卷积操作原理
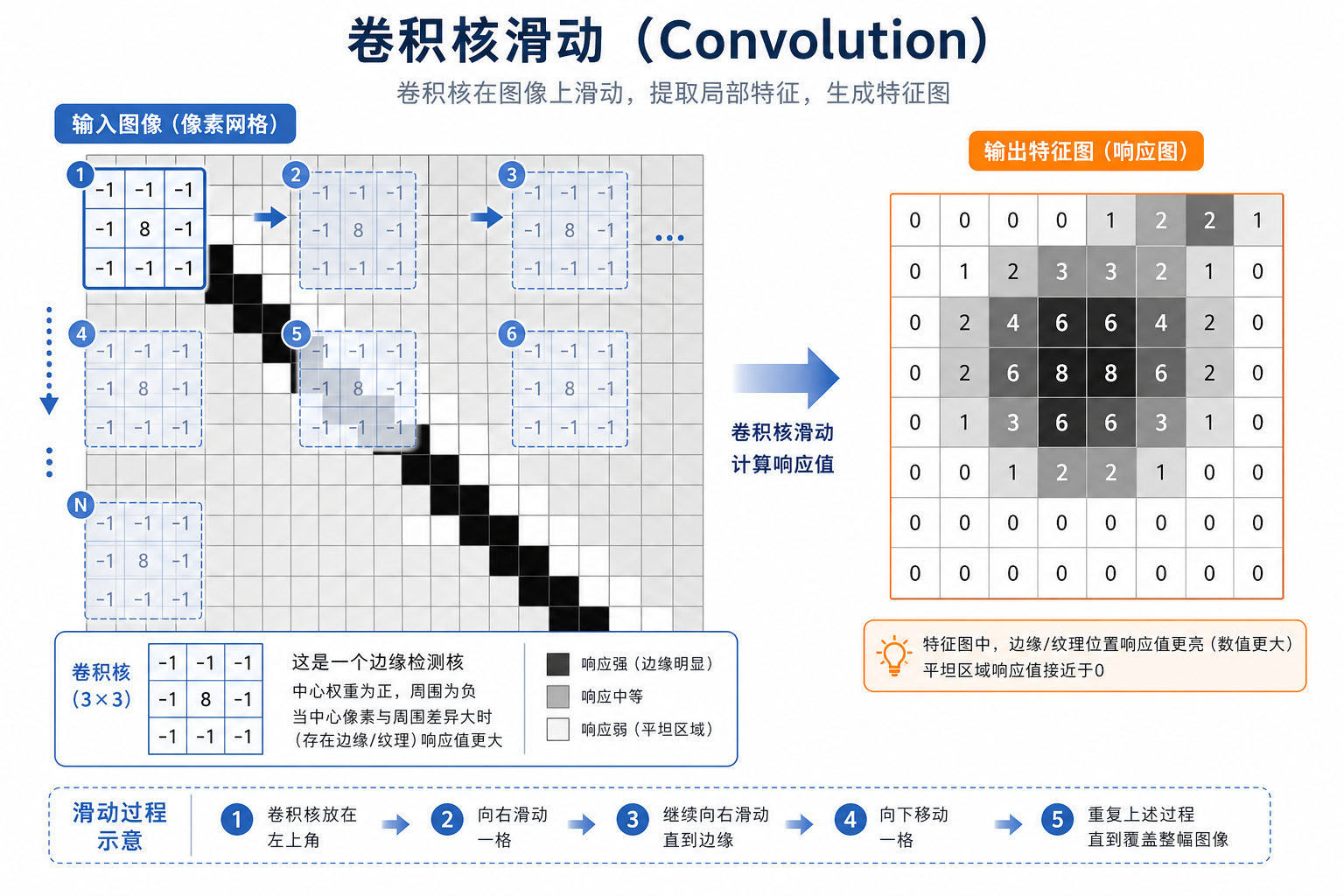
如果说前面的神经元、MLP 让你学会了“神经网络会算什么”,那卷积这节就是在回答另一个更关键的问题:
神经网络怎样高效地看图?
这一节是整条 CV 主线的起点。后面你学分类、检测、分割,都会反复用到这里的直觉。
学习目标
- 理解为什么图像任务不能直接粗暴地用全连接层解决
- 直觉理解卷积核、局部连接、参数共享
- 手算一个最小卷积示例,真正看懂每�个输出值怎么来的
- 掌握
stride、padding和输出尺寸计算 - 理解多通道卷积和感受野
- 能看懂 PyTorch 中最基础的
Conv2d
这节和前面 MLP 主线是怎么接上的
如果你刚学完 MLP,可以先把这节理解成:
- MLP 已经告诉你“网络会算什么”
- 卷积这一节开始回答“网络怎样更合适地看图”
也就是说,这一节不是在推翻“线性层 + 激活函数”,而是在改进输入组织方式:
- 不再把图片粗暴拉平成长向量
- 而是让网络按局部窗口、带着空间结构去看
这正是视觉任务里最重要的结构变化。
一、为什么图像任务需要卷积?
