5.2.6 SVM:最大间隔与核方法
本节定位
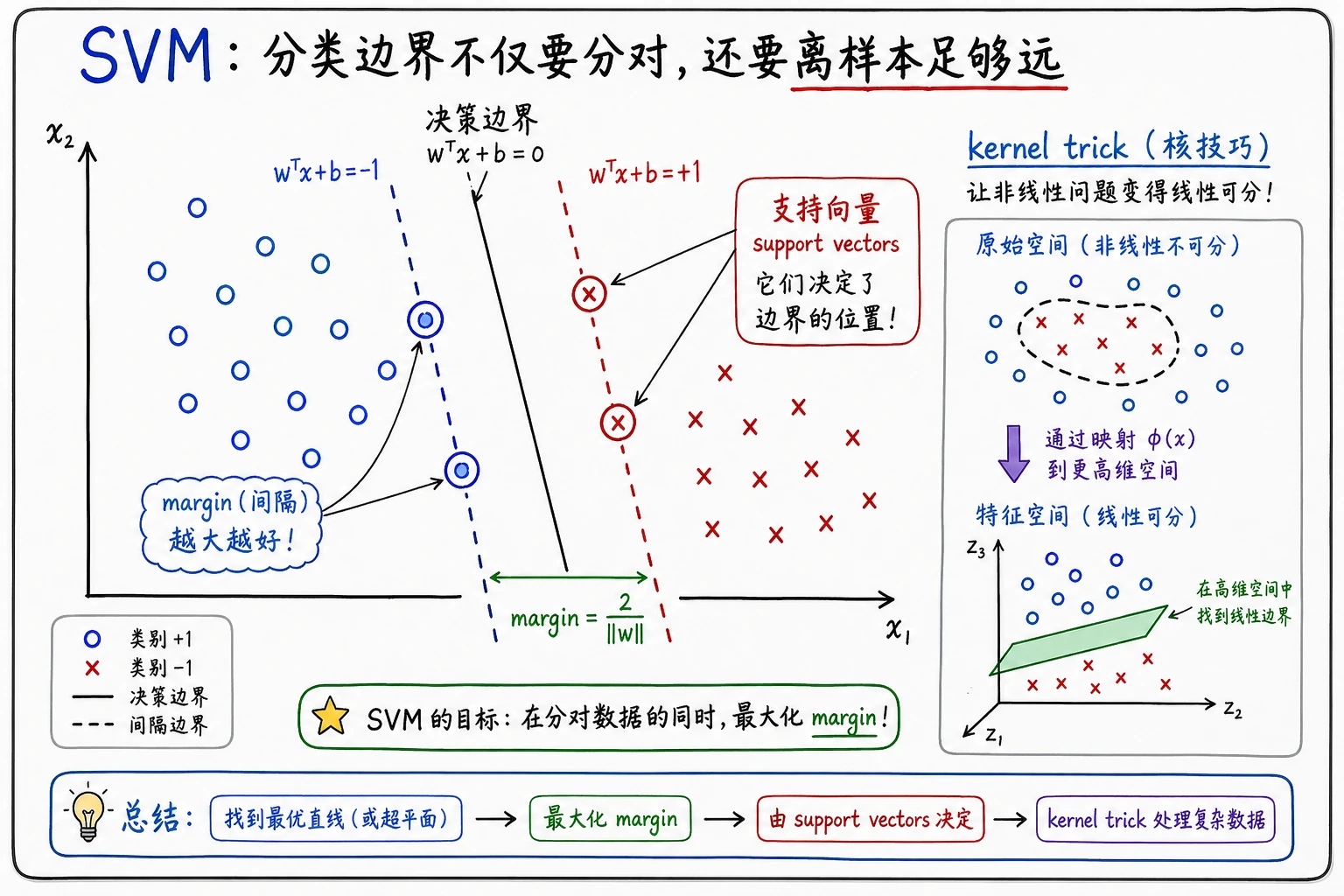
SVM 今天不一定是所有生产项目的首选模型,但它仍然是理解间隔、核方法、距离敏感模型的很好入口。
你会做出什么
这一节把 SVM 变成一个小实验。你会:
- 在弯曲数据集上比较
linear与rbf核; - 用实验验证为什么 SVM 必须重视
StandardScaler; - 调整
C和gamma,并观察支持向量数量; - 判断什么时候值得尝试 SVM,什么时候集成模型更省心。
最重要的一句话:
SVM 不只是问“有没有分对”,还会问“边界离最近的样本是否有足够空间”。
术语速查
| 术语 | 实用含义 |
|---|---|
SVM | Support Vector Machine,支持向量机,寻找大间隔边界的分类器 |
margin | 决策边界到最近样本的距离 |
support vector | 足够靠近边界、会影响边界位置的训练样本 |
kernel | 相似度函数,让 SVM 能形成非线性边界 |
RBF | Radial Basis Function,常用非线性核 |
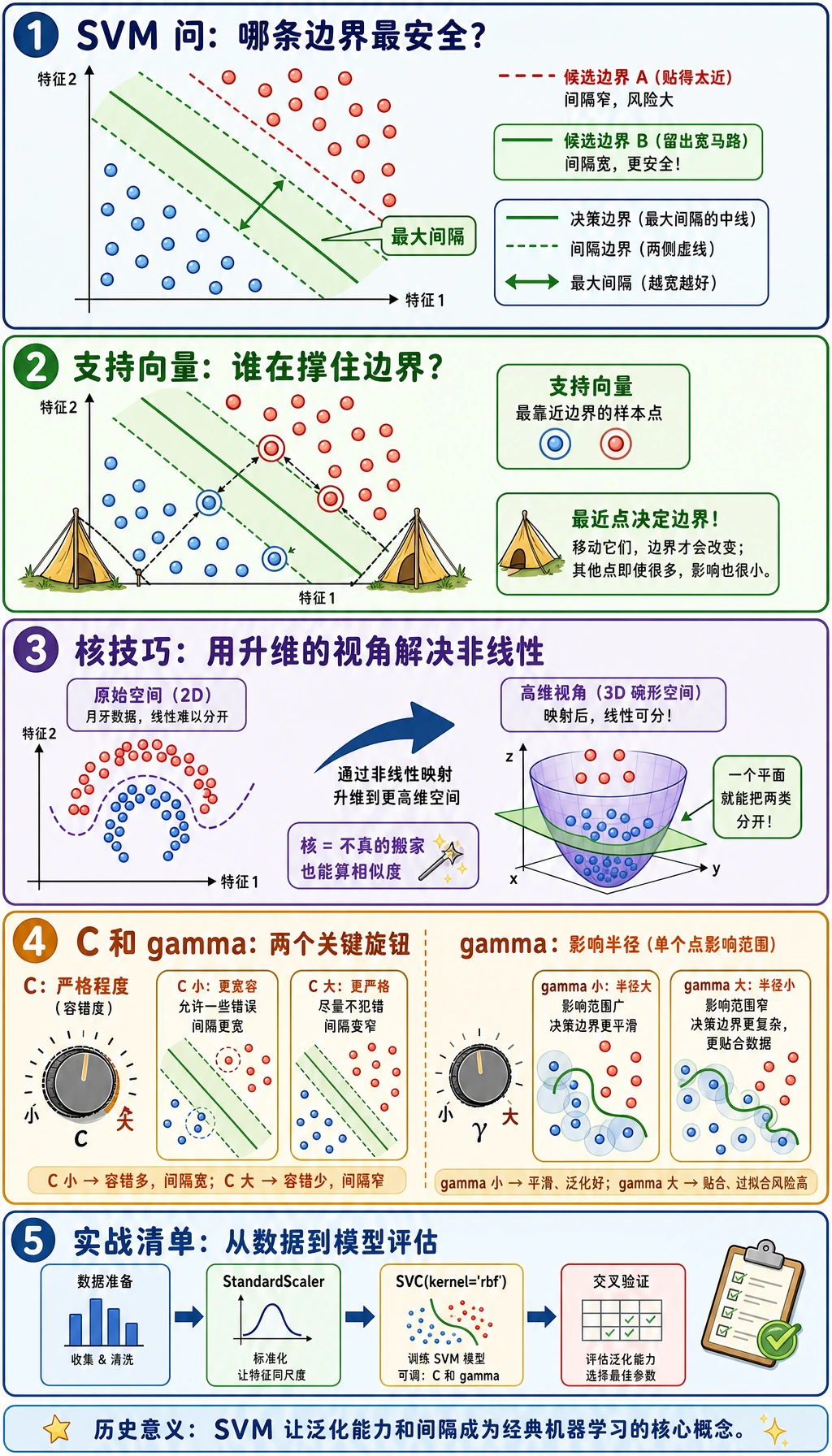
C | 错误惩罚强度;越大越努力贴合训练点 |
gamma | RBF 样本影响范围;越大边界越局部、越容易弯曲 |
SVC | sklearn 的支持向量分类器 |
环境准备
python -m pip install -U scikit-learn
SVM 对特征尺度很敏感,所以示例使用 Pipeline(StandardScaler(), SVC(...))。这不是装饰,而是模型流程的一部分。
运行完整实验
新建 svm_lab.py:
