5.2.3 逻辑回归
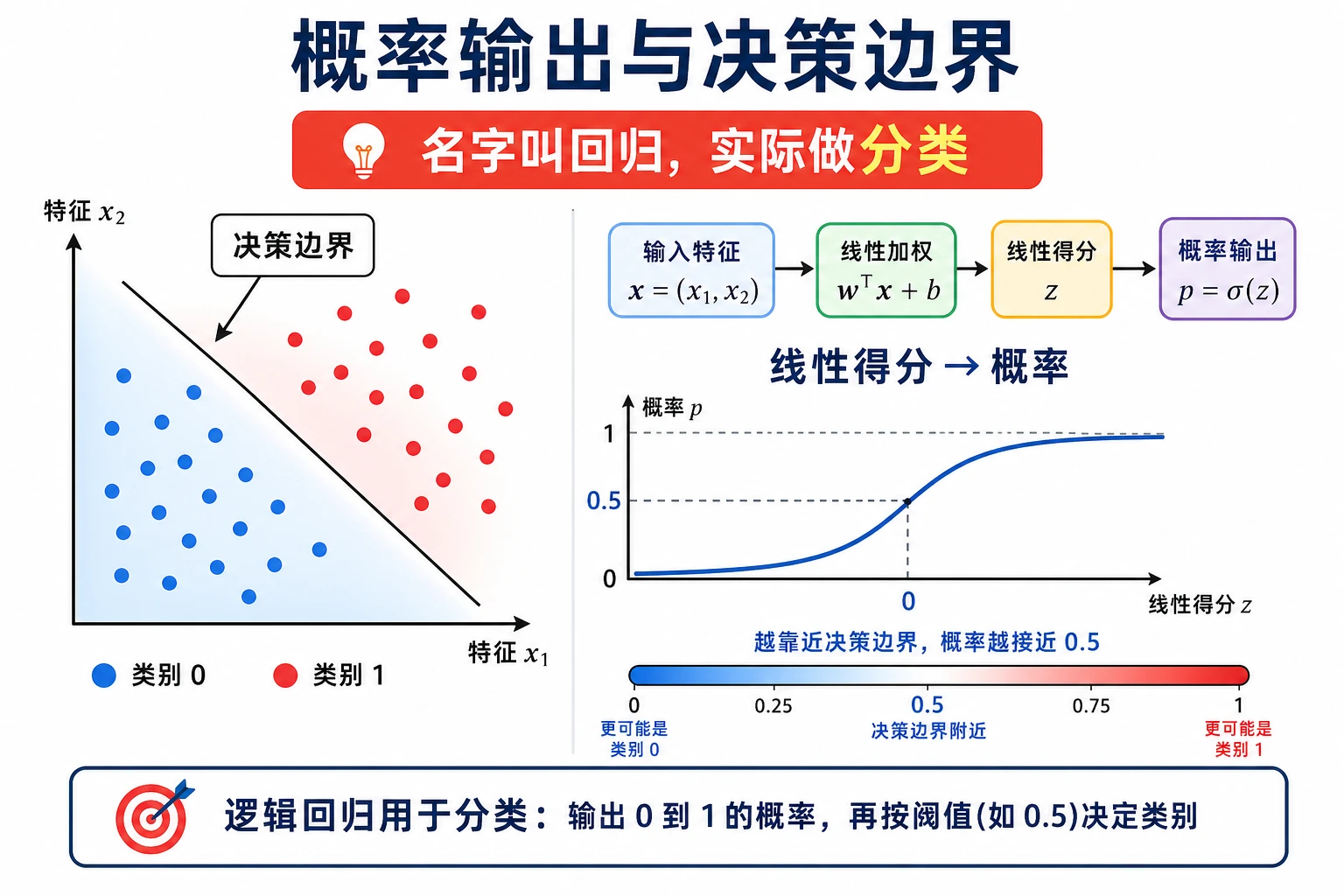
逻辑回归名字里有“回归”,但实际项目里它是一个分类模型。它先学习一个线性分数,再把分数变成概率,最后用阈值做分类决定。
你会做出什么
学完这一节,你会得到一套可以直接运行的分类流程:
- 用
Pipeline、StandardScaler和LogisticRegression训练二分类模型; - 输出 accuracy、precision、recall、F1、误报和漏报;
- 调整分类阈值,而不是永远默认
0.5; - 查看标准化后最重要的特征;
- 用
C比较不同正则化强度; - 把同一套模型写法迁移到多分类数据集。
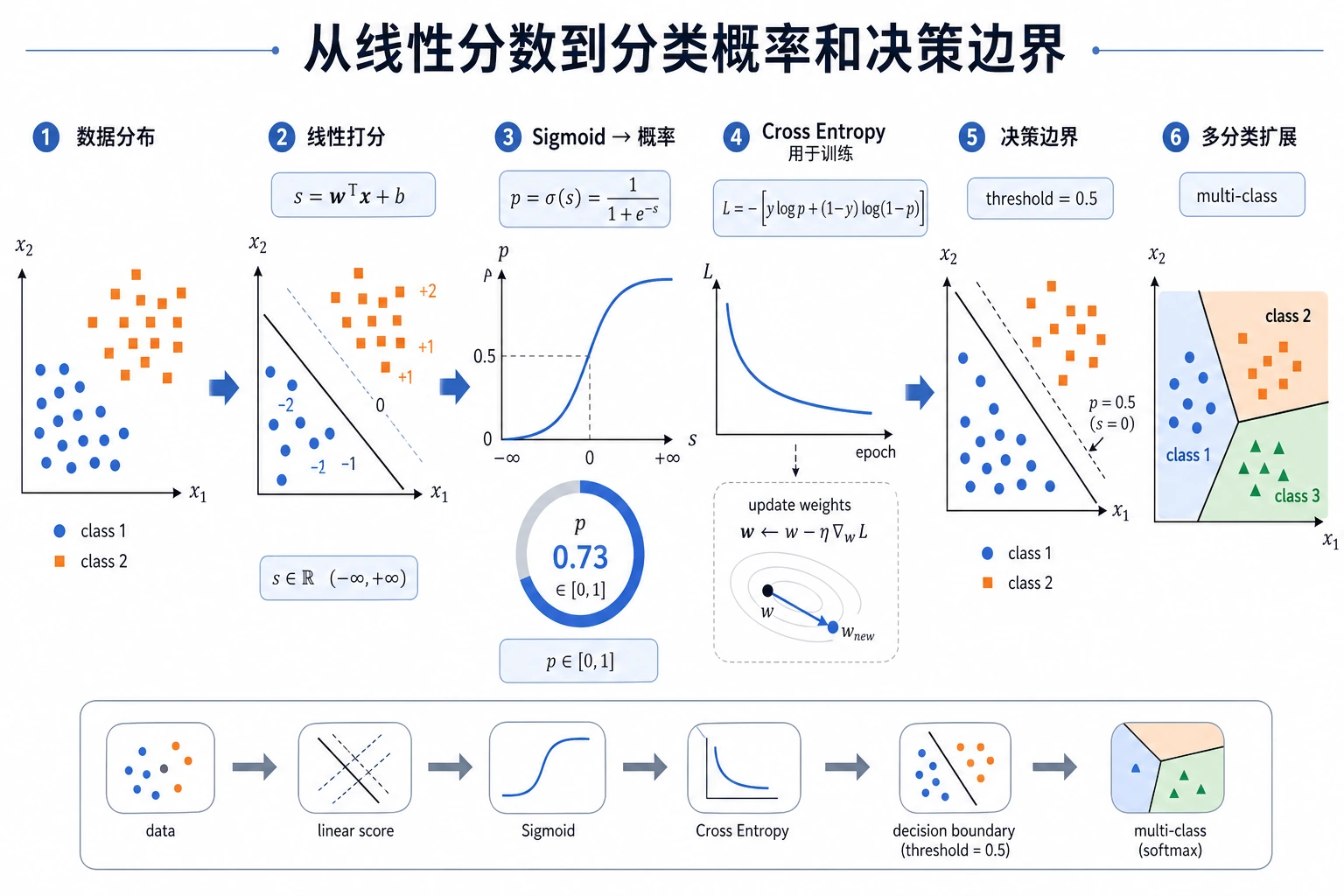
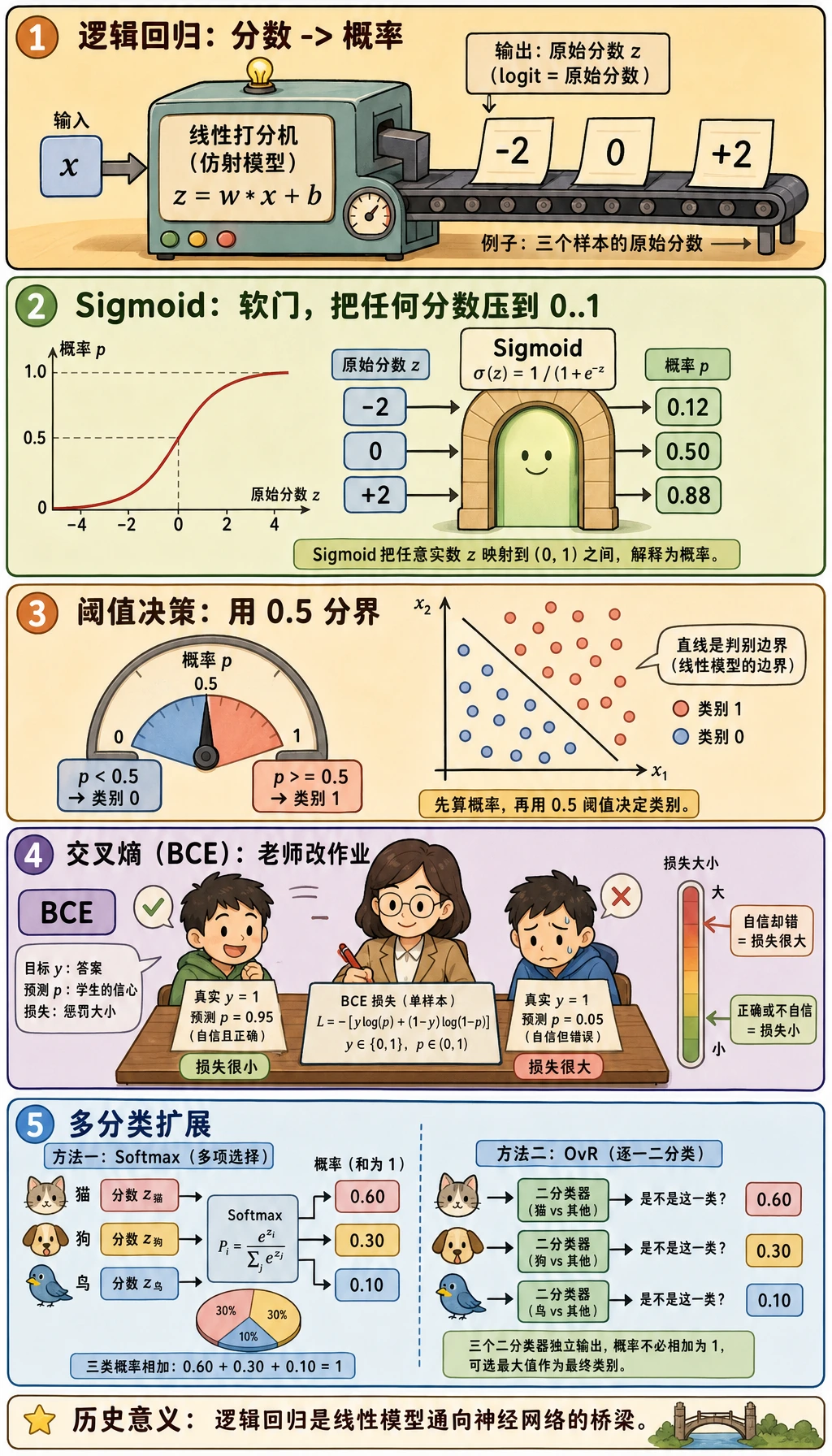
先看下面两张图,再运行代码。看到真实输出以后,后面的概念会容易很多。
环境准备
在干净的虚拟环境中运行:
python -m pip install -U scikit-learn numpy
本节使用当前稳定的 scikit-learn 写法:用 Pipeline 防止预处理泄漏,用 StandardScaler 缩放数值特征,用 LogisticRegression 的默认多分类行为,避免已经不推荐的新旧参数混用。
运行完整实验
新建 logistic_lab.py:
import numpy as np