1.1 先看一个“直接展平”的问题
假设你有一张 32 x 32 的灰度图。
如果把它直接展平成一个向量,再送进全连接层:
- 输入维度是
32 * 32 = 1024 - 如果下一层有 512 个神经元,就需要
1024 * 512 = 524288个权重
如果图片再大一点,比如 224 x 224 x 3:
- 输入维度变成
150528 - 参数量会瞬间爆炸
更糟糕的是,展平以后,图像原本最重要的东西被破坏了:
- 邻近像素之间的关系
- 边缘、纹理、局部图案
- 空间结构
也就是说:
图片不是普通表格数据。
它最值钱的不是“有多少数字”,而是“这些数字怎样在空间上挨在一起”。
1.3 这一节最该先盯住的,不是卷积核长什么样
而是先盯住这两个“为什么”:
- 为什么不能直接展平
- 为什么局部邻近关系必须保住
只要这两个点稳了,后面卷积核、步长、填充这些概念才不会变成纯记忆题。
1.2 卷积到底解决了什么?
卷积做了两件特别重要的事:
- 只看局部区域,而不是一次看整张图
- 同一组参数在整张图上滑动复用
这两个设计分别对应:
- 局部连接
- 参数共享
你可以把卷积理解成:
拿一个小模板,在图片上滑来滑去,专门找某种局部模式。
比如:
- 竖线
- 横线
- 边缘
- 角点
- 纹理
二、卷积核是什么?
2.1 一个最容易理解的类比
卷积核(kernel / filter)就像一张很小的“透明模板”。
你把它盖在图片的一小块区域上:
- 对应位置相乘
- 再把结果加起来
得到一个分数。
这个分数可以理解成:
这块区域有多像卷积核正在寻找的模式。
2.2 最小可运行示例:手工做一次卷积
import numpy as np
# 4x4 图像
image = np.array([
[1, 2, 0, 0],
[5, 3, 0, 4],
[2, 1, 3, 1],
[0, 2, 1, 2]
], dtype=np.float32)
# 2x2 卷积核
kernel = np.array([
[1, 0],
[0, -1]
], dtype=np.float32)
out = np.zeros((3, 3), dtype=np.float32)
for i in range(3):
for j in range(3):
patch = image[i:i + 2, j:j + 2]
out[i, j] = np.sum(patch * kernel)
print("image =\n", image)
print("kernel =\n", kernel)
print("output =\n", out)
2.3 第一个输出值是怎么来的?
左上角的 2x2 patch 是:
[[1, 2],
[5, 3]]
卷积核是:
[[ 1, 0],
[ 0,-1]]
逐元素相乘:
[[ 1*1, 2*0],
[ 5*0, 3*(-1)]]
求和:
1 + 0 + 0 - 3 = -2
所以输出左上角就是 -2。
这就是卷积最核心的计算。
2.4 卷积核最值得先记的,不是“它会滑”,而是“它在找模式”
一个更适合新人的说法是:
- 一个卷积核就是一个小模式探测器
不同卷积核可能更容易对这些模式有反应:
- 边缘
- 方向变化
- 小纹理
- 局部角点
所以卷积层真正做的不是“把图像乘来乘去”,而是:
一层层把低级局部模式提出来,交给后面的层继续组合。
三、卷积为什么能检测边缘?
3.1 因为它本质上在比较局部差异
如果一个卷积核专门设计成“左边减右边”或“上边减下边”,它就会对边界特别敏感。
例如下面这个核:
[[ 1, 0],
[ 0, -1]]
它会对“左上亮、右下暗”这类局部结构有反应。
如果图像某块区域很平滑、像素差不多,卷积结果往往接近 0。
如果局部变化很剧烈,卷积结果就会比较大。
3.2 再看一个边缘核
import numpy as np
image = np.array([
[0, 0, 0, 0, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 0, 0]
], dtype=np.float32)
kernel = np.array([
[-1, 1]
], dtype=np.float32)
out = np.zeros((5, 4), dtype=np.float32)
for i in range(5):
for j in range(4):
patch = image[i:i + 1, j:j + 2]
out[i, j] = np.sum(patch * kernel)
print("output =\n", out)
你会看到在“0 变 1”的边界附近,输出最明显。
四、Stride 和 Padding 到底是什么?
4.1 Stride:每次滑几步
stride 可以理解成卷积核在图片上移动的步长。
stride = 1:每次挪 1 格stride = 2:每次挪 2 格
步长越大:
- 输出更小
- 计算更快
- 细节丢失更多
4.2 Padding:先在图像边缘补一圈
如果不做 padding,卷积核滑到边缘时就会停下来,输出尺寸会变小。
padding 的作用是:
- 保留边缘信息
- 控制输出尺寸
最常见的是补 0,也叫 zero padding。
4.3 第一次学 stride 和 padding,最容易乱在哪?
