5.2.5 アンサンブル学習:Forest、Boosting、Stacking
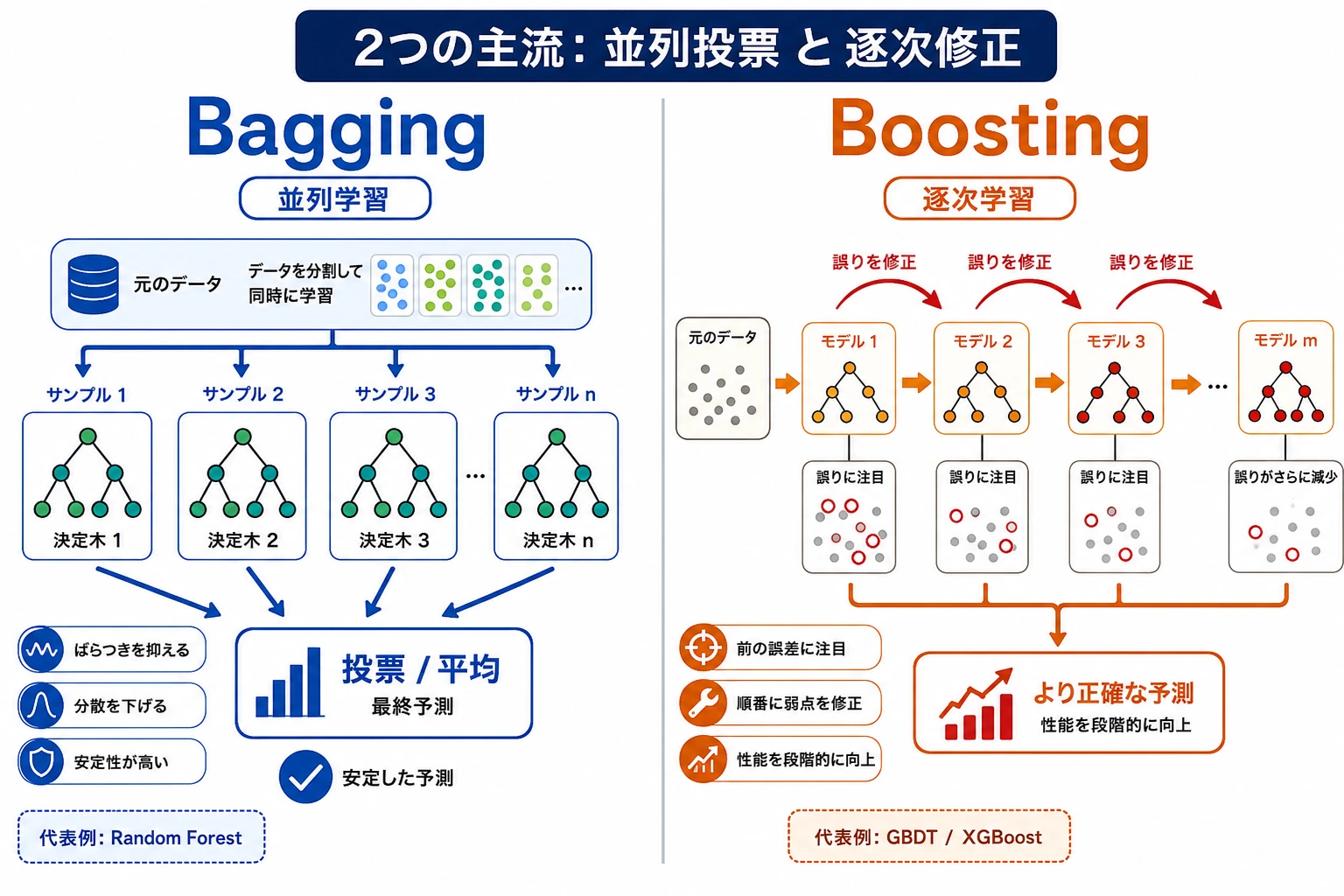
アンサンブル学習は複数のモデルを組み合わせ、1つのモデルの弱点が最終予測を支配しにくくします。表形式データでは、古典的機械学習の中でも特に強い手法群です。
まず二つの主線を見る
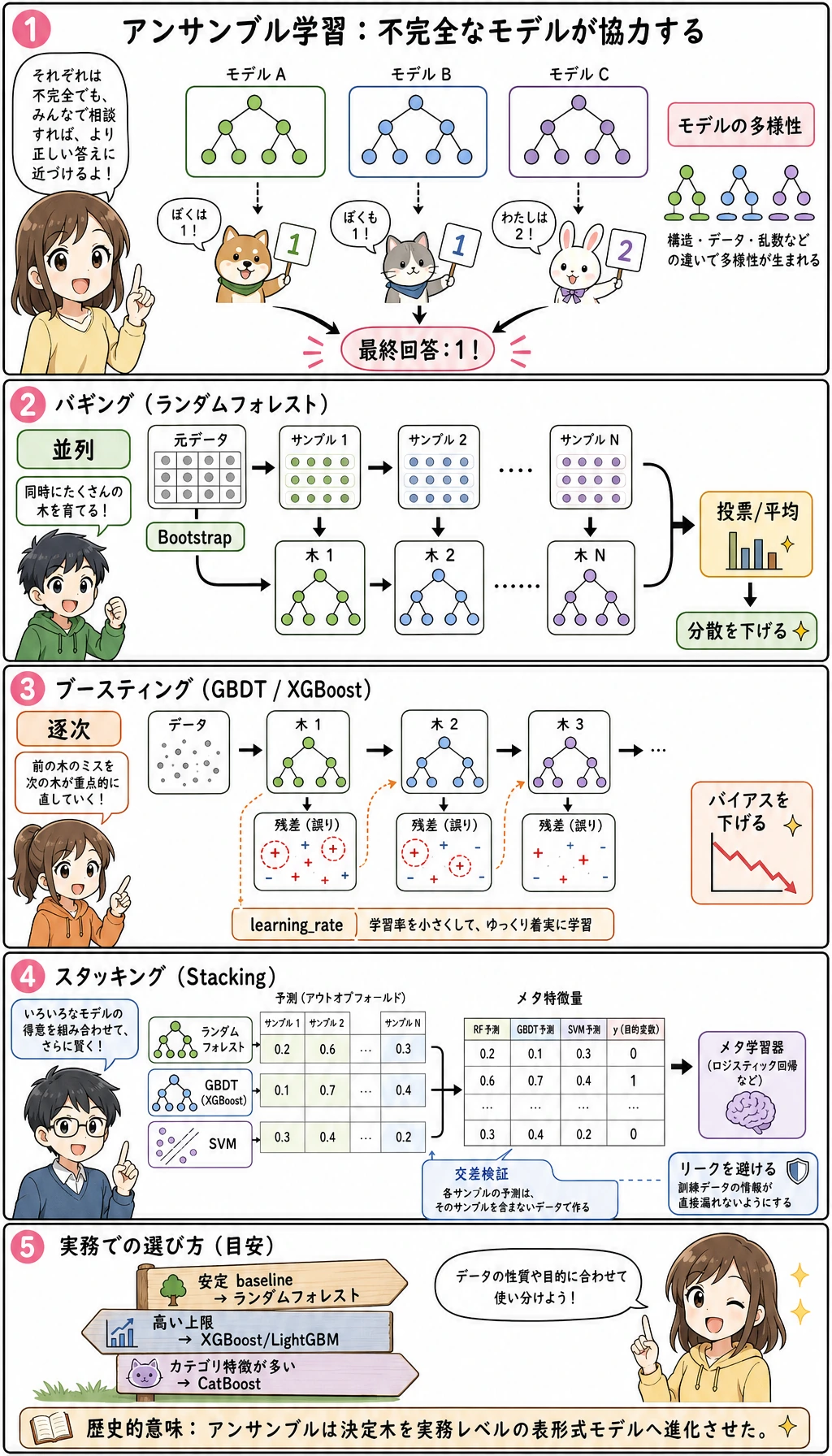
最初からモデル名を暗記しないでください。まず二つの考え方を分けます。
| ルート | イメージ | 代表モデル | 主な利点 | 主なリスク |
|---|---|---|---|---|
| Bagging | 複数モデルを並列に学習して投票 | Random Forest | 安定し、分散を下げる | 大きくなり、説明しづらい |
| Boosting | 後続モデルが前の誤りを補正 | GBDT、XGBoost、LightGBM、CatBoost | 精度が強い | 制御しないと過学習しやすい |
| Stacking | 基本モデルの予測をメタモデルへ渡す | StackingClassifier | 異なるモデル群を組み合わせる | 交差検証なしだとリークする |