from itertools import product
from sklearn.datasets import make_moons
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
X, y = make_moons(n_samples=400, noise=0.25, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
print("kernel_comparison")
for kernel in ["linear", "rbf"]:
model = make_pipeline(StandardScaler(), SVC(kernel=kernel, C=1.0, gamma="scale"))
model.fit(X_train, y_train)
svc = model.named_steps["svc"]
print(
f"kernel={kernel:<6} "
f"accuracy={accuracy_score(y_test, model.predict(X_test)):.3f} "
f"support_vectors={int(svc.n_support_.sum())}"
)
print("scaling_check")
X_bad_scale = X.copy()
X_bad_scale[:, 1] *= 100
X_train2, X_test2, y_train2, y_test2 = train_test_split(
X_bad_scale, y, test_size=0.25, random_state=42, stratify=y
)
raw = SVC(kernel="rbf", C=1.0, gamma="scale")
raw.fit(X_train2, y_train2)
scaled = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=1.0, gamma="scale"))
scaled.fit(X_train2, y_train2)
print(f"without_scaling={accuracy_score(y_test2, raw.predict(X_test2)):.3f}")
print(f"with_scaling={accuracy_score(y_test2, scaled.predict(X_test2)):.3f}")
print("c_gamma_lab")
for C, gamma in product([0.1, 1.0, 10.0], [0.1, 1.0]):
model = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=C, gamma=gamma))
model.fit(X_train, y_train)
svc = model.named_steps["svc"]
print(
f"C={C:<4} gamma={gamma:<3} "
f"accuracy={accuracy_score(y_test, model.predict(X_test)):.3f} "
f"support_vectors={int(svc.n_support_.sum())}"
)
运行:
python svm_lab.py
预期输出:
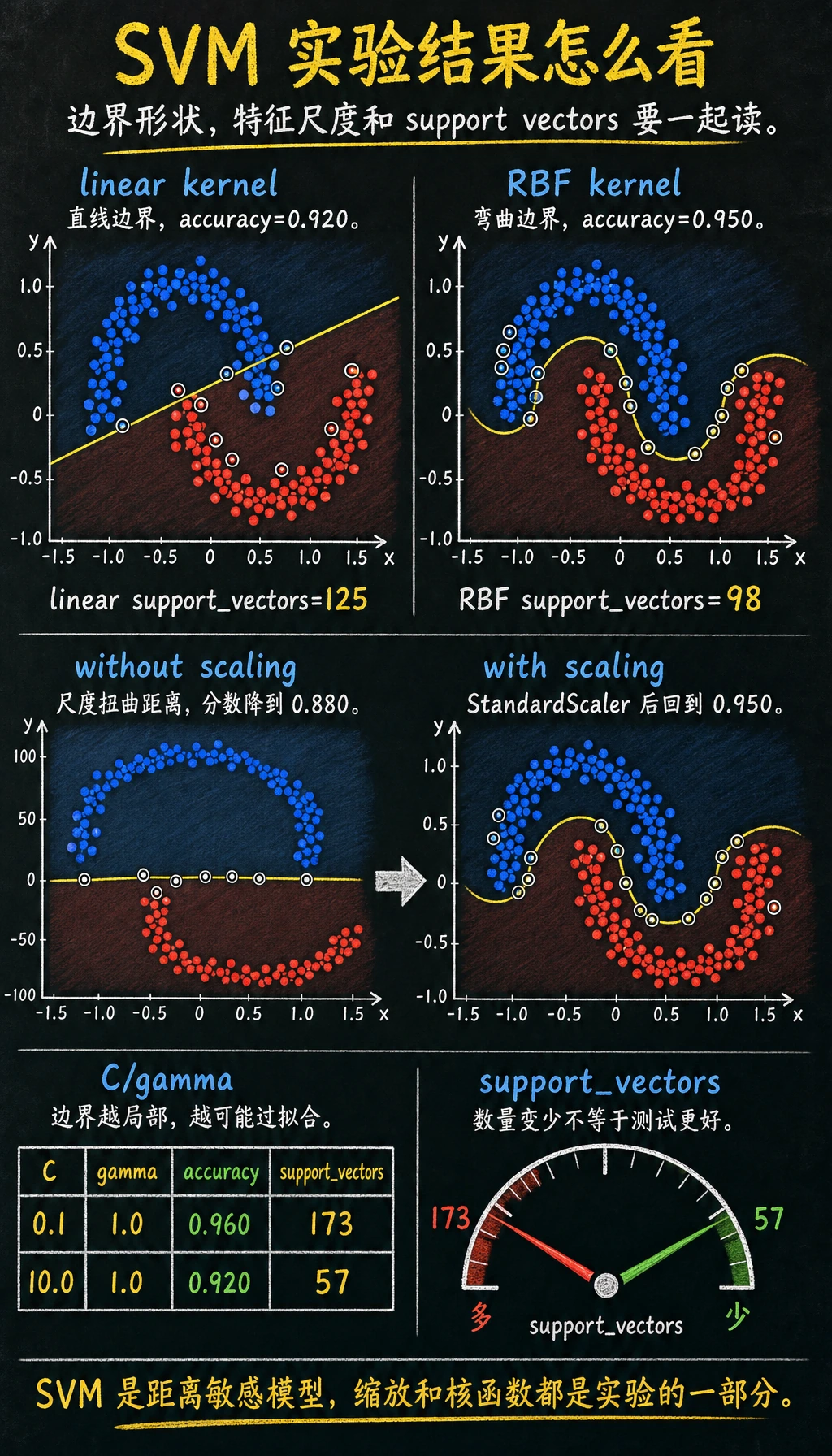
kernel_comparison
kernel=linear accuracy=0.920 support_vectors=125