from sklearn.datasets import load_breast_cancer, load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, f1_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
def make_model(C=1.0):
return Pipeline([
("scale", StandardScaler()),
("clf", LogisticRegression(max_iter=2000, C=C, random_state=42)),
])
# Part 1: binary classification and threshold tuning.
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data,
cancer.target,
test_size=0.25,
random_state=42,
stratify=cancer.target,
)
model = make_model(C=1.0)
model.fit(X_train, y_train)
prob = model.predict_proba(X_test)[:, 1]
print("binary_threshold_lab")
for threshold in [0.3, 0.5, 0.7]:
pred = (prob >= threshold).astype(int)
tn, fp, fn, tp = confusion_matrix(y_test, pred).ravel()
print(
f"threshold={threshold:.1f} "
f"accuracy={accuracy_score(y_test, pred):.3f} "
f"precision={precision_score(y_test, pred):.3f} "
f"recall={recall_score(y_test, pred):.3f} "
f"f1={f1_score(y_test, pred):.3f} "
f"fp={fp} fn={fn}"
)
clf = model.named_steps["clf"]
top = np.abs(clf.coef_[0]).argsort()[-3:][::-1]
print("top_scaled_coefficients")
for idx in top:
print(f"- {cancer.feature_names[idx]}: {clf.coef_[0][idx]:.3f}")
print("regularization_check")
for C in [0.1, 1.0, 10.0]:
candidate = make_model(C=C)
candidate.fit(X_train, y_train)
pred = candidate.predict(X_test)
coef_norm = np.linalg.norm(candidate.named_steps["clf"].coef_)
print(f"C={C:<4} accuracy={accuracy_score(y_test, pred):.3f} coef_norm={coef_norm:.2f}")
