5.2.2 线性回归:baseline、残差、正则化
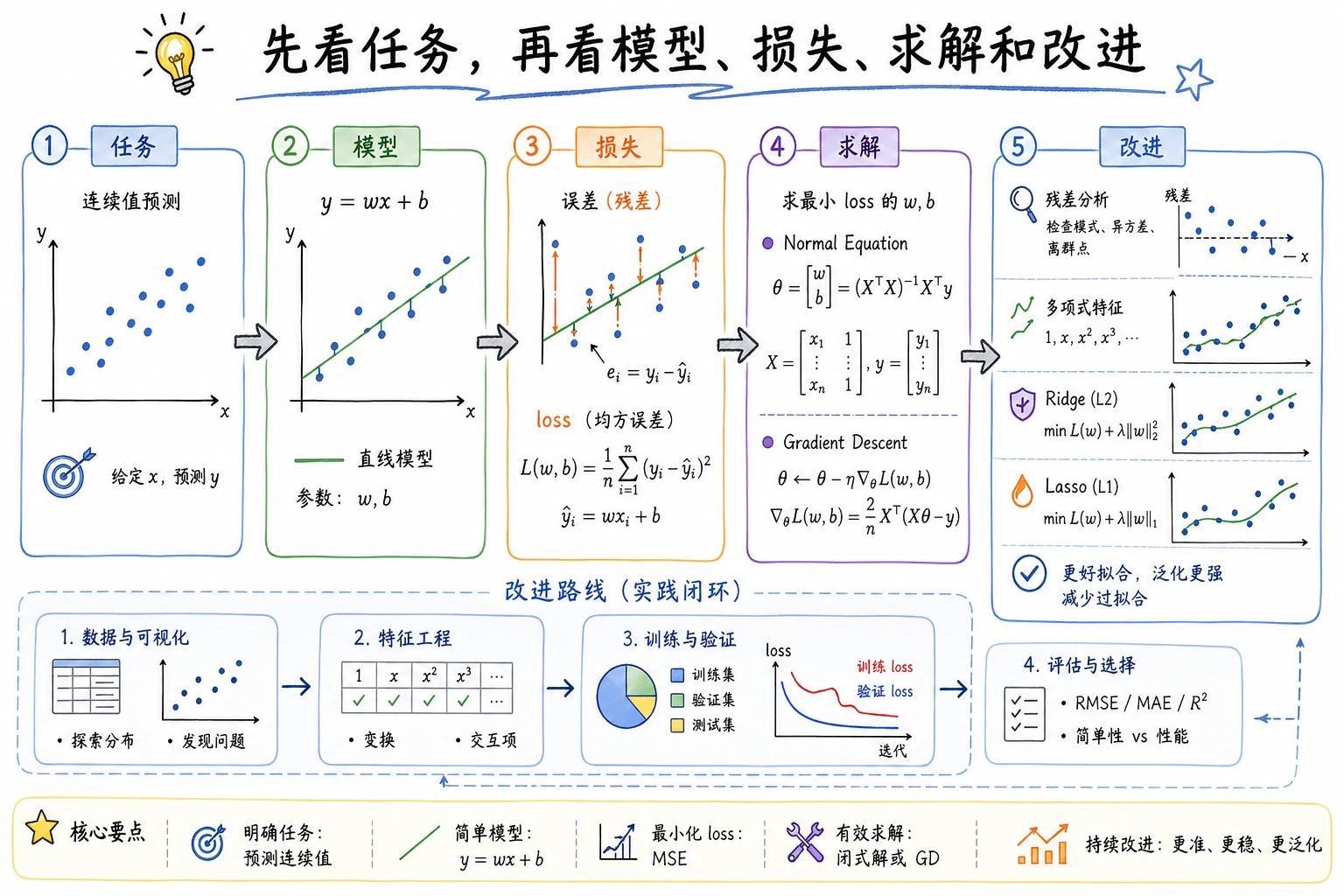
线性回归回答一个很实用的问题:能不能用几个输入数字解释或预测一个连续数值? 例如价格、销量、需求、温度、延迟或成本。
先看直觉

先记住这条线:
特征 -> 加权求和 -> 预测 -> 残差 -> 指标 -> 改进
| 词 | 第一层意思 |
|---|---|
| feature | 输入列,比如面积、房间数、房龄 |
| coefficient | 某个特征增加时,预测值会怎么变 |
| intercept | 还没加特征影响前的基础预测 |
| residual | 真实值 - 预测值 |
| RMSE | 典型误差大小,会更重罚大错 |
| MAE | 平均绝对误差,更容易解释 |
| R² | 模型解释目标变化的粗略比例 |
跑完整回归实验
新建 ch05_linear_regression_lab.py。
import numpy as np
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
rng = np.random.default_rng(42)
area = rng.uniform(45, 180, 80)
rooms = rng.integers(1, 5, 80)
age = rng.uniform(0, 30, 80)
noise = rng.normal(0, 12, 80)
price = 35 + 2.8 * area + 18 * rooms - 1.6 * age + noise
X = np.column_stack([area, rooms, age])
X_train, X_test, y_train, y_test = train_test_split(
X, price, test_size=0.25, random_state=42
)
baseline = np.full_like(y_test, y_train.mean())
model = LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
print("baseline_rmse=", round(mean_squared_error(y_test, baseline) ** 0.5, 2))
print("linear_rmse=", round(mean_squared_error(y_test, pred) ** 0.5, 2))
print("linear_mae=", round(mean_absolute_error(y_test, pred), 2))
print("linear_r2=", round(r2_score(y_test, pred), 3))
print("intercept=", round(model.intercept_, 2))
print("coefficients=", np.round(model.coef_, 2).tolist())
print("first_prediction=", round(pred[0], 2))
print("first_residual=", round(y_test[0] - pred[0], 2))
poly = Pipeline([
("poly", PolynomialFeatures(degree=2, include_bias=False)),
("scale", StandardScaler()),
("ridge", Ridge(alpha=10.0)),
])
poly.fit(X_train, y_train)
poly_pred = poly.predict(X_test)
print("ridge_poly_rmse=", round(mean_squared_error(y_test, poly_pred) ** 0.5, 2))
运行:
python ch05_linear_regression_lab.py
预期输出:
baseline_rmse= 123.23
linear_rmse= 11.68
linear_mae= 8.59
linear_r2= 0.991
intercept= 30.54
coefficients= [2.85, 17.97, -1.72]
first_prediction= 457.07
first_residual= 30.0
ridge_poly_rmse= 13.8
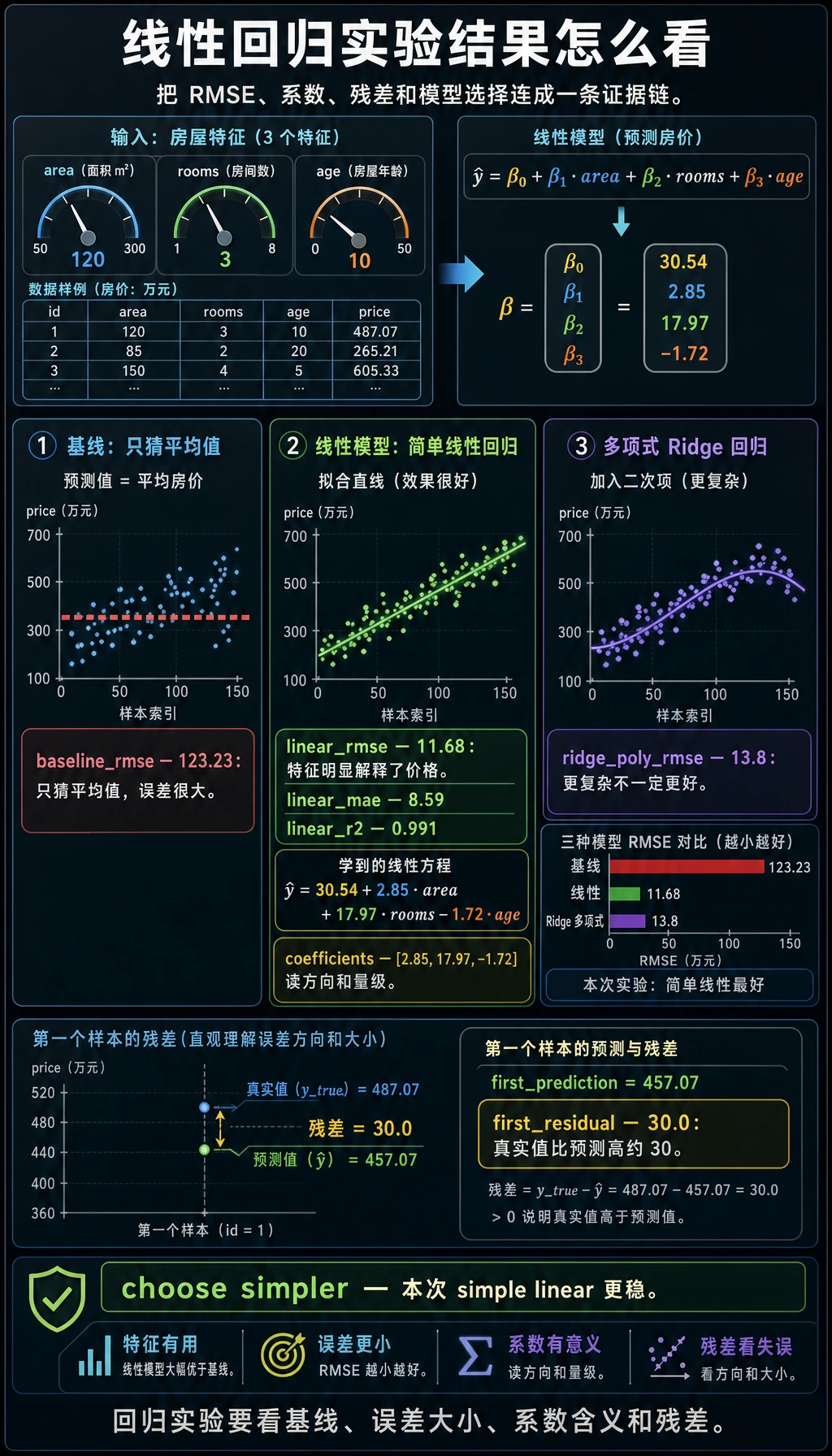
读懂结果
baseline 对每套房都预测训练集平均值。它的 RMSE 很大,说明这些特征确实有信息。
线性模型学到的规则接近隐藏的数据生成方式:
price ~= 30.54 + 2.85 * area + 17.97 * rooms - 1.72 * age
在这个合成数据里:
| 特征 | 学到的方向 | 解释 |
|---|---|---|
| area | 正向 | 面积越大,价格越高 |
| rooms | 正向 | 房间越多,价格越高 |
| age | 负向 | 房龄越老,价格越低 |
第一个残差是 30.0,表示第一个测试样本真实价格比模型预测高约 30 个价格单位。只看一个分数不够,残差能告诉你模型哪里弱。
求解方法怎么选

你不需要每天手推线性回归,但要知道两种思路:
| 求解方式 | 含义 | 什么时候关心 |
|---|---|---|
| 正规方程 / 最小二乘 | 直接算出最优系数 | 小型经典回归、理解理论 |
| 梯度下降 | 一步步降低 loss 来改系数 | 大数据、神经网络、自定义目标 |
日常 sklearn 里,先用 LinearRegression()。学习手写梯度下降,是为了理解后面的神经网络,而不是因为它是默认生产写法。
多项式与 Ridge

脚本里还尝试了:
PolynomialFeatures(degree=2) -> StandardScaler -> Ridge(alpha=10)
