6.4.4 シーケンスモデリング実践
この節の位置づけ
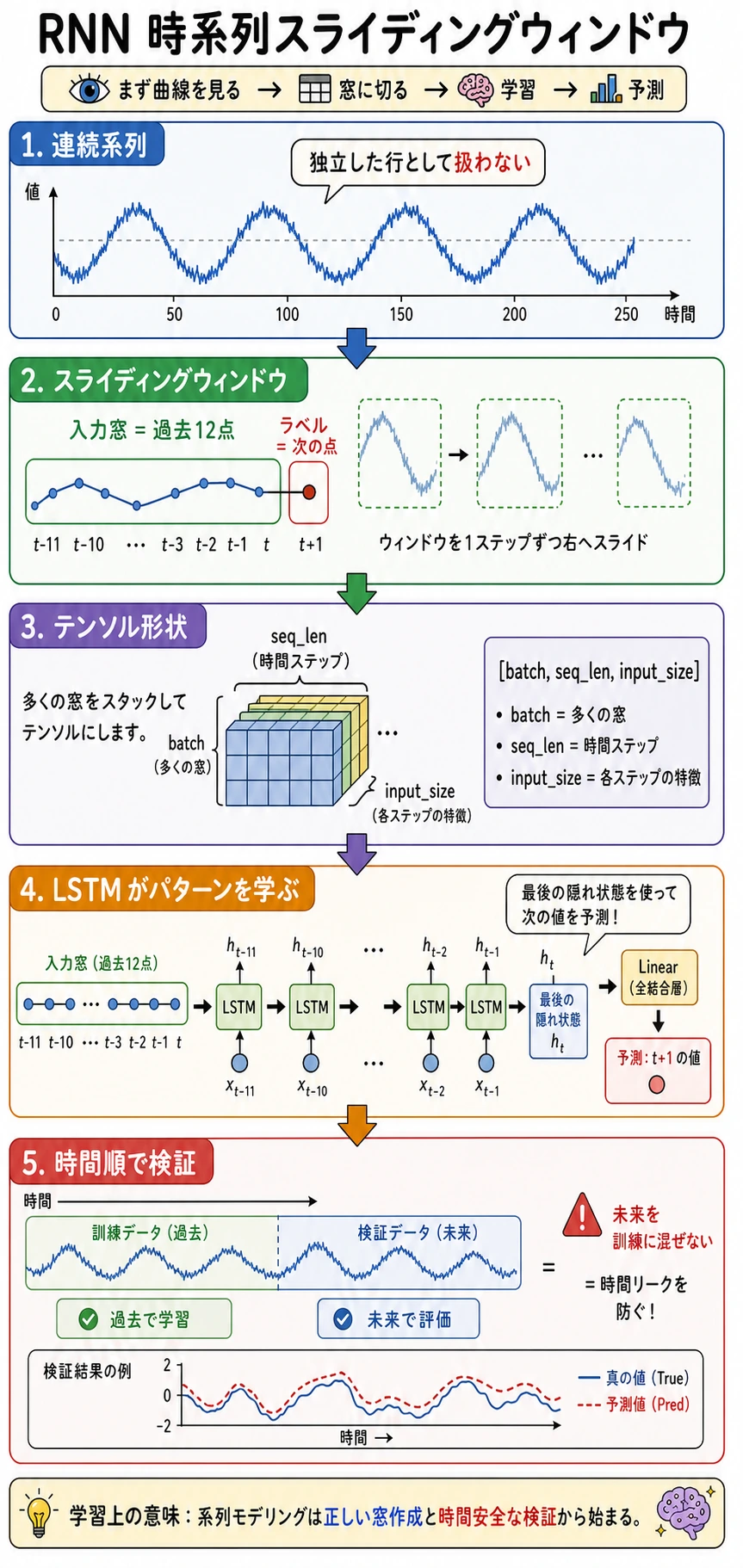
この節では、シーケンスモデリングを小さなプロジェクトとして動かします。連続系列をスライディングウィンドウのサンプルに変換し、LSTM を学習し、naive baseline と比較し、検証予測を確認します。
学習目標
- 連続した時系列を教師あり学習サンプルに変換する。
- LSTM 入力を
[batch, seq_len, input_size]に保つ。 - 未来情報の漏洩を避けるため、検証データを時間順に分ける。
- LSTM 予測器を学習し、naive baseline と比較する。
- 検証 loss と予測サンプルを読めるようになる。
中心となる流れ
連続系列 -> sliding window -> 時間順 split -> LSTM -> 検証 MSE -> 予測確認
時系列では、基本的にランダム分割を避けます。未来の点が訓練に漏れると、検証が楽観的になりすぎます。
1 分でわかるスライディングウィンドウ
window_size = 3 の場合:
series: [1, 2, 3, 4, 5, 6]
X[0] = [1, 2, 3] -> y[0] = 4
X[1] = [2, 3, 4] -> y[1] = 5
X[2] = [3, 4, 5] -> y[2] = 6
このように、連続系列を訓練用の行に変換します。
完全な実験:LSTM 予測
合成系列は 2 つの波とノイズでできています。まだ小さなデータですが、完全な正弦波より実データに近いです。
import numpy as np
import torch
from torch import nn
np.random.seed(42)
torch.manual_seed(42)
def make_windows(series, window_size):
X, y = [], []
for i in range(len(series) - window_size):
X.append(series[i : i + window_size])
y.append(series[i + window_size])
X = torch.tensor(np.array(X), dtype=torch.float32).unsqueeze(-1)
y = torch.tensor(np.array(y), dtype=torch.float32).unsqueeze(-1)
return X, y
t = np.arange(0, 220)
series = (
np.sin(t * 0.12)
+ 0.25 * np.sin(t * 0.03)
+ np.random.randn(len(t)) * 0.04
).astype(np.float32)
window_size = 16
X, y = make_windows(series, window_size)
split = int(len(X) * 0.8)
X_train, X_val = X[:split], X[split:]
y_train, y_val = y[:split], y[split:]
print("window_lab")
print("X:", tuple(X.shape), "y:", tuple(y.shape))
print("train:", tuple(X_train.shape), "val:", tuple(X_val.shape))
naive_val = ((X_val[:, -1, :] - y_val) ** 2).mean().item()
