5.2.2 線形回帰:baseline、残差、正則化
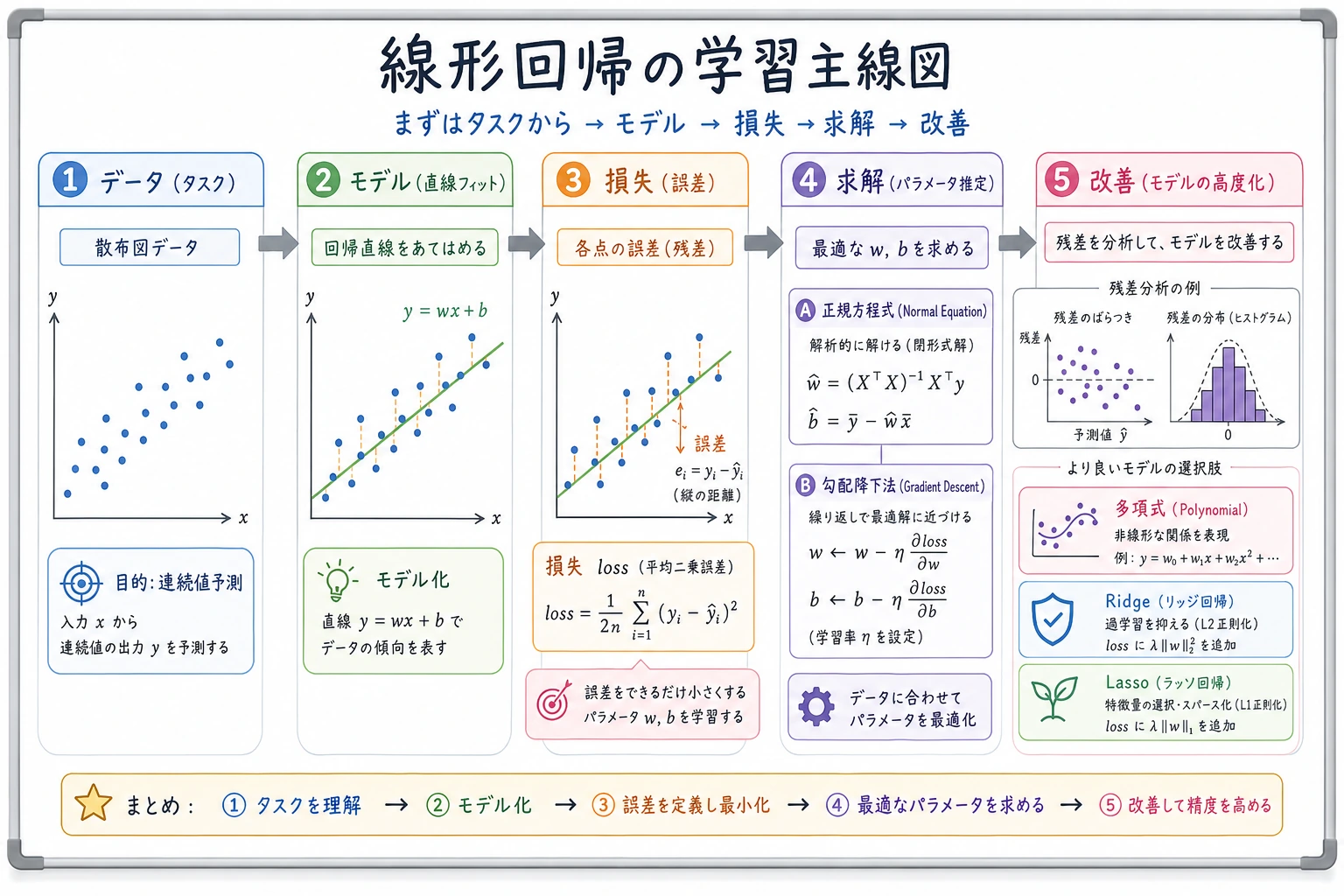
線形回帰が答える実用的な問いは、いくつかの入力数値で、1つの連続値を説明または予測できるかです。例は価格、売上、需要、気温、遅延、コストなどです。
まず直感を見る
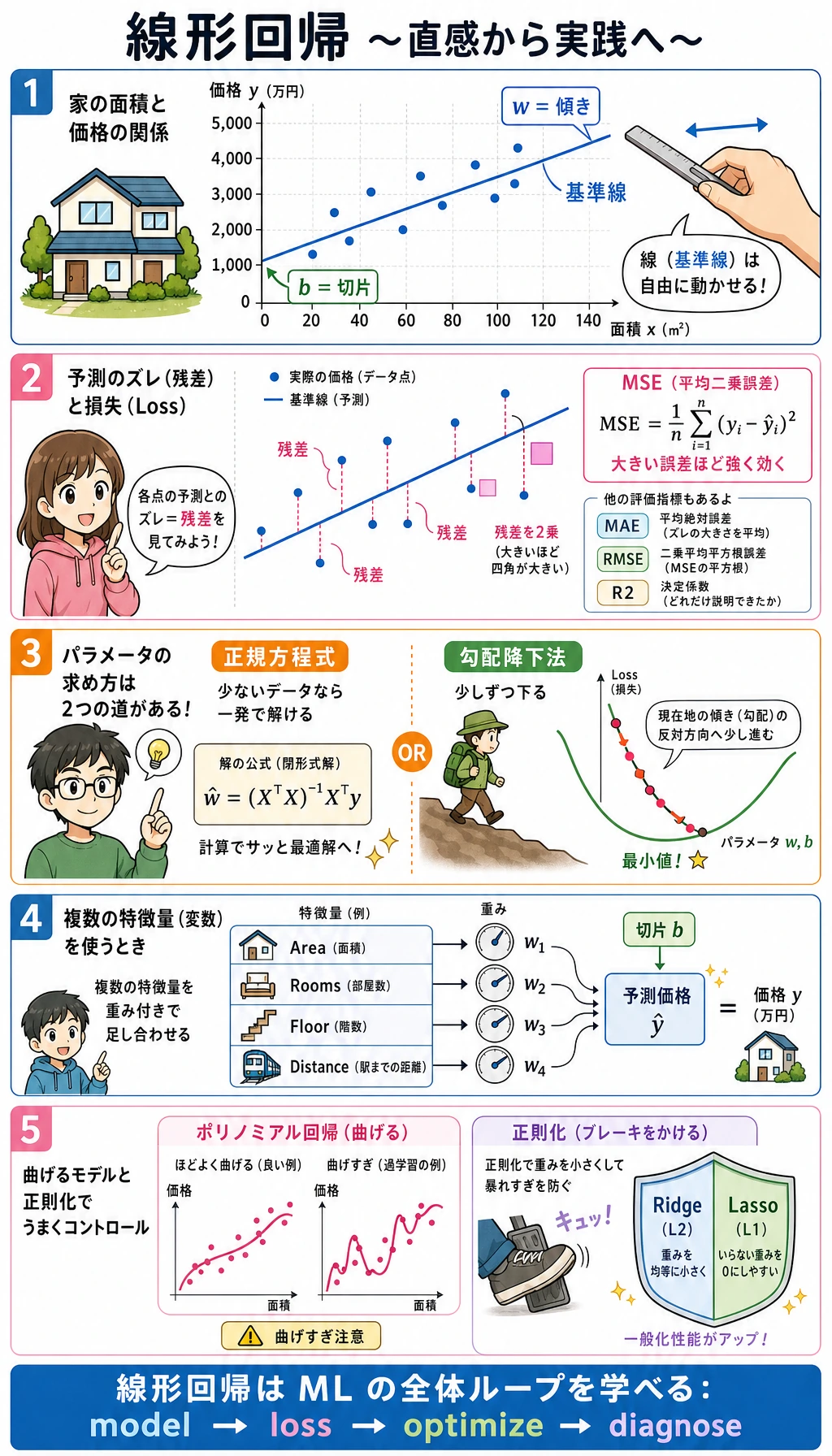
この流れを覚えてください。
特徴量 -> 重み付き和 -> 予測 -> 残差 -> 指標 -> 改善
| 用語 | 最初の意味 |
|---|---|
| feature | 面積、部屋数、築年数などの入力列 |
| coefficient | ある特徴量が増えたとき、予測がどう変わるか |
| intercept | 特徴量の効果を足す前の基礎予測 |
| residual | 実測値 - 予測値 |
| RMSE | 大きな外れを強く罰する典型誤差 |
| MAE | 平均絶対誤差。説明しやすい |
| R² | 目標値の変動をモデルがどれくらい説明したかの目安 |
完全な回帰実験を動かす
ch05_linear_regression_lab.py を作成します。
import numpy as np
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
rng = np.random.default_rng(42)
area = rng.uniform(45, 180, 80)
rooms = rng.integers(1, 5, 80)
age = rng.uniform(0, 30, 80)
noise = rng.normal(0, 12, 80)