kernel=rbf accuracy=0.950 support_vectors=98
scaling_check
without_scaling=0.880
with_scaling=0.950
c_gamma_lab
C=0.1 gamma=0.1 accuracy=0.940 support_vectors=187
C=0.1 gamma=1.0 accuracy=0.960 support_vectors=173
C=1.0 gamma=0.1 accuracy=0.950 support_vectors=134
C=1.0 gamma=1.0 accuracy=0.930 support_vectors=87
C=10.0 gamma=0.1 accuracy=0.960 support_vectors=111
C=10.0 gamma=1.0 accuracy=0.920 support_vectors=57
读懂核函数结果
make_moons 是一个弯曲数据集,故意让直线边界吃点亏:
kernel=linear accuracy=0.920 support_vectors=125
kernel=rbf accuracy=0.950 support_vectors=98
linear 核尝试用直线分开两类。rbf 核比较局部相似度,因此能形成弯曲边界。先按这个规则选择:
| 情况 | SVM 的第一选择 |
|---|---|
| 边界大致像直线 | kernel="linear" |
| 边界弯曲,数据量不大 | kernel="rbf" |
| 行数或特征很多 | 先试逻辑回归、线性 SVM 或树集成 |
为什么缩放不是可选项
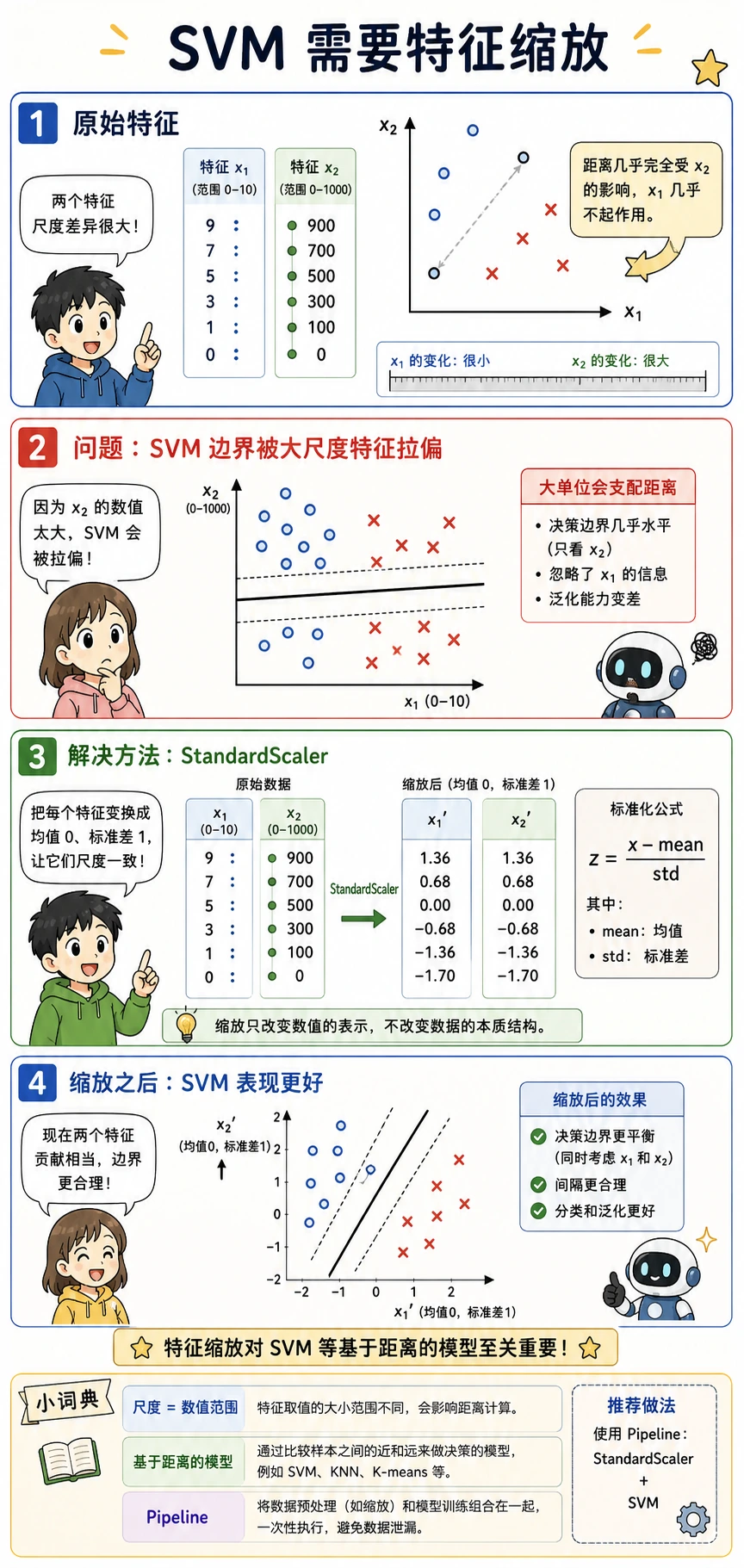
