5.2.5 集成学习:森林、Boosting、Stacking
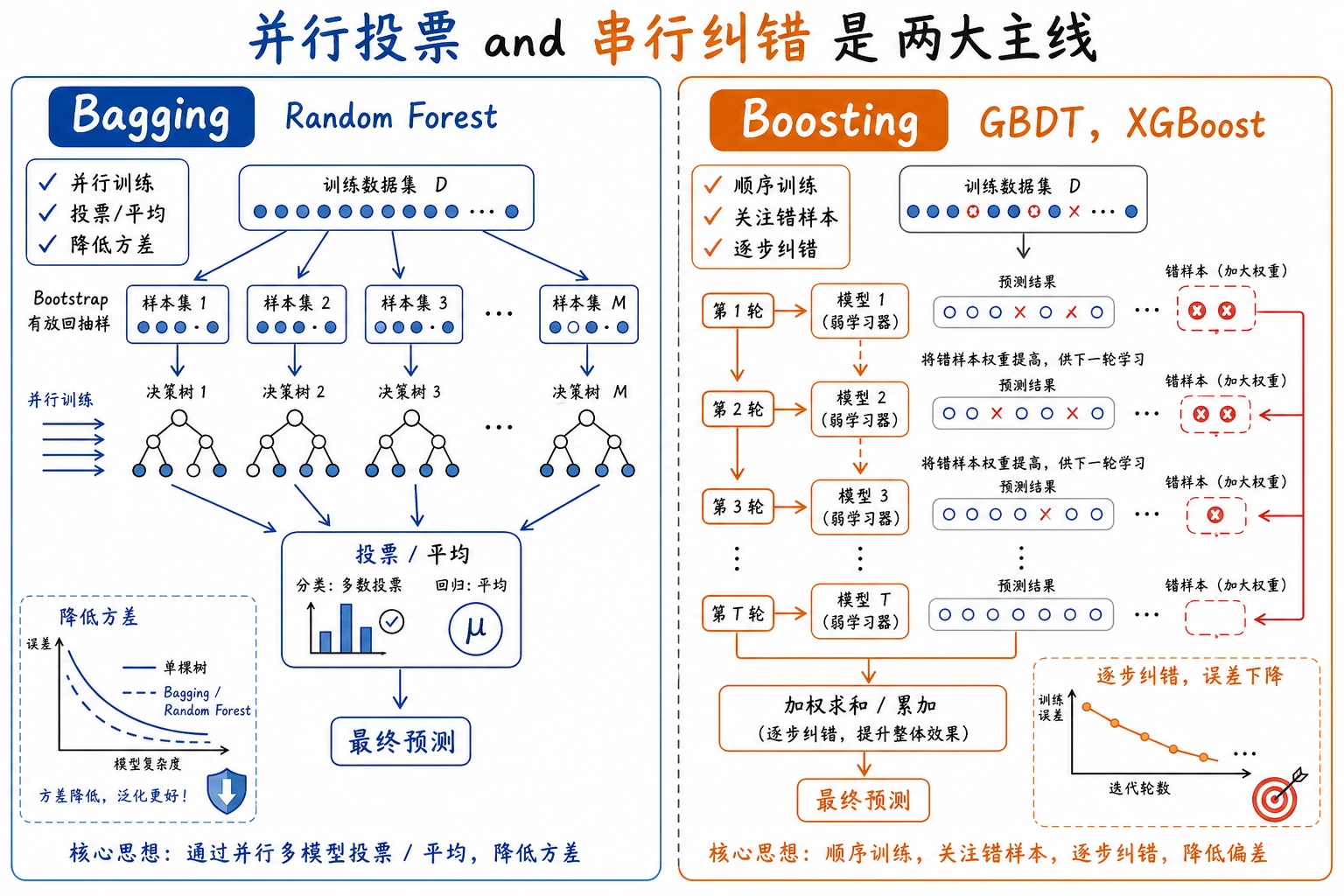
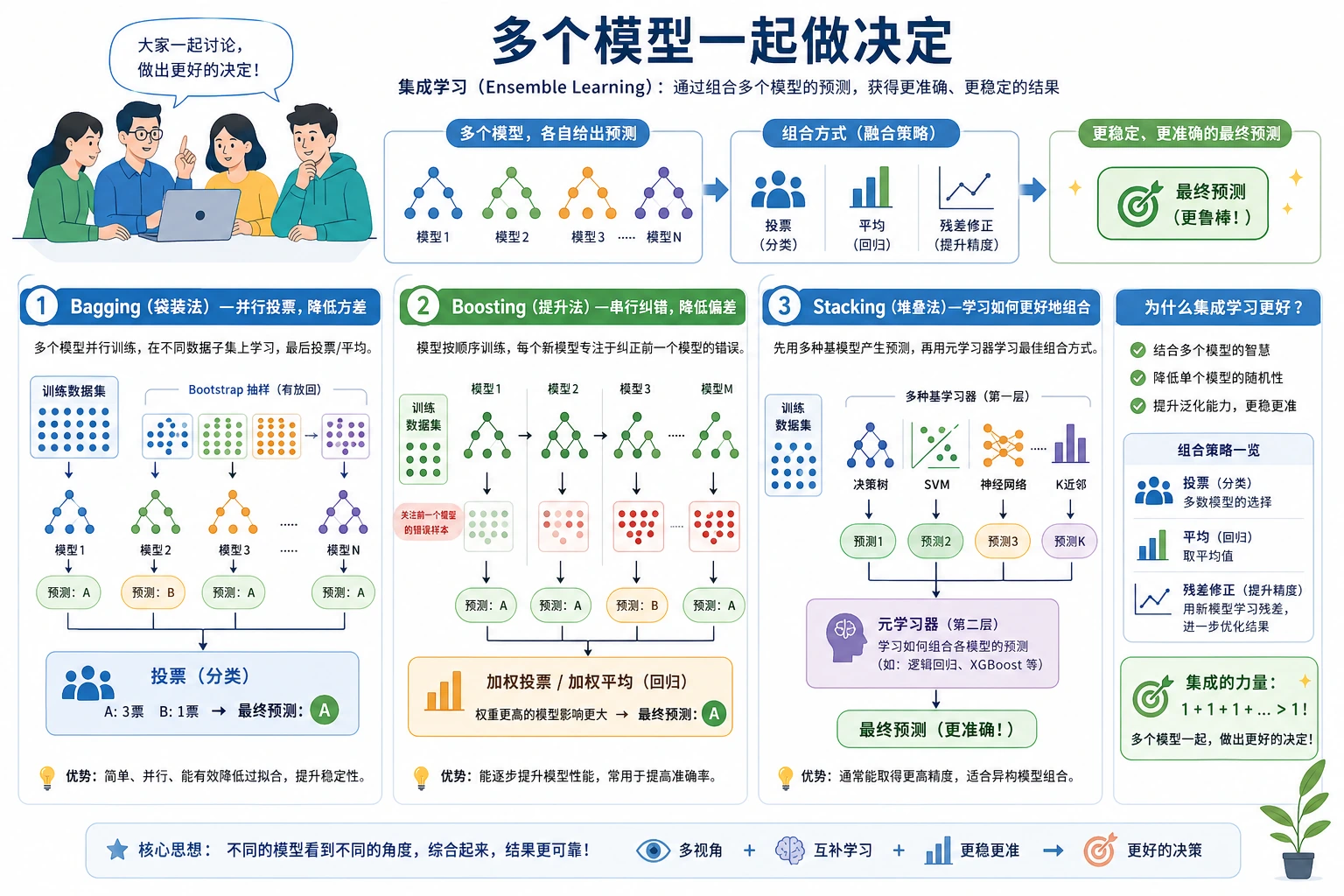
集成学习会把多个模型组合起来,减少单个模型弱点主导结果的风险。对表格数据来说,它经常是经典机器学习里最强的一类方法。
先看两条主线
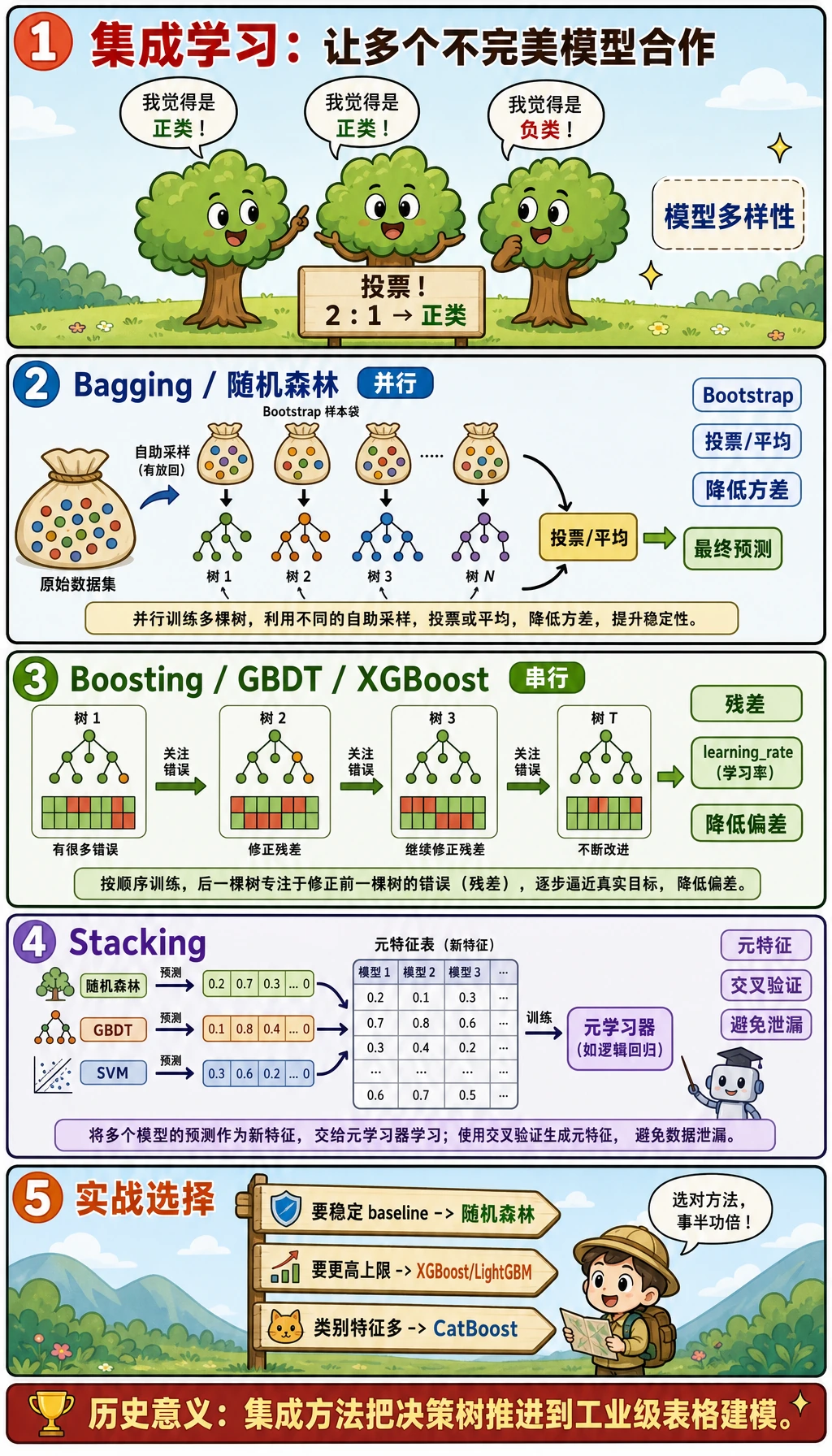
不要一上来背模型名,先分清两种主思路:
| 路线 | 画面感 | 代表模型 | 主要收益 | 主要风险 |
|---|---|---|---|---|
| Bagging | 多个模型并行训练后投票 | Random Forest | 稳定、降低方差 | 模型变大、解释性下降 |
| Boosting | 后一个模型专门补前一个模型的错 | GBDT、XGBoost、LightGBM、CatBoost | 精度强 | 不控制容易过拟合 |
| Stacking | 基模型预测再喂给元模型 | StackingClassifier | 组合不同模型家族 | 如果不用交叉验证会泄漏 |