# Part 2: multi-class probability output.
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data,
iris.target,
test_size=0.25,
random_state=42,
stratify=iris.target,
)
multi = make_model(C=1.0)
multi.fit(X_train, y_train)
print("multiclass_lab")
print("accuracy=", round(accuracy_score(y_test, multi.predict(X_test)), 3))
for row in multi.predict_proba(X_test[:3]):
pairs = [f"{name}:{value:.2f}" for name, value in zip(iris.target_names, row)]
print(" | ".join(pairs))
运行:
python logistic_lab.py
预期输出:
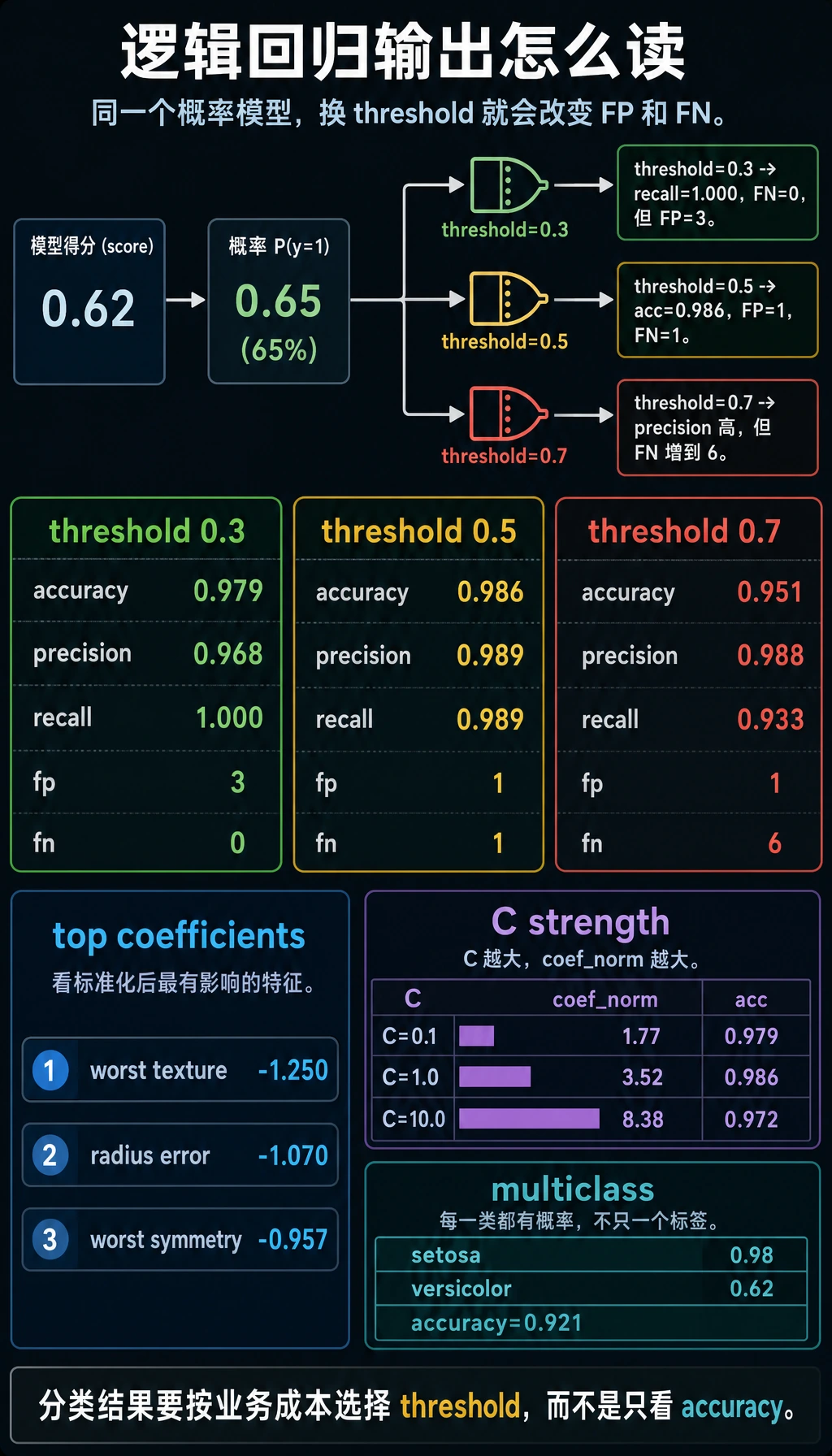
binary_threshold_lab
threshold=0.3 accuracy=0.979 precision=0.968 recall=1.000 f1=0.984 fp=3 fn=0