比較実験を動かす
ch05_ensemble_lab.py を作成します。
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data,
data.target,
test_size=0.25,
random_state=42,
stratify=data.target,
)
models = {
"single_tree": DecisionTreeClassifier(max_depth=4, random_state=42),
"random_forest": RandomForestClassifier(
n_estimators=200,
max_depth=6,
random_state=42,
),
"gradient_boost": GradientBoostingClassifier(
n_estimators=120,
learning_rate=0.05,
max_depth=2,
random_state=42,
),
}
models["stacking_cv"] = StackingClassifier(
estimators=[
("rf", models["random_forest"]),
("gb", models["gradient_boost"]),
("lr", make_pipeline(
StandardScaler(),
LogisticRegression(max_iter=2000, random_state=42),
)),
],
final_estimator=LogisticRegression(max_iter=2000, random_state=42),
cv=5,
)
for name, model in models.items():
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f"{name:<15} accuracy={accuracy_score(y_test, pred):.3f} f1={f1_score(y_test, pred):.3f}")
rf = models["random_forest"]
importances = rf.feature_importances_
top = importances.argsort()[-3:][::-1]
print("top_rf_features=")
for idx in top:
print(f"- {data.feature_names[idx]}: {importances[idx]:.3f}")
実行します。
python ch05_ensemble_lab.py
期待される出力:
single_tree accuracy=0.944 f1=0.956
random_forest accuracy=0.958 f1=0.967
gradient_boost accuracy=0.944 f1=0.956
stacking_cv accuracy=0.986 f1=0.989
top_rf_features=
- worst perimeter: 0.146
- worst area: 0.140
- worst concave points: 0.109
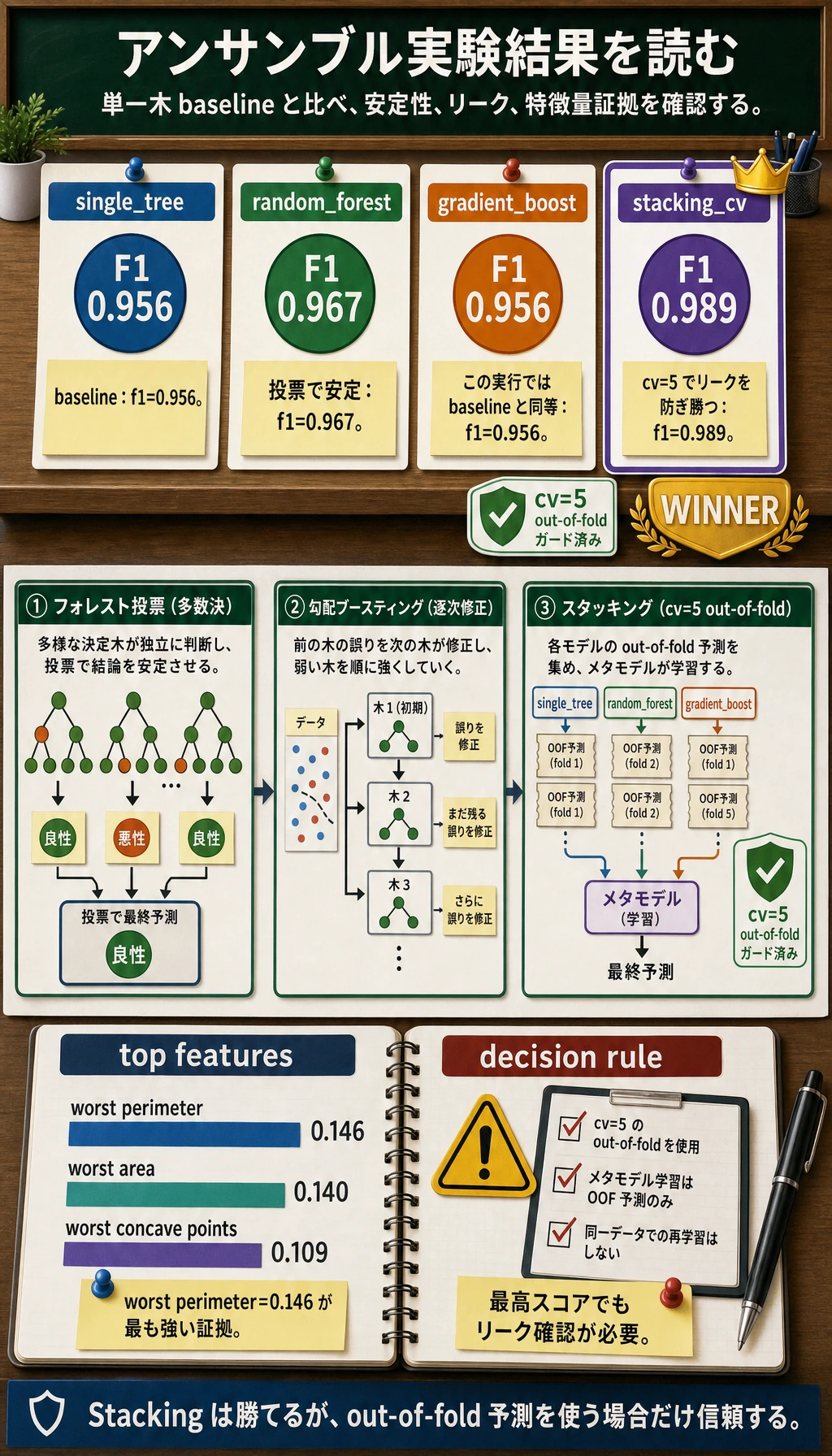
sklearn のバージョンによりスコアが少し変わることがあります。比較表と重要特徴量をプロジェクト証拠として残します。
結果を読む
単一木は baseline です。Random Forest は多くの異なる木を平均するため、たいてい安定します。
Boosting は小さなデータセットで常に勝つわけではありません。木の深さ、learning rate、木の本数、検証性能を制御する必要があります。