跑模型对比实验
新建 ch05_ensemble_lab.py。
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data,
data.target,
test_size=0.25,
random_state=42,
stratify=data.target,
)
models = {
"single_tree": DecisionTreeClassifier(max_depth=4, random_state=42),
"random_forest": RandomForestClassifier(
n_estimators=200,
max_depth=6,
random_state=42,
),
"gradient_boost": GradientBoostingClassifier(
n_estimators=120,
learning_rate=0.05,
max_depth=2,
random_state=42,
),
}
models["stacking_cv"] = StackingClassifier(
estimators=[
("rf", models["random_forest"]),
("gb", models["gradient_boost"]),
("lr", make_pipeline(
StandardScaler(),
LogisticRegression(max_iter=2000, random_state=42),
)),
],
final_estimator=LogisticRegression(max_iter=2000, random_state=42),
cv=5,
)
for name, model in models.items():
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f"{name:<15} accuracy={accuracy_score(y_test, pred):.3f} f1={f1_score(y_test, pred):.3f}")
rf = models["random_forest"]
importances = rf.feature_importances_
top = importances.argsort()[-3:][::-1]
print("top_rf_features=")
for idx in top:
print(f"- {data.feature_names[idx]}: {importances[idx]:.3f}")
运行:
python ch05_ensemble_lab.py
预期输出:
single_tree accuracy=0.944 f1=0.956
random_forest accuracy=0.958 f1=0.967
gradient_boost accuracy=0.944 f1=0.956
stacking_cv accuracy=0.986 f1=0.989
top_rf_features=
- worst perimeter: 0.146
- worst area: 0.140
- worst concave points: 0.109