threshold=0.5 accuracy=0.986 precision=0.989 recall=0.989 f1=0.989 fp=1 fn=1
threshold=0.7 accuracy=0.951 precision=0.988 recall=0.933 f1=0.960 fp=1 fn=6
top_scaled_coefficients
- worst texture: -1.250
- radius error: -1.070
- worst symmetry: -0.957
regularization_check
C=0.1 accuracy=0.979 coef_norm=1.77
C=1.0 accuracy=0.986 coef_norm=3.52
C=10.0 accuracy=0.972 coef_norm=8.38
multiclass_lab
accuracy= 0.921
setosa:0.98 | versicolor:0.02 | virginica:0.00
setosa:0.03 | versicolor:0.62 | virginica:0.35
setosa:0.05 | versicolor:0.88 | virginica:0.07
读懂这条流水线

模型其实在做三件不同的事:
| 步骤 | 代码位置 | 含义 |
|---|---|---|
| 分数 | LogisticRegression 内部的 z = wT x + b | 原始线性分数,还不是概率 |
| 概率 | predict_proba() | 把分数转成 0 到 1 之间的值 |
| 决策 | prob >= threshold | 用业务阈值把概率变成类别 0 或 1 |
新手最容易卡住的地方,是把“分数、概率、类别”混在一起。实际项目里,模型可以不变,但阈值可以根据业务成本调整。
必须掌握的最小理论
Sigmoid 会把任意实数分数压到 (0, 1):
sigmoid(z) = 1 / (1 + exp(-z))
当 z = 0 时,概率就是 0.5。所以二分类逻辑回归的默认决策边界,就是原始分数等于零的那条线或那个超平面。
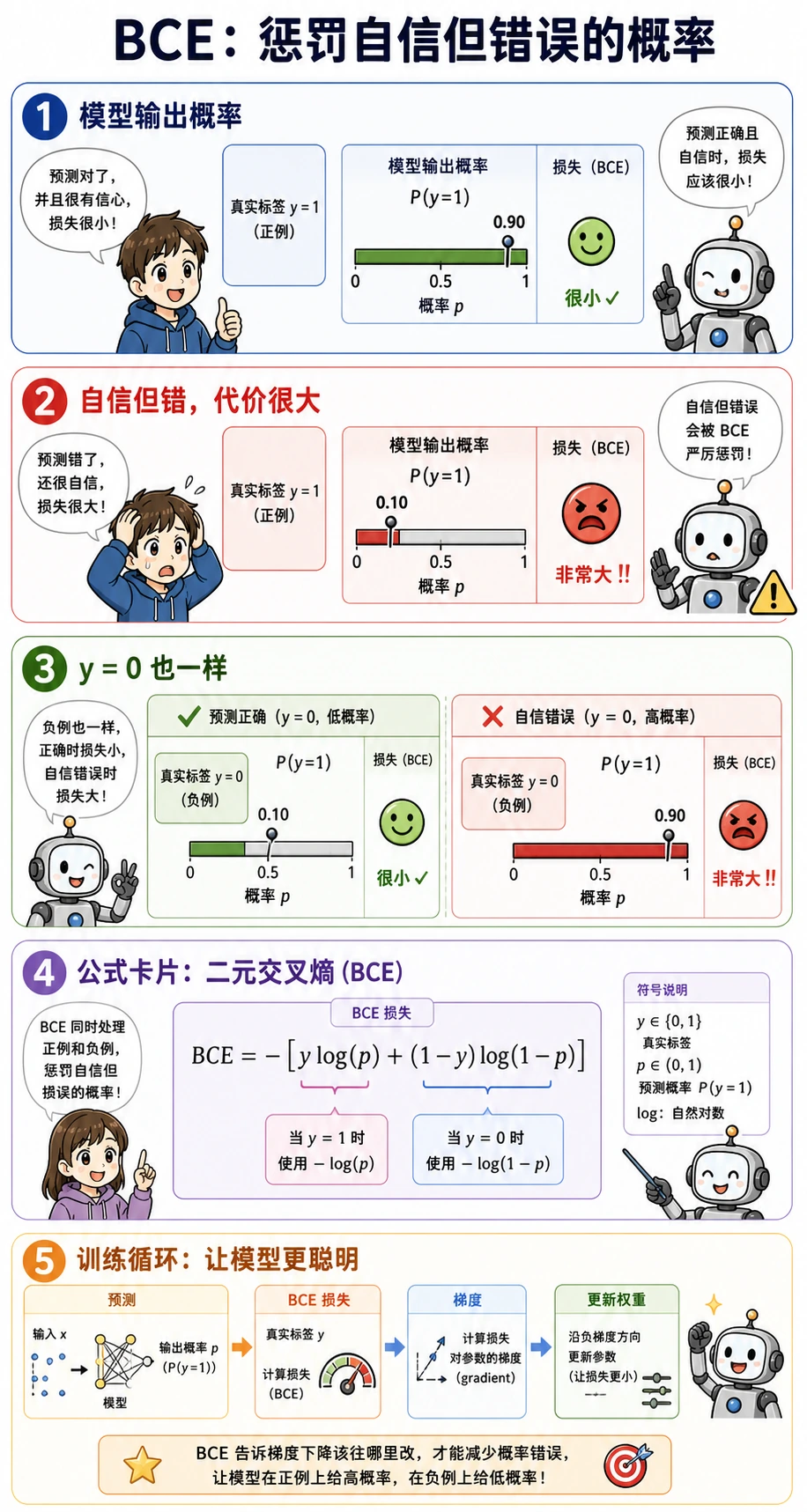
BCE 是 Binary Cross-Entropy,二元交叉熵,常用于二分类概率预测。先记住这个直觉:
- 正确答案是
1时,预测0.99很好,预测0.01很糟; - 正确答案是
0时,预测0.01很好,预测0.99很糟; - 越自信但越错,惩罚越大。
这也是为什么逻辑回归比“强行让线性回归预测 0 和 1”更适合分类。
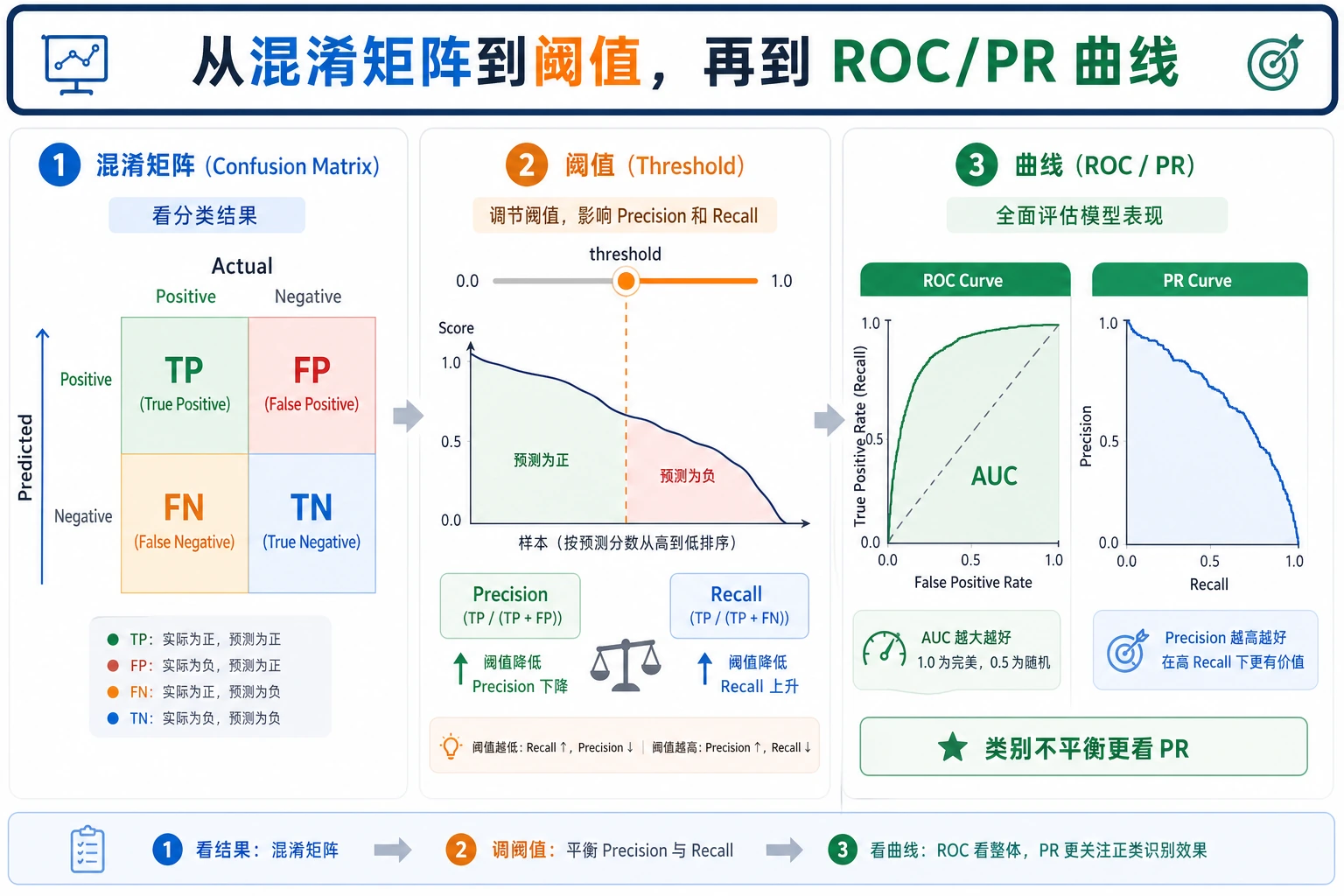
阈值是产品决策
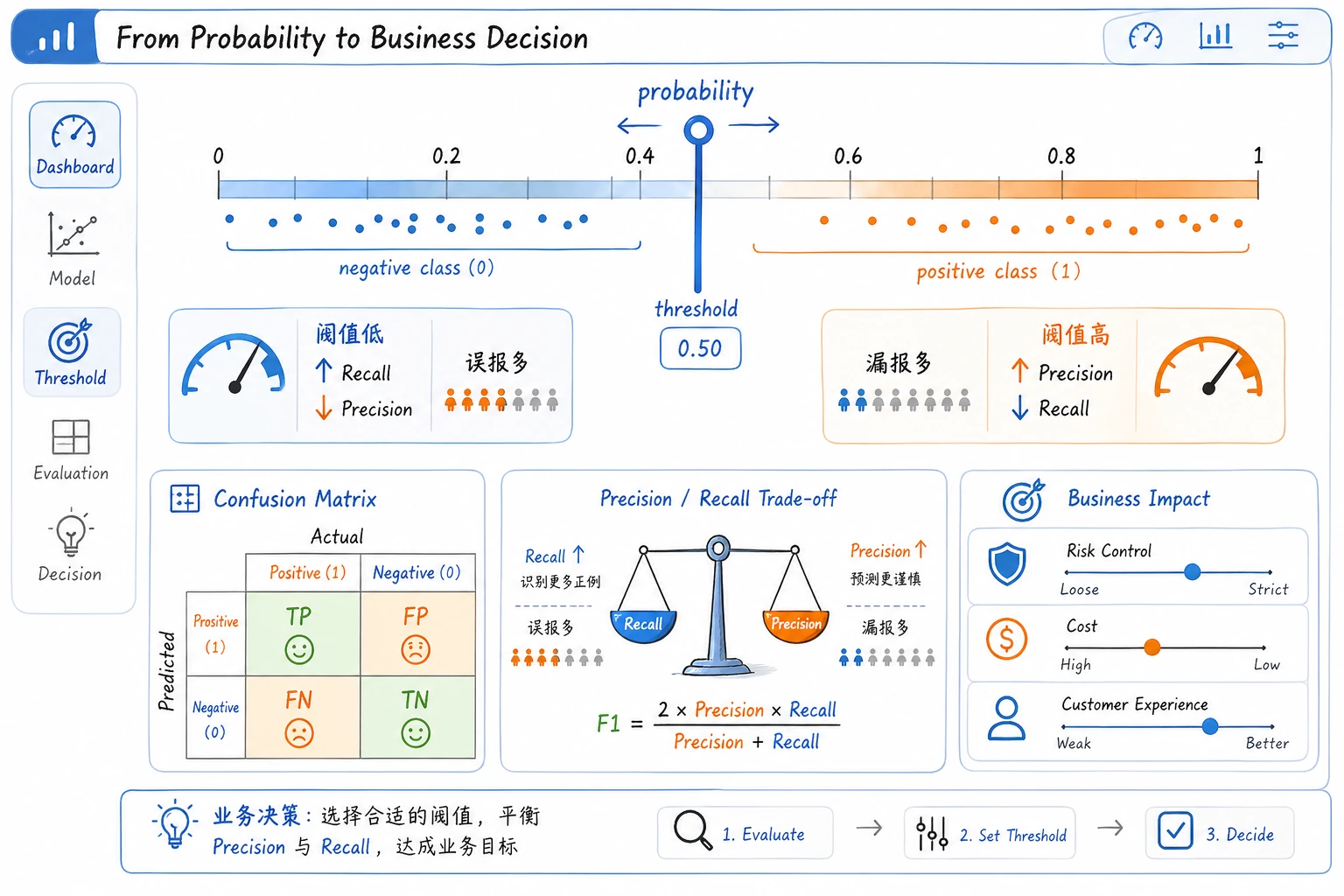
从输出可以看到,阈值一变,错误类型也会变:
| 阈值 | 发生了什么 | 适合什么场景 |
|---|---|---|
0.3 | recall 达到 1.000,但误报变多 | 初筛、告警、先捞出可疑样本 |
