SVM:最大间隔与核方法
SVM 今天不一定是每个项目的首选模型,但它是经典机器学习里非常重要的一站。
它最值得新人记住的一句话是:
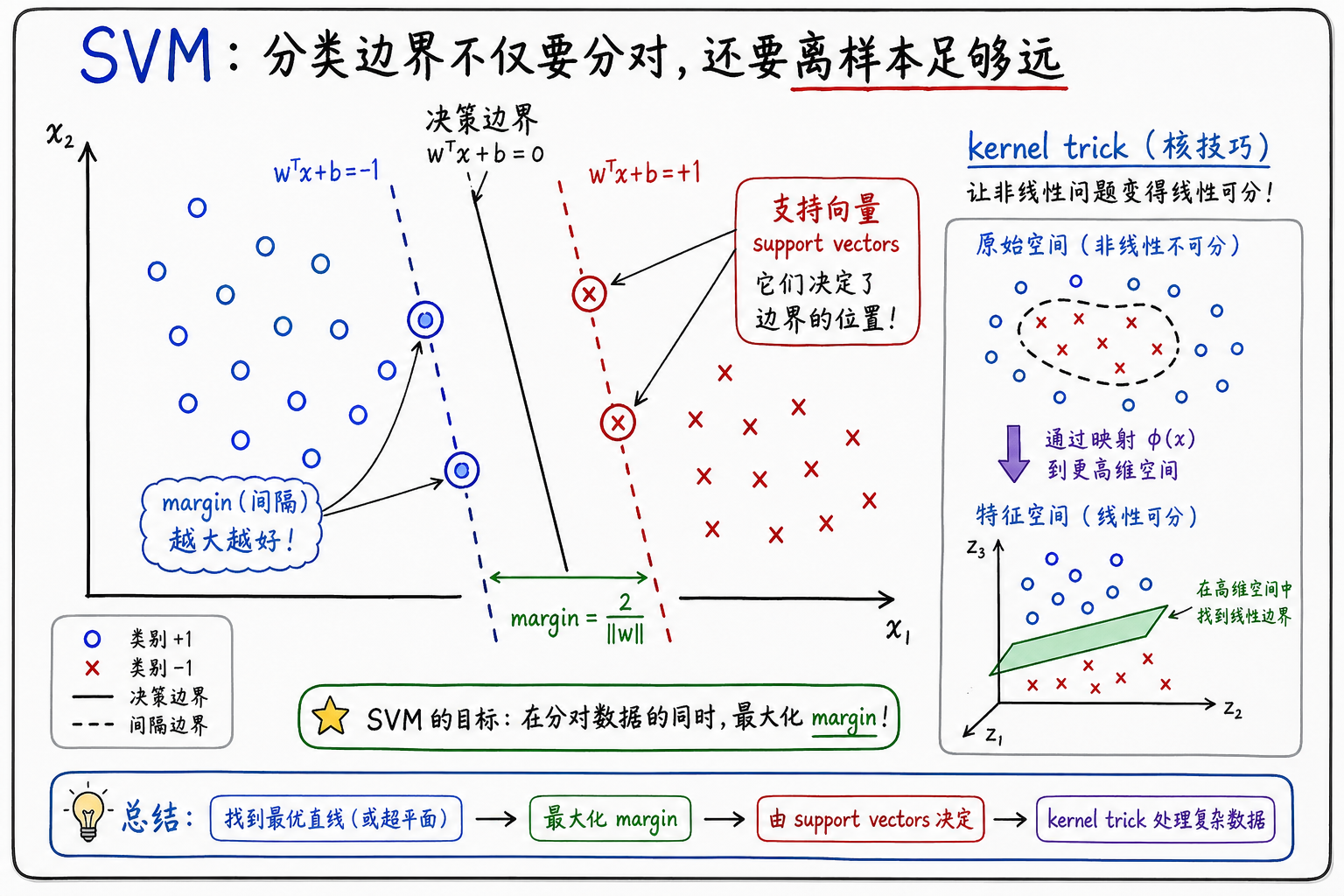
分类不只是要分对,还要让边界离两边样本都尽量远。
一、SVM 为什么会出现?