最容易乱的点通常不是公式本身,而是:
- 不知道它们是在控制“看得多细”和“输出有多大”
一个更稳的记法是:
stride更像“每次滑多远”padding更像“边缘要不要先补一圈”
所以它们本质上都在影响两件事:
- 信息保留多少
- 计算量和输出尺寸怎么变
4.4 输出尺寸公式
对于二维卷积:
output = floor((input + 2*padding - kernel_size) / stride) + 1
例如:
- 输入宽高:
6 - 卷积核:
3 - padding:
1 - stride:
2
则输出尺寸:
floor((6 + 2*1 - 3) / 2) + 1 = floor(5/2) + 1 = 2 + 1 = 3
4.5 可运行示例:验证输出尺寸
import torch
from torch import nn
x = torch.randn(1, 1, 6, 6) # batch=1, channel=1, H=6, W=6
conv = nn.Conv2d(
in_channels=1,
out_channels=2,
kernel_size=3,
stride=2,
padding=1
)
y = conv(x)
print("input shape :", x.shape)
print("output shape:", y.shape)
输出里你会看到高宽都变成 3。
五、多通道卷积:彩色图片怎么处理?
5.1 灰度图和 RGB 图的区别
灰度图 shape 往往是:
H x W
RGB 图在深度学习里常写成:
C x H x W
其中:
C = 3- 分别对应 R/G/B 三个通道
5.2 卷积核也会“长出通道”
如果输入是 RGB 图,那么一个卷积核不再只是 3 x 3,而是:
3 x 3 x 3
也就是:
- 对红通道看一个
3x3 - 对绿通道看一个
3x3 - 对蓝通道看一个
3x3
最后把三个通道的结果加起来,再加偏置,得到一个输出值。
5.3 多个卷积核 = 多个输出通道
如果你有 16 个卷积核,就会得到 16 张特征图。
这就是为什么 Conv2d 里会写:
in_channelsout_channels
import torch
from torch import nn
x = torch.randn(2, 3, 32, 32) # batch=2, RGB 图像
conv = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, padding=1)
y = conv(x)
print("input shape :", x.shape)
print("output shape:", y.shape)
这里输出 shape 会是:
[2, 8, 32, 32]
也就是:
- 2 张图片
- 每张图片提取出 8 个通道的特征图
六、感受野:为什么深层网络能看到更大范围?
6.1 感受野的直觉
感受野(receptive field)指的是:
输出中的一个位置,能“看到”原图多大范围。
一个 3x3 卷积层,看见的只是局部 3x3。
但如果连续堆叠多层:
- 第一层看
3x3 - 第二层基于第一层结果再看
3x3
那么第二层实际就间接看到了更大的原图范围。
6.2 为什么这很重要?
因为图像理解通常有层级:
- 浅层:边缘、纹理
- 中层:角点、局部形状
- 深层:物体部件、整体语义
卷积网络之所以强,不是因为“卷积这个动作神奇”,而是因为:
小局部特征可以一层层组合成更抽象的大模式。
七、PyTorch 里的卷积层到底在做什么?
7.1 最基础的 Conv2d
import torch
from torch import nn
x = torch.randn(1, 1, 8, 8)
conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=3,
stride=1,
padding=1
)
y = conv(x)
print("输入 shape :", x.shape)
print("输出 shape :", y.shape)
print("权重 shape :", conv.weight.shape)
print("偏置 shape :", conv.bias.shape)
这里:
out_channels=4表示有 4 个卷积核conv.weight.shape = [4, 1, 3, 3]- 4 个输出通道
- 每个核看 1 个输入通道
- 核大小
3x3
7.2 卷积层后面为什么常接激活函数?
和 MLP 一样:
- 卷积先做线性变换
- 激活函数再引入非线性
典型写法:
nn.Conv2d(...)
nn.ReLU()
八、初学者最常见的坑
8.1 把卷积当成“魔法特征提取器”
卷积不是魔法,本质上就是:
- 小窗口
- 逐元素乘法
- 求和
- 滑动
8.2 搞混 shape
最常见错误之一就是搞混:
H x W x CC x H x W
在 PyTorch 里,通常是:
N x C x H x W
8.3 不知道输出尺寸怎么算
很多报错不是模型不会,而是尺寸不匹配。
所以 kernel_size / stride / padding 的尺寸计算一定要会。
小结
这一节最重要的不是记住“卷积”两个字,而是建立三个稳定直觉:
- 图像任务需要保留空间结构,所以不能简单展平后暴力全连接
- 卷积核是在整张图上重复寻找局部模式
- 多层卷积让模型从局部特征逐步组合出更高级的视觉理解
理解了这三点,你后面学 CNN 结构、经典架构、目标检测时,就不会把卷积层当黑盒。
练习
- 把本节的
2x2卷积核改成别的数值,观察输出怎样变化。 - 自己手算一个输出位置,再和代码结果对比。
- 用 PyTorch 改写一个
kernel_size=5、stride=2的卷积层,验证输出尺寸。 - 想一想:如果图片中的物体整体平移一点点,卷积为什么通常比全连接更稳?