0.5 | 这次切分里整体最均衡 | 不知道业务成本时的默认起点 |
0.7 | 误报少一些,但漏报变多 | 人工复核很贵、确认标准很严格 |
给有经验的读者:不要只用 accuracy 选阈值。先弄清楚 fp 和 fn 的成本,再结合 precision-recall 曲线或 ROC 曲线判断。
正则化与 C
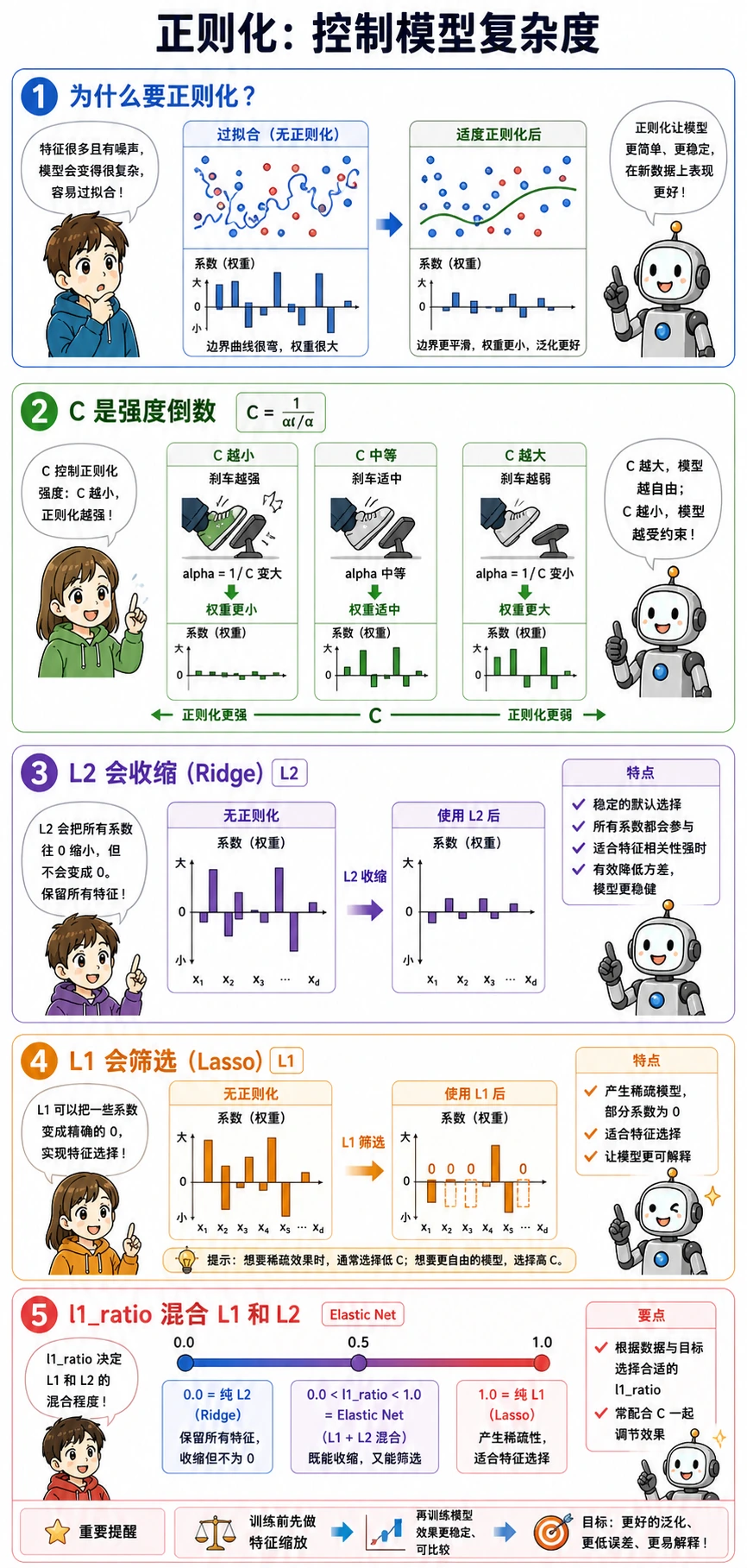
在 sklearn 里,C 是正则化强度的倒数:
C越小,正则化越强;- 正则化越强,系数通常越小;
- 系数特别大,往往说明模型可能在努力贴合噪声。
这次实验输出里能看到这个趋势:
C=0.1 accuracy=0.979 coef_norm=1.77
C=1.0 accuracy=0.986 coef_norm=3.52
C=10.0 accuracy=0.972 coef_norm=8.38
系数范数最大并不代表模型最好。生产环境里的基线模型,更应该追求准确、稳定、容易解释。
多分类

类别超过两个时,逻辑回归仍然可以输出概率。在 Iris 的输出里,每一行概率加起来大约是 1.0:
setosa:0.03 | versicolor:0.62 | virginica:0.35