SVM 依赖距离和相似度。如果一个特征范围是 0-1,另一个特征范围是 0-1000,后者即使不更重要,也可能主导边界。
实验直接暴露了这个问题:
without_scaling=0.880
with_scaling=0.950
所以 StandardScaler 应该放在 Pipeline 里:只在训练折上 fit,再安全地应用到验证/测试数据。
理解 C 和 gamma

C 和 gamma 控制边界的不同方面:
| 参数 | 太小时 | 太大时 |
|---|---|---|
C | 容忍更多错误,间隔更宽、更平滑 | 更努力追训练点 |
gamma | 影响范围宽,边界可能过于平滑 | 影响范围局部,边界可能很弯 |
看输出时同时看两个信号:
C=0.1 gamma=1.0 accuracy=0.960 support_vectors=173
C=10.0 gamma=1.0 accuracy=0.920 support_vectors=57
第二个模型支持向量更少,但测试准确率更差。支持向量少不一定更好,可能表示边界过尖、泛化变差。
给有经验的读者:C 和 gamma 应该用交叉验证一起调,并和逻辑回归、集成模型基线对比,不要只凭一次 train-test split 决定。
支持向量在实战中的意义
支持向量是离边界足够近、会影响边界的样本。它们适合用来做诊断:
- 支持向量很多,可能说明边界不确定或间隔较软;
- 支持向量很少但测试分数差,可能说明边界过尖;
- 支持向量数量只是诊断线索,不是最终指标。
如果你需要校准后的概率,要注意 SVC(probability=True) 会额外训练校准步骤,训练会更慢。概率质量很重要时,通常用 CalibratedClassifierCV 更清晰。
什么时候用 SVM