Stacking は異なるモデル群を組み合わせるため、この例では勝つことがあります。ただし、交差検証が必須です。メタモデルが基モデルの学習行に対する予測を直接見ると、情報リークになります。
Bagging:Random Forest
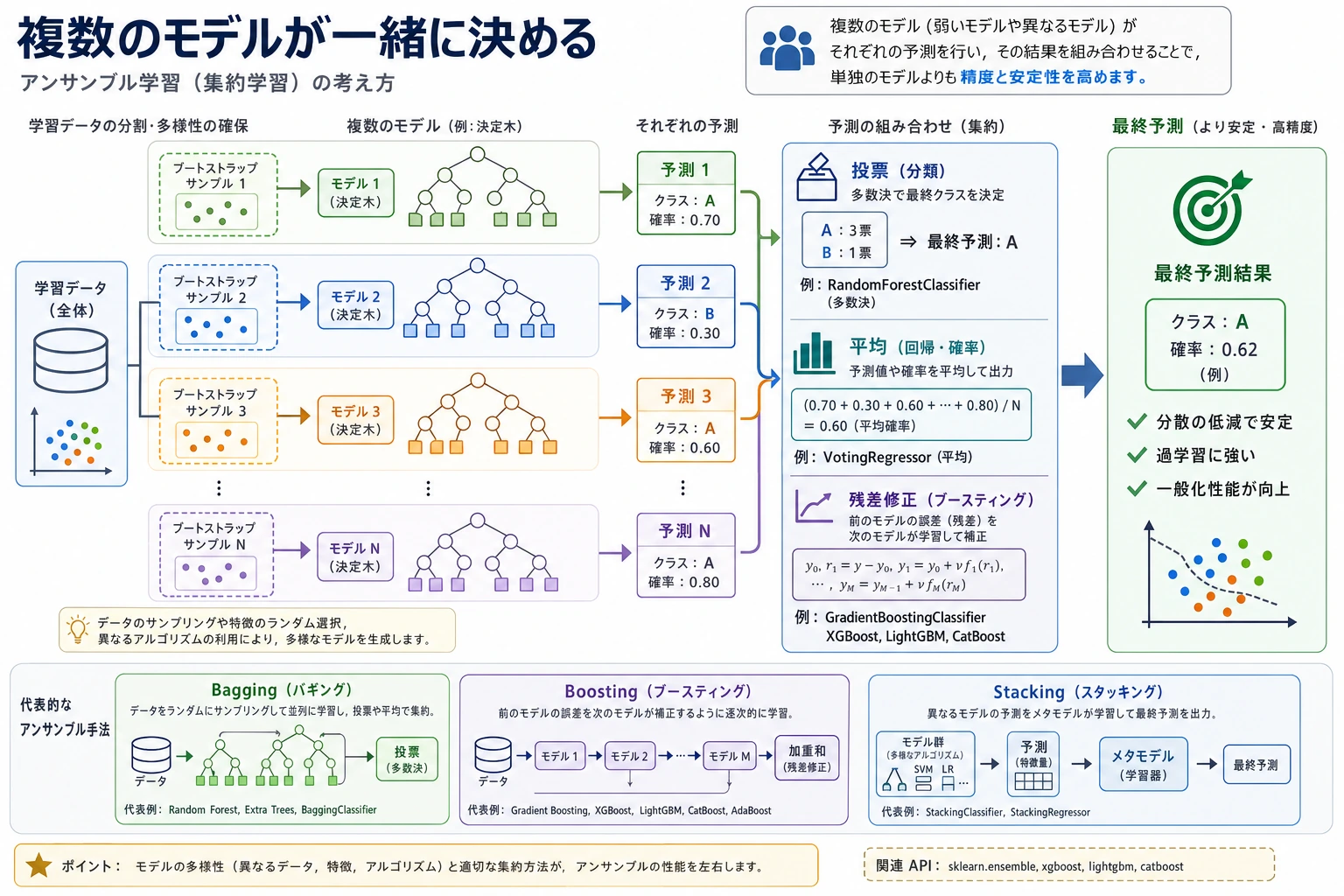
Random Forest はランダム化されたデータ視点で多くの決定木を学習し、その予測を平均または投票します。
最初に見る設定:
| パラメータ | 何を制御するか | 初心者の目安 |
|---|---|---|
n_estimators | 木の数 | 100 から 300 |
max_depth | 木の深さ | 小さく始めて増やす |
min_samples_leaf | 葉に必要な最小サンプル数 | 過学習時に増やす |
random_state | 再現性 | 学習中は必ず設定 |
Boosting:GBDT とツール群
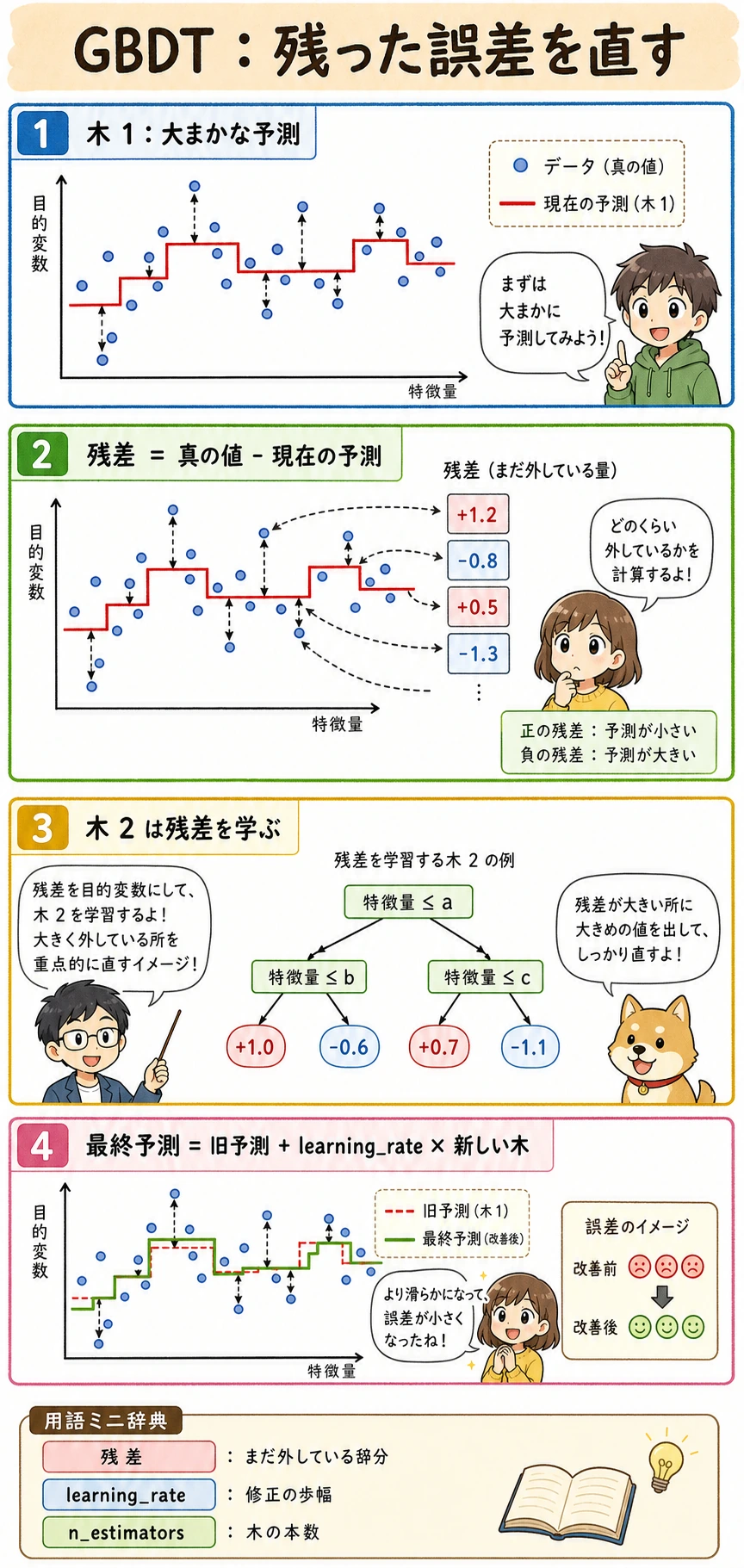
Boosting は順番にモデルを作ります。
