LSTM 与 GRU
上一节你已经看到 RNN 会“边读边记”。
这一节要解决一个更现实的问题:
如果普通 RNN 记不住太久,怎么办?
LSTM 和 GRU 就是为了解决这个“会读,但容易忘”的问题。
学习目标
- 理解普通 RNN 为什么容易忘掉远处信息
- 直觉理解门控机制在做什么
- 掌握 LSTM 的 cell state 和三种门
- 掌握 GRU 的更新门与重置门
- 看懂 PyTorch 中
nn.LSTM和nn.GRU的输入输出 - 理解什么时候更适合用 LSTM,什么时候 GRU 已经够用
历史背景:为什么后来一定会走到 LSTM?
这一节最关键的历史节点是:
| 年份 | 节点 | 关键作者 | 它最重要地解决了什么 |
|---|---|---|---|
| 1994 | Learning Long-Term Dependencies is Difficult | Bengio, Simard, Frasconi | 系统揭示了普通 RNN 在长依赖训练里的梯度消失问题 |
| 1997 | LSTM | Hochreiter, Schmidhuber | 用门控记忆机制缓解长期依赖和梯度问题 |
对新人来说,最值得先记的是:
LSTM 不是“RNN 再复杂一点”,而是为了解决普通 RNN 很难稳稳记住长距离信息这个核心问题。
所以这节课真正的主线不是:
- 记住几个门的名字
而是:
- 理解这些门为什么会被发明出来
为什么当年很多人会把 LSTM 看成一次“正面救场”?
因为在那之前,RNN 这条路并不是没人喜欢。
恰恰相反,它看起来非常诱人:
- 文本是序列
- 语音是序列
- 时间序列还是序列
按直觉,RNN 好像天然就该成为这类任务的主力。
但真正训练起来后,大家又不断撞到同一堵墙:
- 早期信息留不住
- 梯度往回传时越来越弱
- 序列一长,模型就开始“会读但会忘”
所以 LSTM 当年让人兴奋的地方,不只是“门控很聪明”,
而是它第一次非常明确地在说:
不是 RNN 方向错了,而是它需要一种更认真管理记忆的结构。
为什么“梯度消失”会让很多人对 RNN 主线开始焦虑?
因为在纸面上,RNN 看起来几乎什么序列都能处理:
- 文本
- 语音
- 时间序列
但一到真正训练长序列时,大家会发现:
- 越早的信息越难留下来
- 梯度一路传回去时会越来越弱
这就像你一开始以为自己能一路把长故事复述清楚,
但讲到后面,最前面的细节已经开始变得模糊。
所以 LSTM 当年真正让人眼前一亮的地方,不是“多了几道门”,
而是它像在告诉大家:
既然普通 RNN 靠自然传递记不住,那就给记忆本身加管理机制。
这就是为什么后来很多��人会把 LSTM 看成:
- 不是小修小补
- 而是一次真正针对长依赖问题的正面回应
一、为什么普通 RNN 不够?