这表示模型更倾向于 versicolor,但并不是完全确定。这个“不确定性”在人工复核队列、主动学习、人机协作流程里很有用。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| 训练不收敛 | 特征没有缩放,或 max_iter 太小 | 在 Pipeline 中加入 StandardScaler,增大 max_iter |
| accuracy 很高但 recall 很差 | 类别不均衡或阈值不合适 | 打印混淆矩阵、precision、recall、F1 |
| 系数不好比较 | 特征单位不同 | 先缩放数值特征 |
| 测试分数好得离谱 | 在切分训练/测试前就 fit 了预处理 | 把预处理放进 Pipeline |
| 多分类代码出现旧参数警告 | 使用了不再推荐的 multi_class 参数 | 除非需要特定 solver,否则使用 sklearn 默认行为 |
练习
- 把阈值列表改成
[0.2, 0.4, 0.6, 0.8]。哪个阈值漏报最少? - 把
C改成[0.01, 0.1, 1, 10, 100]。accuracy 从什么时候开始不再提升? - 除了绝对值最大的三个系数,也打印最小的三个系数。标准化以后你观察到什么?
- 用自己的 CSV 替换 breast cancer 数据集。保持同样结构:先切分,再 fit pipeline,再打印指标,最后调阈值。
过关检查
你能不看笔记说清楚下面四句话,就算完成本节:
- 逻辑回归是分类器,输出的是概率。
predict_proba()给概率,阈值把概率变成标签。C控制正则化,C越小,正则化越强。- 当误报和漏报成本不一样时,只看 accuracy 不够。