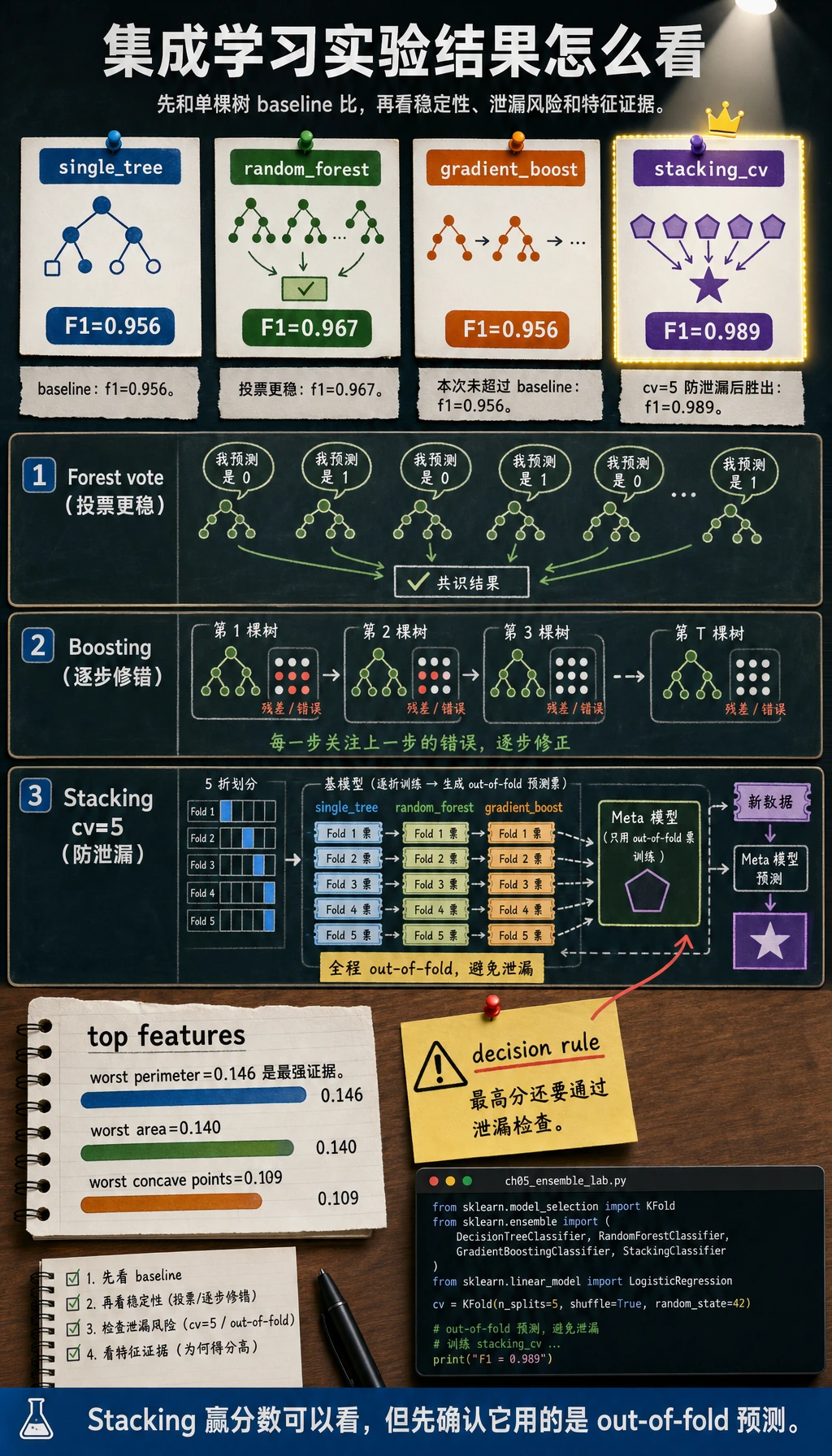
不同 sklearn 版本分数可能略有变化。保留对比表和重要特征,作为项目证据。
读懂结果
单棵树是 baseline。随机森林通过平均很多棵不同的树,通常会更稳定。
Boosting 不会在每个小数据集里自动更好。它需要控制树深、学习率、树数量和验证集表现。
Stacking 这里可能赢,是因为它组合了不同模型家族;但它必须用交叉验证。元模型如果直接看到基模型在训练行上的预测,就会发生信息泄漏。
Bagging:随机森林
随机森林会在随机化的数据视角上训练很多决策树,再对它们的预测做平均或投票。
优先记这些设置:
| 参数 | 控制什么 | 新手默认 |
|---|---|---|
n_estimators | 树的数量 | 100 到 300 |
max_depth | 树深 | 先小后大 |
min_samples_leaf | 叶子最少样本数 | 过拟合时调大 |
random_state | 可复现 | 学习时总是设置 |
Boosting:GBDT 与工具链