值得尝试 SVM 的情况:
- 数据集是小到中等规模;
- 特征以数值为主,并且可以稳定缩放;
- 需要强一点的非线性分类器,但还不想上神经网络;
- 想理解基于间隔的分类思想。
更适合其他模型的情况:
- 数据量很大,需要快速训练;
- 类别特征很多,预处理很重;
- 产品核心依赖可靠概率;
- 树集成模型已经更准、更稳、调参更少。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| SVM 效果明显低于预期 | 特征没有缩放 | 在 Pipeline 中使用 StandardScaler |
| 训练很慢 | RBF SVM 不适合特别大的数据 | 尝试线性模型、LinearSVC 或集成模型 |
| 边界太弯 | gamma 或 C 太大 | 降低 gamma,降低 C,用交叉验证 |
| 线性模型抓不住弯曲模式 | 非线性关系却用了 linear | 对比 kernel="rbf" |
| 需要可靠概率 | 原始 SVM 分数不是校准概率 | 使用校准并检查概率指标 |
练习
- 把
make_moons()里的noise从0.25改成0.1和0.4。哪些设置让 SVM 更容易或更难? - 在网格中加入
gamma=5.0。accuracy 和支持向量数量怎么变? - 在线性核场景里把
SVC换成LinearSVC。可用属性有什么变化? - 在同一数据集上运行逻辑回归,和 RBF SVM 对比。
- 用交叉验证选择
C和gamma,不要只相信一次切分。
过关检查
你能解释下面几点,就完成本节:
- SVM 寻找大间隔边界;
- 支持向量是影响边界的关键训练点;
- RBF 核可以建模弯曲边界;
- SVM 使用距离,所以缩放很重要;
C和gamma要一起调,最好配合交叉验证。