这让模型能使用 area * rooms 这样的交互项,但 Ridge 会加刹车,避免模型太自由。在这次合成数据里,多项式 Ridge 反而比简单线性模型差,所以更安全的选择是简单模型。
检查残差
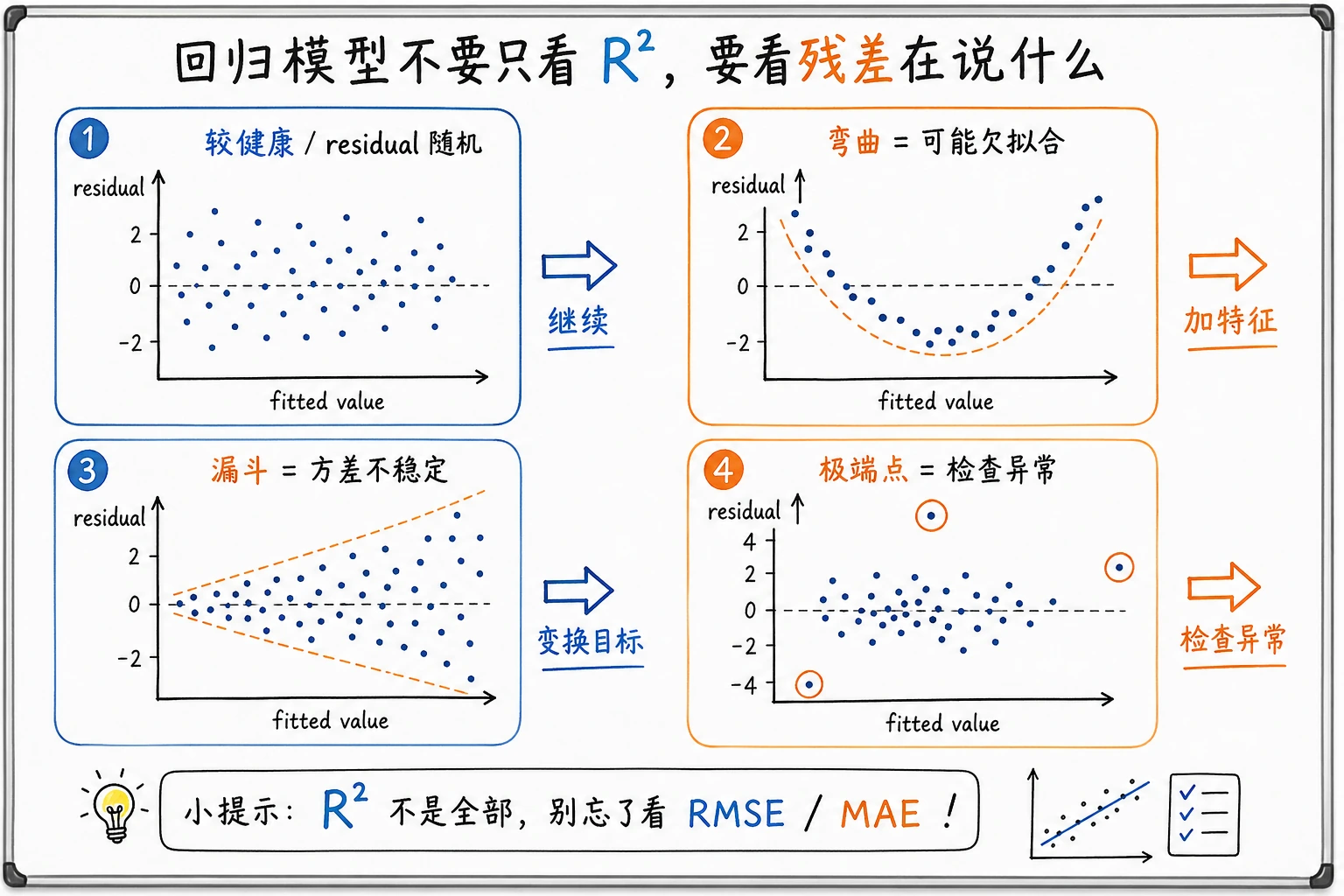
回归模型看起来不错时,仍然要看残差:
| 残差形态 | 说明 | 下一步 |
|---|---|---|
| 围绕 0 随机分布 | 线性模型可能够用 | 保留 baseline 并记录结果 |
| 出现弯曲形状 | 关系可能非线性 | 尝试多项式、特征构造或其他模型 |
| 高值处误差更散 | 目标越大误差越大 | 变换目标或用稳健指标 |
| 少数巨大误差 | 异常值或缺关键特征 | 回看样本和数据质量 |
常见错误
| 现象 | 先检查 | 常见修复 |
|---|---|---|
| 只比 baseline 好一点 | 特征弱或方向错 | 加有用列,检查相关性 |
| R² 很高但个别样本很差 | 平均分掩盖问题 | 打印最大残差样本 |
| 系数方向不合理 | 特征泄漏或特征相关 | 回看字段和业务逻辑 |
| 多项式模型更差 | 过拟合或尺度不稳 | 用 Ridge,并只比较测试集 |
| 指标不好解释 | 目标单位不清楚 | 用业务单位报告 MAE/RMSE |
练习
- 把噪声从
12改成30,观察 RMSE 和 R²。 - 从
X里删除age,看误差是否变大。 - 把
Ridge(alpha=10.0)改成alpha=0.1和alpha=100.0。 - 保存一段简短记录:baseline RMSE、linear RMSE、最佳模型、一个残差样本。
通关检查
能解释下面五件事,就可以进入下一个模型:
- 为什么评价回归模型前要先有 baseline;
- 系数、截距、预测和残差如何连接;
- RMSE 和 MAE 回答的问题有什么不同;
- 多项式特征什么时候有用,什么时候会过拟合;
- 为什么更简单的模型有时会赢过更灵活的模型。