price = 35 + 2.8 * area + 18 * rooms - 1.6 * age + noise
X = np.column_stack([area, rooms, age])
X_train, X_test, y_train, y_test = train_test_split(
X, price, test_size=0.25, random_state=42
)
baseline = np.full_like(y_test, y_train.mean())
model = LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
print("baseline_rmse=", round(mean_squared_error(y_test, baseline) ** 0.5, 2))
print("linear_rmse=", round(mean_squared_error(y_test, pred) ** 0.5, 2))
print("linear_mae=", round(mean_absolute_error(y_test, pred), 2))
print("linear_r2=", round(r2_score(y_test, pred), 3))
print("intercept=", round(model.intercept_, 2))
print("coefficients=", np.round(model.coef_, 2).tolist())
print("first_prediction=", round(pred[0], 2))
print("first_residual=", round(y_test[0] - pred[0], 2))
poly = Pipeline([
("poly", PolynomialFeatures(degree=2, include_bias=False)),
("scale", StandardScaler()),
("ridge", Ridge(alpha=10.0)),
])
poly.fit(X_train, y_train)
poly_pred = poly.predict(X_test)
print("ridge_poly_rmse=", round(mean_squared_error(y_test, poly_pred) ** 0.5, 2))
実行します。
python ch05_linear_regression_lab.py
期待される出力:
baseline_rmse= 123.23
linear_rmse= 11.68
linear_mae= 8.59
linear_r2= 0.991
intercept= 30.54
coefficients= [2.85, 17.97, -1.72]
first_prediction= 457.07
first_residual= 30.0
ridge_poly_rmse= 13.8

結果を読む
baseline はすべての家に対して学習データの平均値を予測します。RMSE が大きいので、特徴量には情報があると分かります。
線形モデルは、隠れたデータ生成ルールに近い式を学びました。
price ~= 30.54 + 2.85 * area + 17.97 * rooms - 1.72 * age
この合成データでは次のように読めます。
| 特徴量 | 学んだ方向 | 解釈 |
|---|---|---|
| area | 正 | 面積が大きいほど価格が高い |
| rooms | 正 | 部屋数が多いほど価格が高い |