1.1 一个经典问题:长距离依赖
看这句话:
“我小时候在上海住过很多年,所以虽然现在搬走了,但我最熟悉的城市还是上海。”
如果模型在最后读到“上海”时,要知道前面说的是哪座城市,它就必须把很久之前的信息一路记下来。
普通 RNN 理论上可以做到,但实践里经常会遇到:
- 越往后,早期信息越容易被冲淡
- 训练时梯度容易消失
- 序列一长,记忆就不稳
1.2 一个直觉类比
普通 RNN 很像你在纸条上不断改写一小段摘要:
- 每来一句新话,就把旧摘要改一下
问题是:
- 摘要空间太小
- 旧信息容易被覆盖
所以后面就出现了一个更聪明的思路:
不要只靠一个“会变的摘�要”,而要让模型学会“哪些该忘、哪些该留、哪些该输出”。
这就是门控机制。
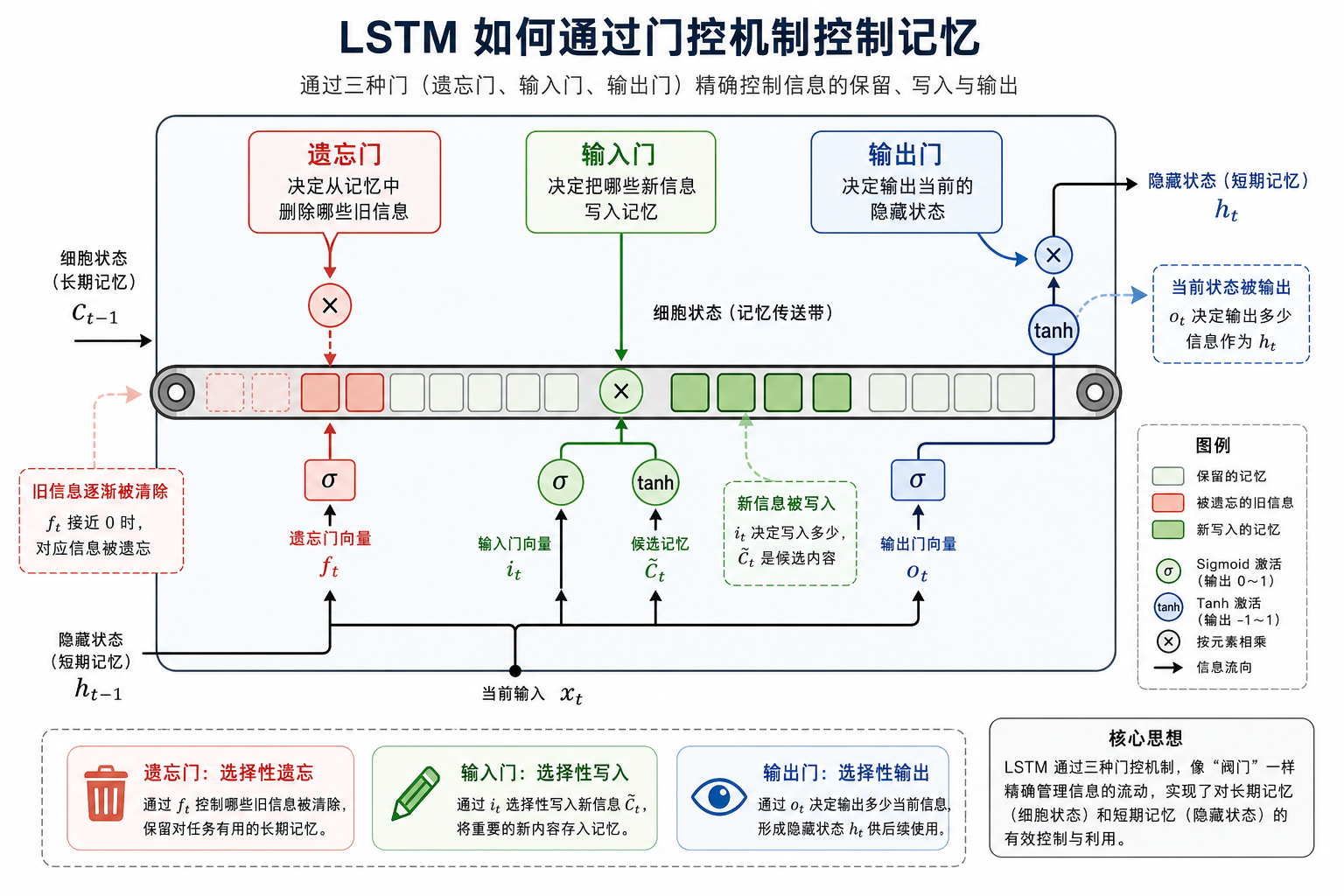
二、LSTM 的核心直觉:给记忆加上“门”