前面你已经学过逻辑回归。逻辑回归会学习一条分界线,把样本分成两类。
但这里会出现一个问题:
如果有很多条线都能把训练样本分开,哪一条更好?
SVM 的回答非常有意思:
选那条离两边最近样本都最远的线。
这就是最大间隔思想。
二、先用一个生活类比理解最大间隔
想象你要在两个班级的队伍中间画一条安全线:
- 只要能分开两边,当然可以
- 但如果线贴着某个同学画,就很危险
- 稍微有人移动一点,就可能越界
更稳的画法是:
让安全线尽量站在两边之间最宽的位置。
SVM 就是在做类似的事。
| 概念 | 类比 |
|---|---|
| 决策边界 | 两类样本之间的安全线 |
| 间隔 margin | 安全线到两边最近样本的距离 |
| 支持向量 | 离安全线最近、最关键的样本 |
三、支持向量到底是什么?
SVM 这个名字里的“支持向量”,指的是最靠近分界线的那些样本。
它们很关键,因为:
- 离边界很远的点,通常不会改变分界线
- 离边界最近的点,决定了边界能放在哪里
你可以把支持向量理解成“边界的支撑点”。
边界不是被所有样本平均决定的,而是被最关键、最危险的样本撑起来的。
四、核方法:直线分不开时,换一个空间看
SVM 更有历史意义的地方在于核方法。
有些数据在原始平面上分不开,例如同心圆:
原始空间:看起来怎么画直线都分不开
更高维空间:换个角度后可能可以用一个平面分开
核方法的直觉是:
不一定真的把数据搬到高维空间里算,而是用核函数高效计算“高维空间里的相似度”。
这让 SVM 可以处理一些非线性边界。
五、一个最小可运行示例
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
X, y = make_moons(n_samples=300, noise=0.25, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
model = make_pipeline(
StandardScaler(),
SVC(kernel="rbf", C=1.0, gamma="scale")
)
model.fit(X_train, y_train)
print("accuracy:", model.score(X_test, y_test))
这里有两个点特别值得注意:
StandardScaler()很重要,因为 SVM 对特征尺度比较敏感kernel="rbf"表示使用常见的非线性核
六、SVM、逻辑回归和树模型怎么选?
| 模型 | 更像在做什么 | 适合新人怎么理解 |
|---|---|---|
| 逻辑回归 | 学一条概率化的线性边界 | 最基础的分类 baseline |
| SVM | 学一条最大间隔边界 | 分类边界要稳,不要贴样本太近 |
| 决策树 | 按规则一步步切分数据 | 更像人读得懂的规则树 |
| 随机森林 / Boosting | 组合很多树 | 表格数据强 baseline |
SVM 的优势是边界思想非常漂亮,小中型数据上常有不错效果��。
它的限制是大数据训练可能慢,参数和核函数选择也需要经验。
七、把 SVM 放回历史主线
1995 年,Cortes 和 Vapnik 的 Support-Vector Networks 让最大间隔分类器成为经典机器学习的重要节点。
它在历史上重要,不是因为它永远最强,而是因为它把两个问题讲得非常清楚:
- 泛化不是只看训练集分对没有
- 决策边界离样本远一点,模型通常更稳
这也是为什么即使今天很多表格任务会优先尝试 XGBoost、LightGBM 或随机森林,SVM 仍然值得学。
八、学完这一节应该形成的直觉
你不需要第一遍就推完整的 SVM 优化公式。
更重要的是先形成三层直觉:
- SVM 追求最大间隔,不只是训练集分对
- 支持向量是决定边界的关键样本
- 核方法让线性模型获得处理非线性的能力
如果你能解释“为什么 SVM 经常需要特征缩放”,说明你已经把它从算法名真正理解到工程使用了。