print("naive_val_mse:", round(naive_val, 4))
class LSTMForecaster(nn.Module):
def __init__(self, hidden_size=32):
super().__init__()
self.lstm = nn.LSTM(1, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMForecaster(32)
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(1, 121):
model.train()
pred = model(X_train)
loss = loss_fn(pred, y_train)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
if epoch == 1 or epoch % 30 == 0:
model.eval()
with torch.no_grad():
val_loss = loss_fn(model(X_val), y_val)
print(f"epoch={epoch:03d} train_mse={loss.item():.4f} val_mse={val_loss.item():.4f}")
model.eval()
with torch.no_grad():
val_pred = model(X_val)
print("first_5_pred:", [round(v, 3) for v in val_pred[:5, 0].tolist()])
print("first_5_true:", [round(v, 3) for v in y_val[:5, 0].tolist()])
期待される出力:
window_lab
X: (204, 16, 1) y: (204, 1)
train: (163, 16, 1) val: (41, 16, 1)
naive_val_mse: 0.0115
epoch=001 train_mse=0.5168 val_mse=0.4633
epoch=030 train_mse=0.0049 val_mse=0.0046
epoch=060 train_mse=0.0032 val_mse=0.0035
epoch=090 train_mse=0.0029 val_mse=0.0032
epoch=120 train_mse=0.0028 val_mse=0.0030
first_5_pred: [0.323, 0.261, 0.145, -0.025, -0.192]
first_5_true: [0.4, 0.213, 0.045, -0.076, -0.128]
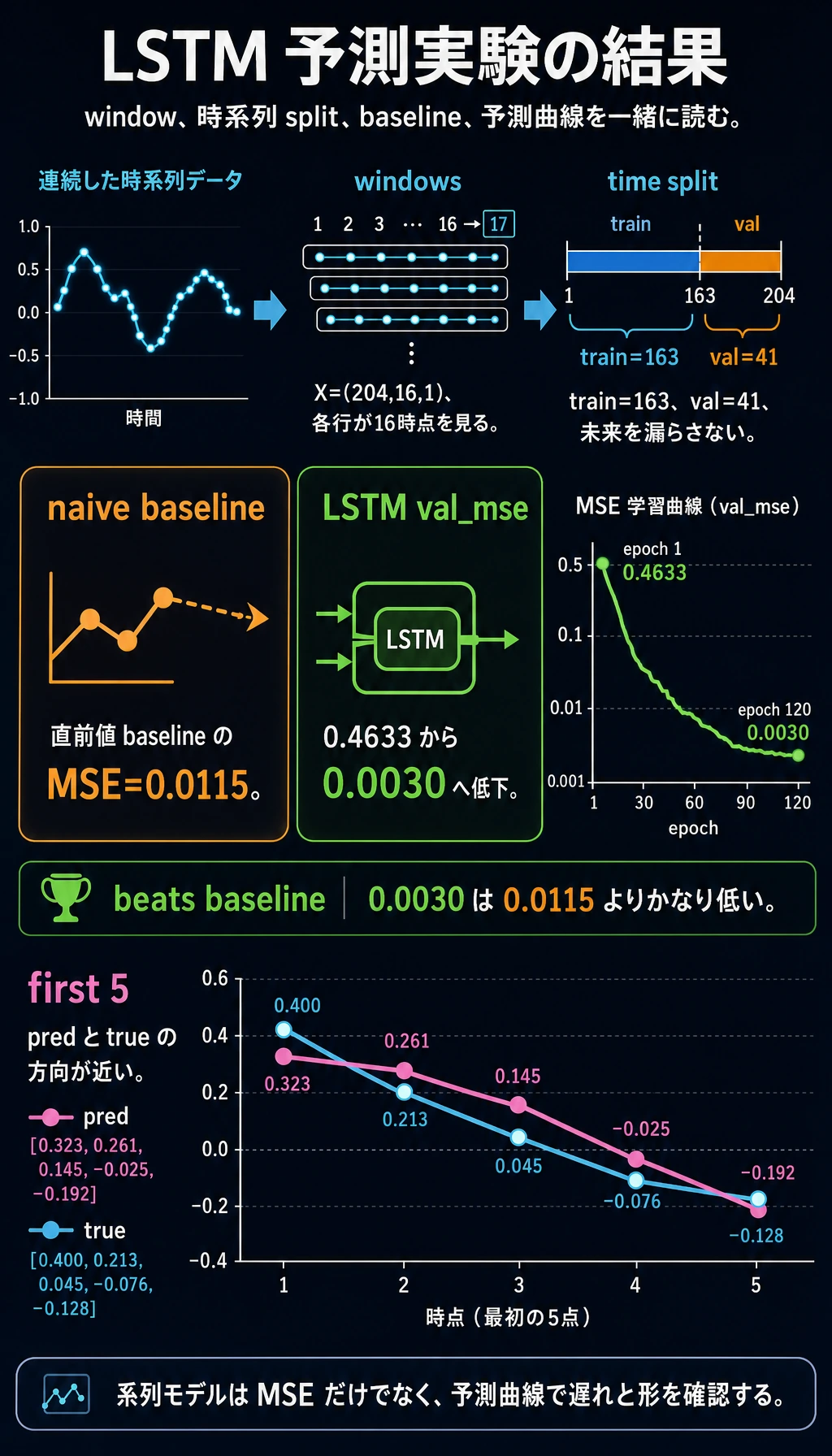
出力を読む
| 出力 | 意味 |
|---|---|
X: (204, 16, 1) | 204 個の window、16 time steps、各 step 1 feature |
train: (163, 16, 1) | 最初の 80% の window を訓練に使う |
val: (41, 16, 1) | 後ろの window を検証に使う |
naive_val_mse | baseline:最後に観測した値を次の値として予測 |
val_mse | LSTM の検証誤差 |
first_5_pred vs first_5_true | 方向とスケールの簡易確認 |