2.1 LSTM 到底多了什么?
LSTM 在普通 RNN 基础上,最关键的增强是:
- 多了一条更稳定的记忆通道:
cell state - 多了几道门,控制信息流
可以先把它理解成:
普通 RNN 像只有一个小本子,LSTM 则像一套更精细的记忆管理系统。
2.2 LSTM 的三道门
| 门 | 作用 |
|---|---|
| Forget Gate | 决定旧记忆保留多少 |
| Input Gate | 决定新信息写入多少 |
| Output Gate | 决定当前输出多少给外部 |
这三道门不是人工规则,而是模型自己学出来的。
三、先用一个“标量版”LSTM 建立直觉
3.1 为什么先看标量版?
因为真实 LSTM 一上来全是矩阵和向量,初学者容易看晕。
先看缩小版逻辑,会更容易抓住本质。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 假设这是上一时刻的记忆
c_prev = 0.8
# 当前输入和上一隐藏状态
x_t = 1.2
h_prev = 0.5
# 这里手工设几个门值,真实模型里这些门由网络学出来
forget_gate = sigmoid(1.0) # 大约 0.73
input_gate = sigmoid(0.2) # 大约 0.55
output_gate = sigmoid(0.7) # 大约 0.67
# 新候选信息
c_tilde = np.tanh(0.9)
# 更新 cell state
c_t = forget_gate * c_prev + input_gate * c_tilde
# 更新 hidden state
h_t = output_gate * np.tanh(c_t)
print("forget_gate =", round(float(forget_gate), 4))
print("input_gate =", round(float(input_gate), 4))
print("output_gate =", round(float(output_gate), 4))
print("c_t =", round(float(c_t), 4))
print("h_t =", round(float(h_t), 4))
3.2 这段代码到底在教什么?
它在教你:
forget_gate决定旧记忆丢多少input_gate决定新信息写多少output_gate决定当前往外暴露多少
也就是说,LSTM 真正强的地方不是“更复杂”,而是:
它学会了控制信息流。
四、LSTM 的两个状态:c_t 和 h_t
4.1 为什么要有两个状态?
LSTM 里通常有:
c_t:cell state,更偏长期记忆主通道h_t:hidden state,更偏当前时刻对外输出
4.2 一个容易记的比喻
你可以把它理解成:
c_t:你的长期草稿本h_t:你当前对外说出来的话
长期草稿本不一定全说出来,但它决定你后面还能记住什么。
五、GRU:更轻量的门控版本
5.1 GRU 为什么会出现?
LSTM 很强,但结构也更复杂。
后来人们提出 GRU(Gated Recurrent Unit),想做一个:
- 更简单
- 参数更少
- 效果又不差太多
的版本。
5.2 GRU 的两个核心门
| 门 | 作用 |
|---|---|
| Update Gate | 决定保留多少旧状态、混入多少新状态 |
| Reset Gate | 决定计算新状态时忘掉多少旧信息 |
5.3 一个最小 GRU 直觉示例
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
h_prev = 0.7
x_t = 1.1
update_gate = sigmoid(0.8)
reset_gate = sigmoid(-0.3)
h_candidate = np.tanh(x_t + reset_gate * h_prev)
h_t = (1 - update_gate) * h_prev + update_gate * h_candidate
print("update_gate =", round(float(update_gate), 4))
print("reset_gate =", round(float(reset_gate), 4))
print("h_candidate =", round(float(h_candidate), 4))
print("h_t =", round(float(h_t), 4))
5.4 和 LSTM 的直觉差别
- LSTM:更像精细记忆管理系统
- GRU:更像压缩版记忆管理系统
所以很多时候可以简单记成:
GRU = 更轻一些的 LSTM。
六、LSTM 和 GRU 怎么选?
6.1 一般经验
如果你只是要一个序列模型 baseline:
- 先试 GRU 往往更省事
如果任务对长距离依赖特别敏感:
- LSTM 常常更值得一试
6.2 但不要把它们神化
在今天的大模型时代,很多长文本任务已经更多交给 Transformer。
但在这些场景里,LSTM / GRU 仍然很常见:
- 较短序列建模
- 小数据场景
- 时序任务 baseline
- 教学与理解序列建模本质
七、PyTorch 中怎么用 LSTM 和 GRU?