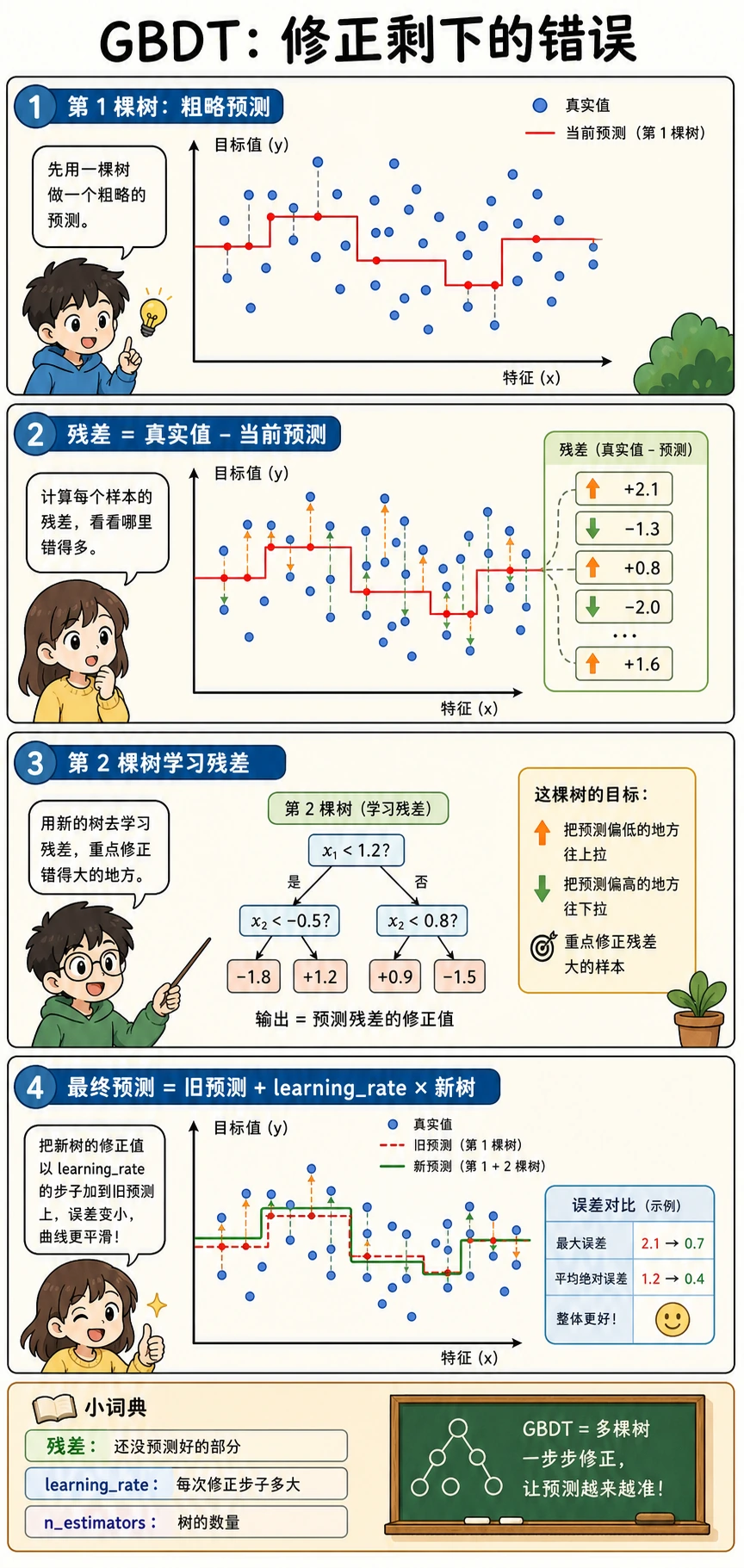
Boosting 是顺序建模:
第一棵小树 -> 找错误 -> 下一棵小树关注错误 -> 重复
在 sklearn 里,先从 GradientBoostingClassifier 或 HistGradientBoostingClassifier 开始。真实表格项目里,XGBoost、LightGBM、CatBoost 很常见,但不要在 sklearn baseline 还没清楚前就直接加外部库。
Boosting 第一次调参顺序:
| 步骤 | 调什么 | 为什么 |
|---|---|---|
| 1 | learning_rate 和 n_estimators | 控制步长和训练轮数 |
| 2 | max_depth / 叶子设置 | 控制复杂度 |
| 3 | 验证集或 early stopping | 防止过拟合 |
| 4 | 特征预处理 | 提高信号质量 |
安全使用 Stacking
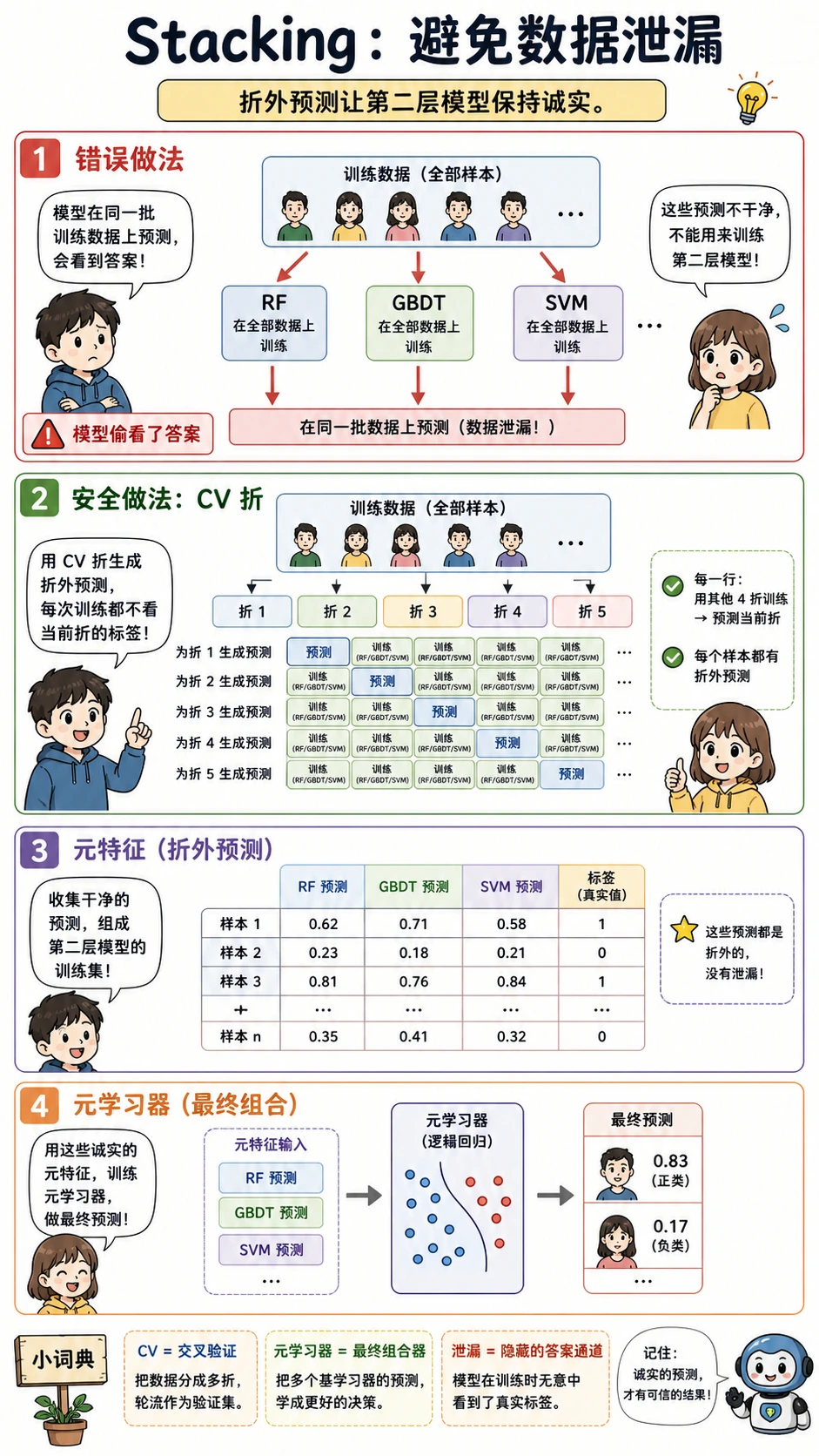
Stacking 只有在元模型看到 out-of-fold 预测时才可靠:
在 CV 折里训练基模型 -> 收集 out-of-fold 预测 -> 训练元模型 -> 在 holdout test 上评估
优先用 sklearn 的 StackingClassifier(cv=5),不要手动把训练行上的预测直接喂给元模型。
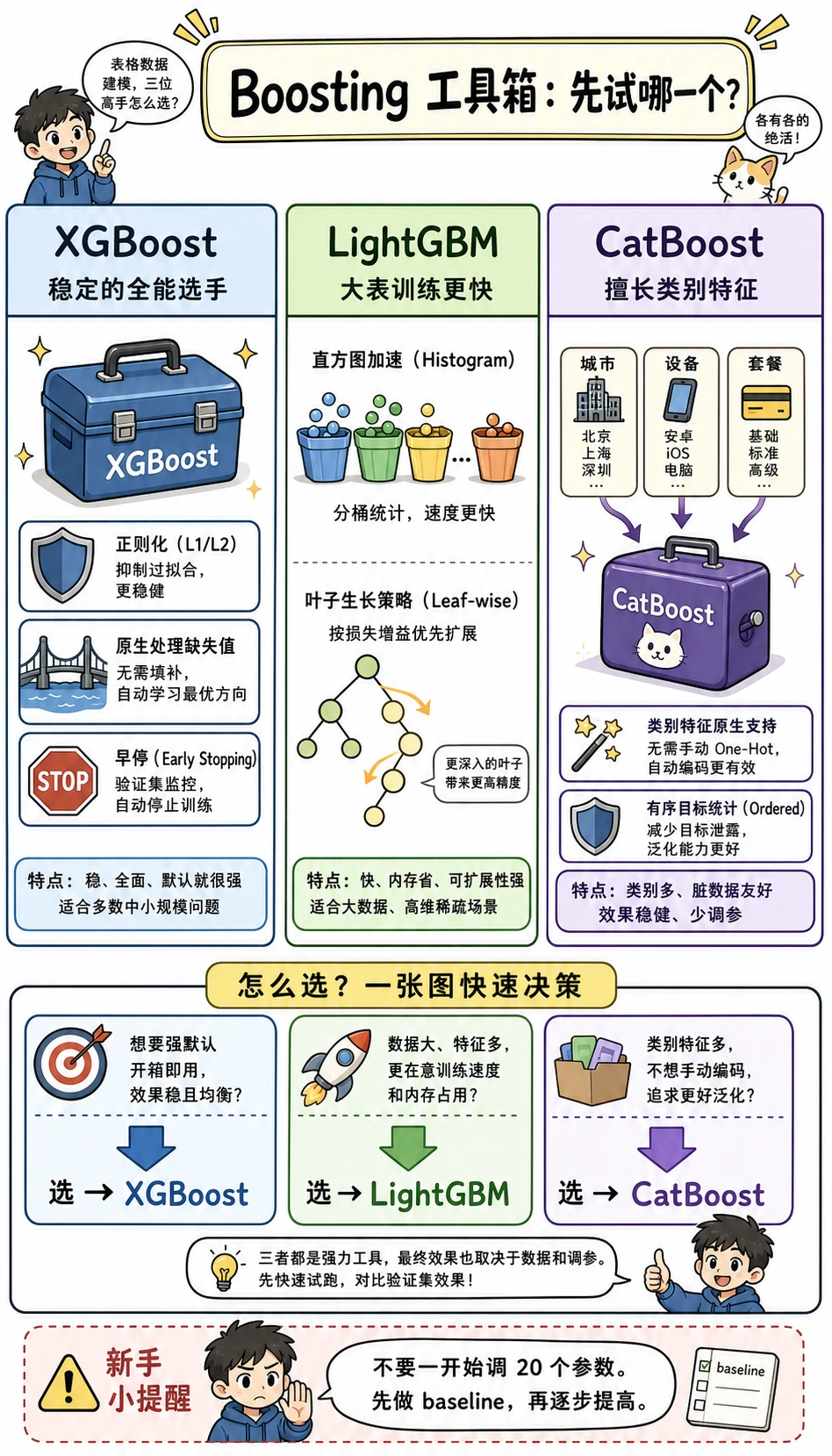
怎么选模型
| 场景 | 先用 |
|---|---|
| 需要强而稳的 baseline | Random Forest |
| 表格数据有很多非线性 | Gradient Boosting / XGBoost / LightGBM |
| 类别特征很多 | CatBoost,放在 baseline 之后 |
| 不同模型家族表现互补 | 带交叉验证的 Stacking |
| 需要最容易解释 | 浅树或随机森林特征重要性 |
常见错误
| 现象 | 先检查 | 常见修复 |
|---|---|---|
| 集成模型几乎不比单树好 | 特征弱或划分不稳定 | 加特征,用交叉验证 |
| 训练好、测试差 | 过拟合 | 降低深度、增大叶子样本、加验证 |
| Boosting 树越多越差 | 轮数太多 | 降低学习率或 early stopping |
| Stacking 分数异常完美 | 信息泄漏 | 用 out-of-fold 预测或 StackingClassifier(cv=...) |
| 过度解读特征重要性 | 特征相关性强 | 用 permutation importance 或消融验证 |
练习
- 把随机森林
max_depth从6改成3和None。 - 把 Gradient Boosting 的
learning_rate从0.05改成0.2。 - 解释如果 Stacking 不用交叉验证,为什么会泄漏。
- 保存模型对比表,并写一段话说明你会先上线哪个模型。
通关检查
能解释下面五件事,就可以继续:
- Bagging 和 Boosting 有什么区别;
- 为什么随机森林通常比单棵树更稳;
- 为什么 Boosting 需要验证集控制;
- 为什么 Stacking 必须用交叉验证;
- 为什么排行榜最高分不一定是最适合生产的选择。