| age | 負 | 築年数が古いほど価格が低い |
最初の残差は 30.0 です。つまり、最初のテスト項目の実測価格は、モデル予測より約 30 単位高かったということです。スコアだけでは不十分で、残差を見るとモデルの弱い場所が分かります。
解法をどう選ぶか

毎日手で線形回帰を解く必要はありませんが、2 つの考え方は知っておきます。
| 解法 | 意味 | 気にする場面 |
|---|---|---|
| 正規方程式 / 最小二乗 | 最適な係数を直接求める | 小さな古典回帰、理論の直感 |
| 勾配降下法 | loss を下げながら係数を少しずつ改善する | 大規模データ、ニューラルネットワーク、独自目的関数 |
日常の sklearn では、まず LinearRegression() を使います。手書きの勾配降下法は、後のニューラルネットワークを理解するために学びます。
多項式と Ridge
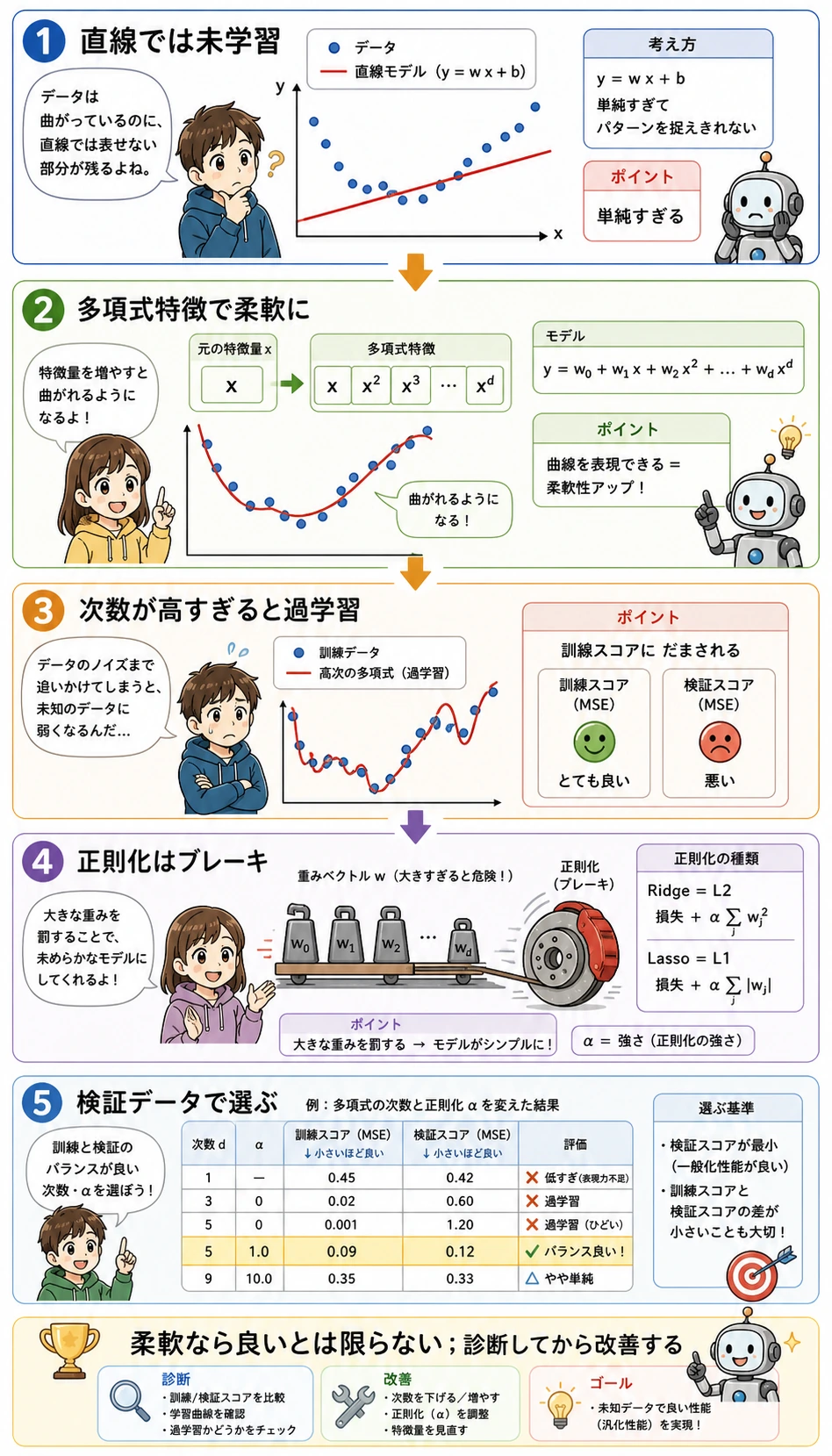
スクリプトでは次も試しています。
PolynomialFeatures(degree=2) -> StandardScaler -> Ridge(alpha=10)
これにより area * rooms のような交互作用を使えますが、Ridge がブレーキをかけ、モデルが自由に曲がりすぎないようにします。この合成データでは、多項式 Ridge は単純な線形モデルより悪いので、より安全なのは単純なモデルです。
残差を確認する
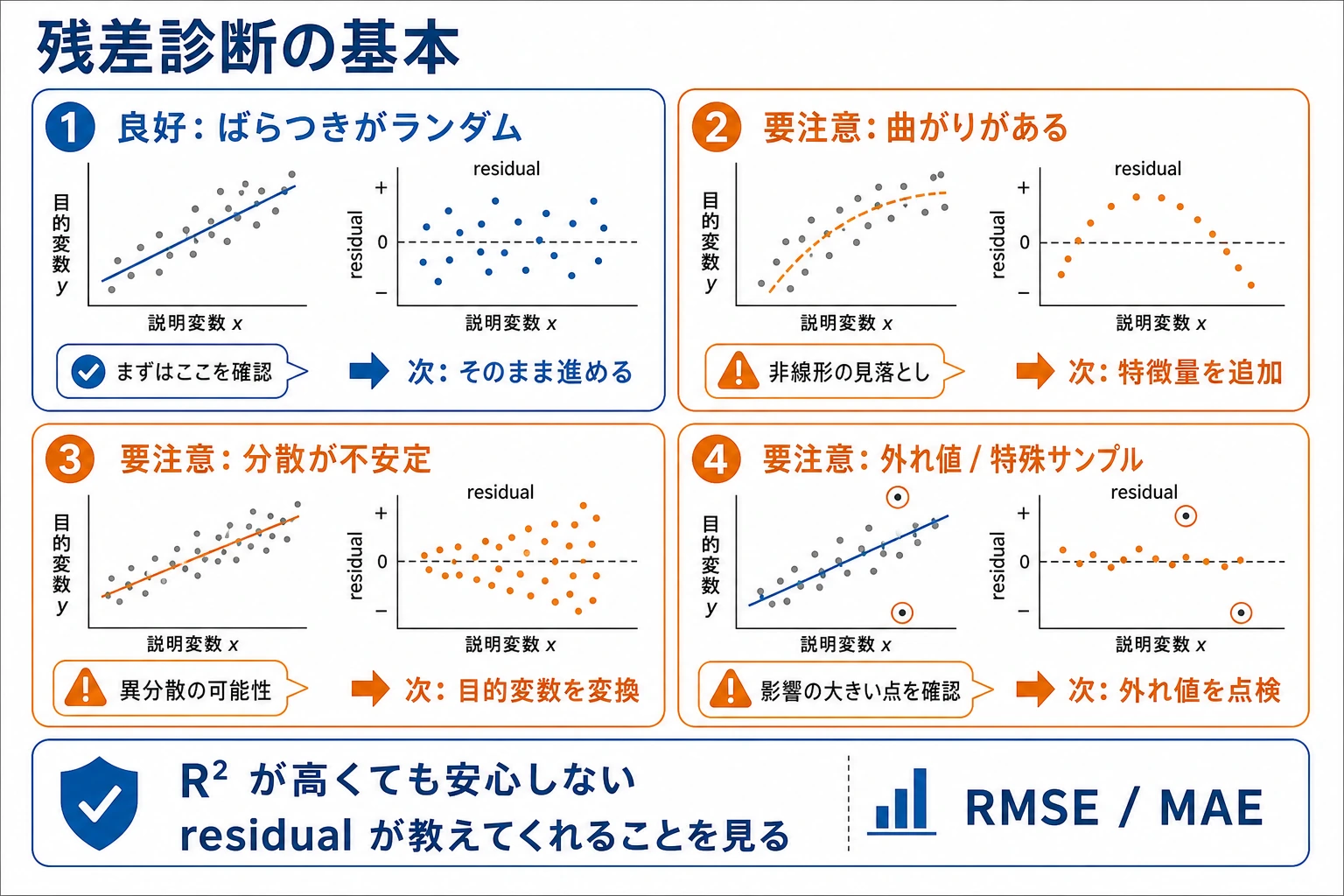
回帰モデルが良さそうに見えても、残差を確認します。
| 残差パターン | 意味 | 次の行動 |
|---|---|---|