7.1 最小可运行示例
import torch
torch.manual_seed(42)
# batch=4, seq_len=6, input_size=8
x = torch.randn(4, 6, 8)
lstm = torch.nn.LSTM(input_size=8, hidden_size=16, batch_first=True)
gru = torch.nn.GRU(input_size=8, hidden_size=16, batch_first=True)
lstm_out, (lstm_h, lstm_c) = lstm(x)
gru_out, gru_h = gru(x)
print("lstm_out shape:", lstm_out.shape)
print("lstm_h shape :", lstm_h.shape)
print("lstm_c shape :", lstm_c.shape)
print("gru_out shape :", gru_out.shape)
print("gru_h shape :", gru_h.shape)
7.2 输出分别是什么?
对于 LSTM:
lstm_out:每个时间步的输出lstm_h:最后隐藏状态lstm_c:最后 cell state
对于 GRU:
gru_out:每个时间步的输出gru_h:最后隐藏状态
这里你也能一眼看到一个区别:
LSTM 比 GRU 多维护了一份
c状态。
八、一个小任务:让模型记住序列开头的信息
下面我们构造一个很小的任务:
- 输入序列第一个位置可能是
+1或-1 - 标签就看这个第一个值
- 中间加很多噪声
也就是说,模型必须记住“很早之前”的信息。
import torch
from torch import nn
torch.manual_seed(42)
def build_dataset(n=100):
X, y = [], []
for _ in range(n):
first = 1.0 if torch.rand(1).item() > 0.5 else -1.0
seq = torch.randn(8, 1) * 0.2
seq[0, 0] = first
X.append(seq)
y.append(1 if first > 0 else 0)
return torch.stack(X), torch.tensor(y)
X, y = build_dataset(120)
class GRUClassifier(nn.Module):
def __init__(self):
super().__init__()
self.gru = nn.GRU(input_size=1, hidden_size=8, batch_first=True)
self.fc = nn.Linear(8, 2)
def forward(self, x):
out, h = self.gru(x)
return self.fc(h[-1])
model = GRUClassifier()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
for epoch in range(80):
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 20 == 0:
acc = (pred.argmax(dim=1) == y).float().mean().item()
print(f"epoch={epoch:3d}, loss={loss.item():.4f}, acc={acc:.3f}")
with torch.no_grad():
final_acc = (model(X).argmax(dim=1) == y).float().mean().item()
print("final acc =", round(final_acc, 3))
这个任务很小,但它确实在教你:
门控循环网络比普通 RNN 更擅长保住早期重要信息。
九、初学者最常踩的坑
9.1 把 LSTM / GRU 当成“比 RNN 更深”
不是“更深”,而是“记忆管理更聪明”。
9.2 分不清 out、h、c
记住:
out:每一步输出h:最后隐藏状态c:LSTM 的长期记忆状态
9.3 以为用了 LSTM 就天然不会忘
不是。
它只是比普通 RNN 更擅长控制忘和记,不代表无限长依赖都能轻松搞定。
小结
这一节最关键的不是背门公式,而是理解这件事:
LSTM 和 GRU 的本质,是用门控机制学会“该忘什么、该留什么、当前该输出什么”。
它们是对普通 RNN 的一次重要升级,也是你理解后续注意力机制和 Transformer 的很好台阶。
练习
- 把 LSTM 标量示例里的门值改掉,看看
c_t和h_t如何变化。 - 把 GRU 分类小任务改成“标签由最后一个值决定”,看模型是否更容易学。
- 分别把同一个任务换成 LSTM 和 GRU,比较训练速度和代码复杂度。
- 用自己的话解释:为什么说 LSTM / GRU 的关键不是“更复杂”,而是“信息流控制更精细”?