この実行では、LSTM は naive baseline を上回っています(0.0030 vs 0.0115)。これは重要です。信頼する前に、モデルはまず単純な baseline に勝つべきです。
なぜ Gradient Clipping を使うのか
RNN 系のモデルでは、勾配が大きくなることがあります。この行は全体の勾配 norm を制限します。
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
必ず必要とは限りませんが、系列モデルでは実用的な安全策です。
Notebook で何を描くべきか
Notebook では次を追加します。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
plt.plot(y_val.squeeze(-1).numpy(), label="true")
plt.plot(val_pred.squeeze(-1).numpy(), label="pred")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
見るべき点:
- lag:形は追えているが遅れている。
- flatline:平均値のような平らな予測になっている。
- missed peaks:window が短すぎる、またはモデルが弱い。
- noisy prediction:学習率、データノイズ、過学習の問題。
よくある落とし穴
| 落とし穴 | なぜ困るか | 修正 |
|---|---|---|
| train/val をランダム分割する | 未来が訓練に漏れる | 時間順に分割する |
| window が短すぎる | 文脈が足りない | 大きい window_size を試す |
| window が長すぎる | 最適化が難しく、ノイズも増える | 検証 loss で比較する |
| baseline がない | モデルがよく見えても実は trivial かもしれない | 最後値 baseline と比べる |
| MSE だけ見る | 傾向が遅れたり平坦化している可能性がある | 予測曲線を描く |
| 実データをスケーリングしない | 値の範囲が大きく訓練が不安定になる | 訓練統計だけで正規化する |
Toy Series から実プロジェクトへ
実際の系列プロジェクトでは、次が必要になることがあります。
- 各ステップに複数特徴。
- 欠損値処理。
- 訓練データだけに基づく正規化。
- rolling-origin validation。
- GRU、Temporal CNN、Transformer、統計 baseline。
- MSE だけでなく業務指標。
それでも流れは同じです。window を定義し、時間順を守り、baseline と比較し、予測を確認します。
練習
window_sizeを8と32に変える。どちらの検証 MSE が良いか。nn.LSTMをnn.GRUに変える。学習速度や曲線は変わるか。- gradient clipping を外す。学習は安定したままか。
np.cos(t * 0.12)などの 2 つ目の feature を追加する。- 予測値を次の window に戻して使う rolling forecast を実装する。
まとめ
- Sliding window は連続系列を教師あり学習サンプルに変える。
- 時間ベースの検証は未来情報の漏洩を防ぐ。
- 意味のある評価には naive baseline が必要。
- LSTM 入力は
[batch, seq_len, input_size]。 - 曲線と予測サンプルは、1 つの loss 値では見えない問題を見せてくれる。