか。 - 実験 2 の
hidden_sizeを6から12に変える。どの shape が変わるか。 - 実験 3 で、正負系列を増加 / 減少系列に置き換える。
- 分類器で
out[:, -1, :]の代わりにout.mean(dim=1)を使う。まだ学習できるか。 - とても長い文が普通の RNN にとって難しい理由を説明する。
まとめ
- RNN は、前のステップが後の解釈に影響する順序付きデータのためのモデル。
- hidden state は圧縮された rolling memory。
- 同じ RNN cell が時間方向に繰り返し使われる。
- PyTorch RNN は
batch_first=Trueにすると読みやすい。 - 普通の RNN は直感を学ぶのに役立つが、長期依存には LSTM/GRU のほうが向いている。