最初の小さな木 -> 誤りを見る -> 次の小さな木が誤りに集中 -> 繰り返す
sklearn では、まず GradientBoostingClassifier または HistGradientBoostingClassifier から始めます。実際の表形式プロジェクトでは XGBoost、LightGBM、CatBoost もよく使いますが、sklearn baseline が見える前に外部ライブラリへ飛ばないでください。
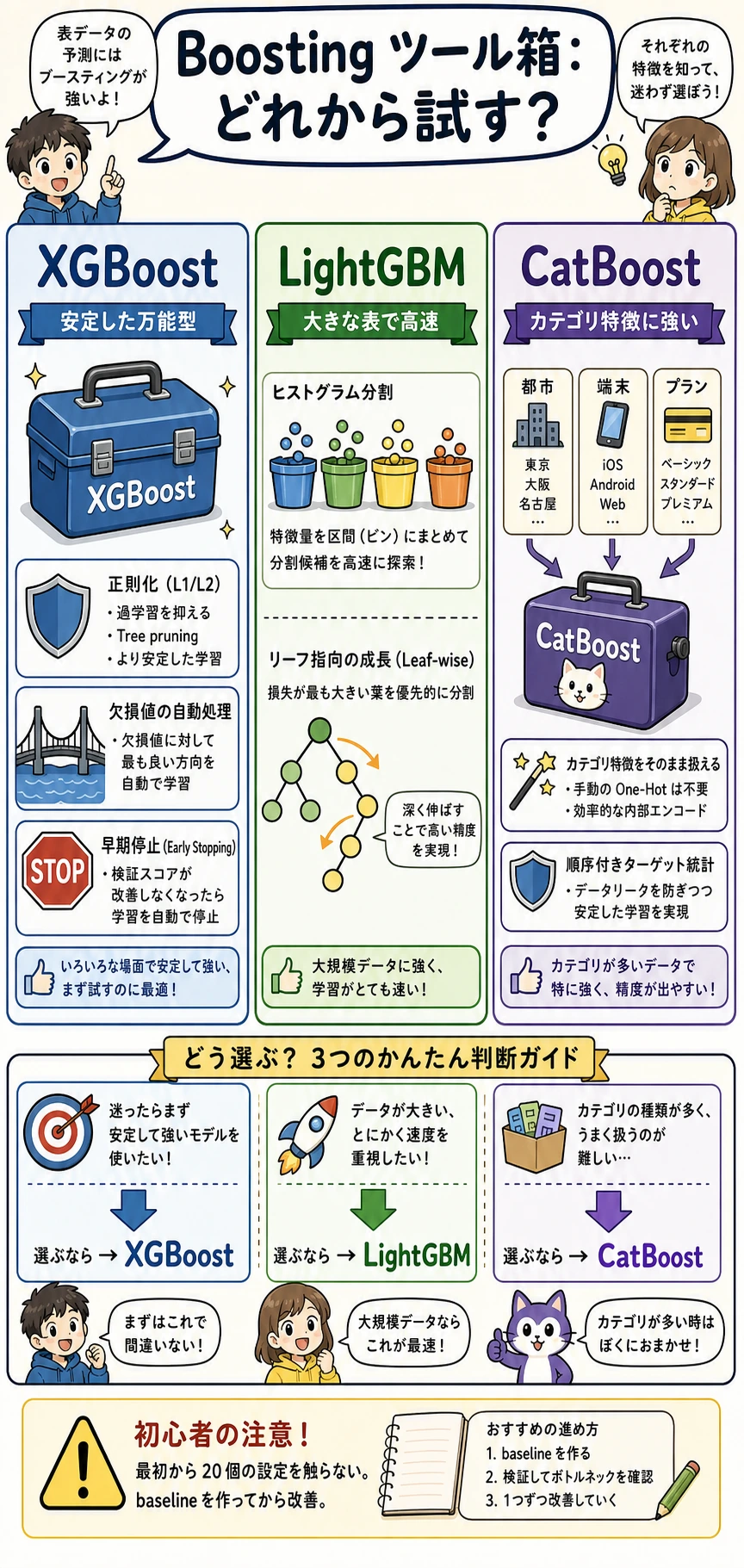
Boosting の最初の調整順:
| 手順 | 変えるもの | 理由 |
|---|---|---|
| 1 | learning_rate と n_estimators | 歩幅と学習ラウンド数を制御 |
| 2 | max_depth / leaf 設定 | 複雑さを制御 |
| 3 | 検証または early stopping | 過学習を止める |
| 4 | 特徴量前処理 | 信号品質を上げる |
Stacking を安全に使う
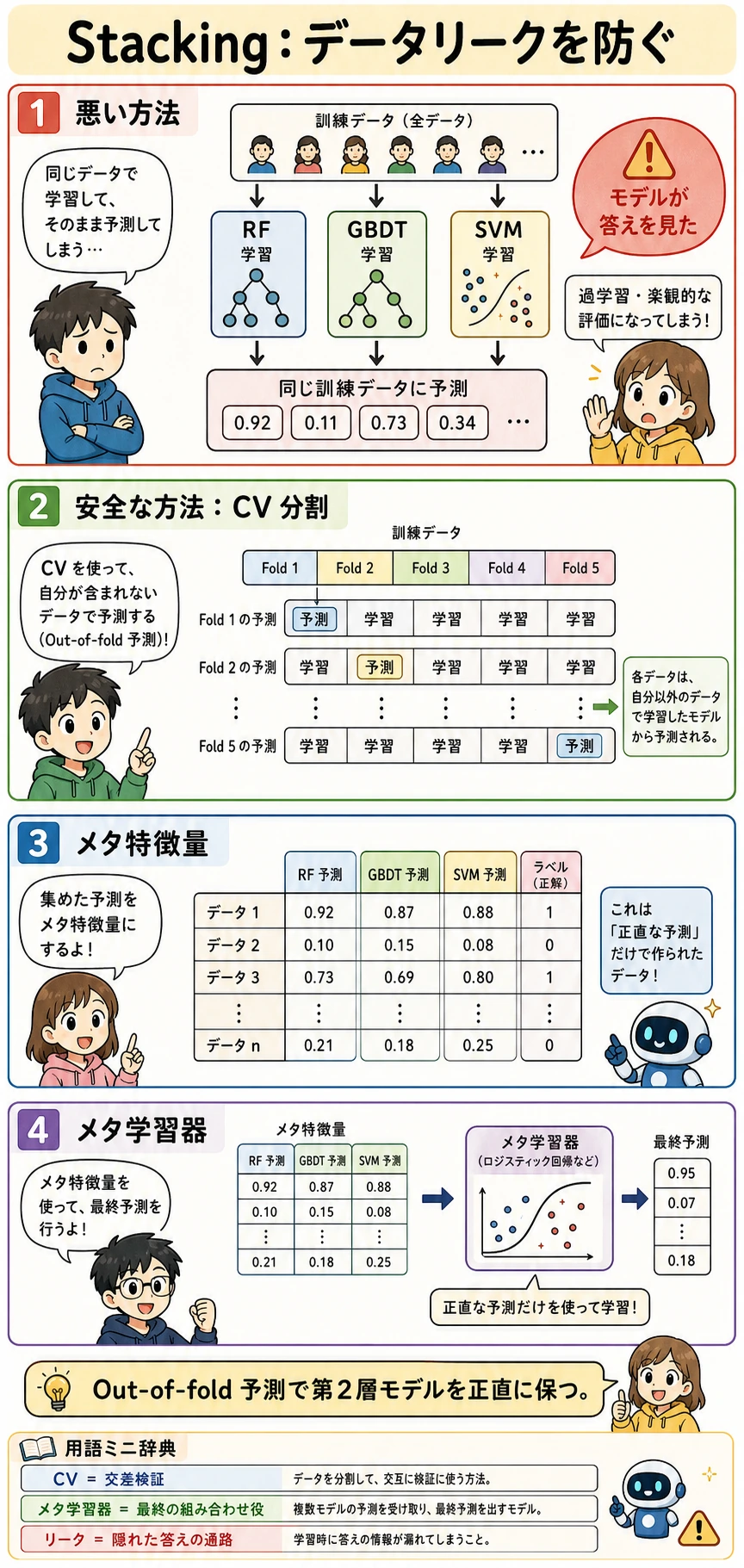
Stacking が信頼できるのは、メタモデルが out-of-fold 予測を見る場合です。