| 0 の周りにランダム | 線形モデルで十分かもしれない | baseline と結果を記録する |
| 曲線形 | 関係が非線形かもしれない | 多項式、特徴量追加、別モデルを試す |
| 高い値ほどばらつく | 目標値が大きいほど誤差も大きい | 目標変換やロバスト指標を使う |
| 少数の大外れ | 外れ値または重要特徴量の欠落 | 行とデータ品質を見直す |
よくある失敗
| 症状 | 最初に確認 | よくある修正 |
|---|---|---|
| baseline から少ししか良くならない | 特徴量が弱い、または方向が違う | 使える列を追加し、相関を見る |
| R² は高いが個別ケースが悪い | 平均スコアが問題を隠している | 最大残差の行を表示する |
| 係数の向きが変 | データリークまたは特徴量相関 | 列と業務ロジックを確認する |
| 多項式モデルが悪化 | 過学習または尺度が不安定 | Ridge を使い、テストデータで比較する |
| 指標が説明しにくい | 目標値の単位が不明 | MAE/RMSE を業務単位で報告する |
練習
- noise を
12から30に増やし、RMSE と R² の変化を見る。 Xからageを外し、誤差が増えるか確認する。Ridge(alpha=10.0)をalpha=0.1とalpha=100.0に変える。- baseline RMSE、linear RMSE、最良モデル、残差例を短く記録する。
通過チェック
次を説明できれば、次のモデルへ進めます。
- 回帰モデルを評価する前に baseline が必要な理由。
- 係数、切片、予測、残差がどうつながるか。
- RMSE と MAE が答える問いの違い。
- 多項式特徴量が役に立つ場合と過学習する場合。
- 柔軟なモデルより単純なモデルが勝つことがある理由。