CV fold 内で基モデルを学習 -> out-of-fold 予測を集める -> メタモデルを学習 -> holdout test で評価
手作業で学習行の予測をそのままメタモデルに渡すのではなく、sklearn の StackingClassifier(cv=5) を優先します。
モデルをどう選ぶか
| 状況 | まず使う |
|---|---|
| 強く安定した baseline がほしい | Random Forest |
| 表形式データに非線形が多い | Gradient Boosting / XGBoost / LightGBM |
| カテゴリ特徴量が多い | baseline 後に CatBoost |
| 複数のモデル群が補完し合う | 交差検証つき Stacking |
| 説明しやすさを優先 | 浅い木または Random Forest の特徴量重要度 |
よくある失敗
| 症状 | 最初に確認 | よくある修正 |
|---|---|---|
| アンサンブルが単一木とあまり変わらない | 特徴量が弱い、分割が不安定 | 特徴量追加、交差検証 |
| 学習は良いがテストが悪い | 過学習 | 深さを下げ、leaf を増やし、検証を入れる |
| Boosting が木を増やすほど悪化 | ラウンド数が多すぎる | learning rate を下げる、early stopping |
| Stacking が異常に完璧 | 情報リーク | out-of-fold 予測または StackingClassifier(cv=...) |
| 特徴量重要度を読みすぎる | 特徴量が相関している | permutation importance や ablation で確認 |
練習
- Random Forest の
max_depthを6から3とNoneに変える。 - Gradient Boosting の
learning_rateを0.05から0.2に変える。 - Stacking が交差検証なしだとなぜリークするか説明する。
- モデル比較表を保存し、最初に本番へ出すモデルを一段落で説明する。
通過チェック
次を説明できれば先へ進めます。
- Bagging と Boosting の違い。
- Random Forest が単一木より安定しやすい理由。
- Boosting に検証制御が必要な理由。
- Stacking に交差検証が必須な理由。
- leaderboard 最高スコアが、常に本番最適とは限らない理由。