学前导读:无监督学习这一章到底在学什么
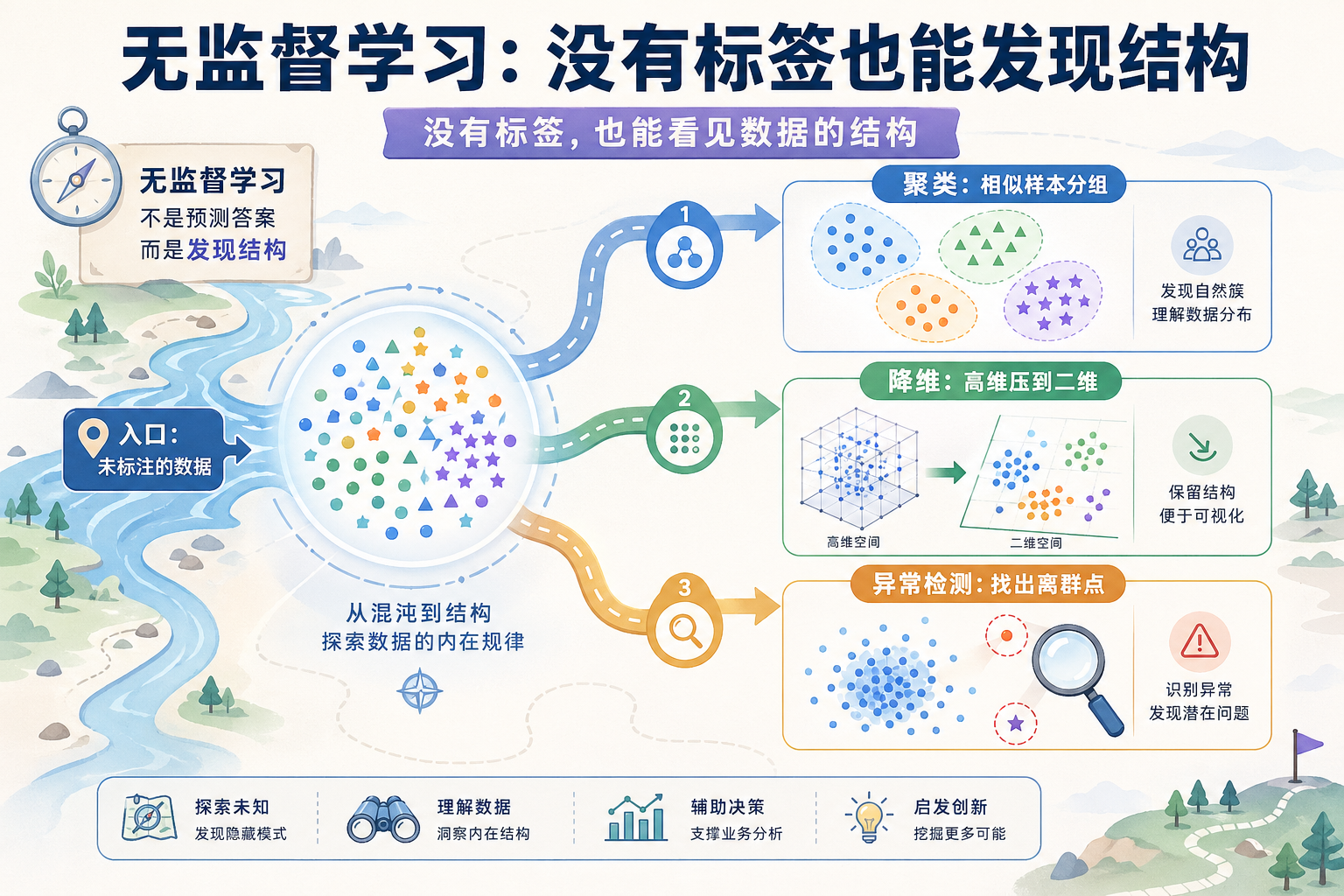
无监督学习和监督学习最大的区别是:没有标签。
这意味着你不能直接问模型“答对了吗”,而是要先问:
- 数据里有没有自然分组
- 数据能不能压缩到更少维度
- 数据里有没有明显异常点
先说一个很重要的学习预期
这一章最容易让新人发虚的地方,不是算法本身,而是:
- 没有标签
- 没有标准答案
- 看起来“好像都能讲”,又不知道怎样才算合理
更适合第一遍先建立的认知是:
无监督学习不是在直接判断对错,而是在帮助你发现数据里可能存在的结构。
所以这一章更像“探索和假设生成”,而不是前��面监督学习那种“直接学会怎么判”。
这一章三节是怎么串起来的
- 聚类:在没有标签时,先看数据能不能自动分群
- 降维:再看能不能把高维数据压缩得更容易看、更容易算
- 异常检测:最后看怎样找出少数“不正常”的点
如果你是第一次学无监督学习,最稳的顺序
更适合新人的顺序通常是:
-
先看 3.2 聚类算法
先建立“没有标签时,数据也可能有结构”这件事。 -
再看 3.3 降维算法
先分清“为了建模预处理”和“为了可视化探索”。 -
最后看 3.4 异常检测
这时你会更容易接受:不是所有任务都在分组,有些任务是在找“不属于大多数”的点。
这样学的好处是:
- 先从最容易理解的“分群”进入
- 再去理解“压缩表示”
- 最后再进入“找少数异常”这种更依赖阈值和业务判断的任务
这一章最容易学乱的地方
- 把无监督结果误会成唯一真相
- 只盯着图好不好看,不问结果有没有业务意义
- 聚类、降维、异常检测都学了,但不知道它们各自解决什么问题
所以这一章最值得先带走的,不是更多模型名字,而是这三个问题:
- 我现在是在找群体,还是在压缩表示,还是在找异常?
- 我手上的结果能不能被业务解释?
- 如果没有标签,我要用什么证据来判断这个结果有没有价值?
新人这一章最该带走什么
- 知道没有标签时,问题该怎样重新表述
- 知道 K-Means、PCA、异常检测分别解决什么问题
- 知道无监督结果通常更依赖解释和业务理解,而不只是一个分数
新人和进阶学习者怎么读
新人第一次学这一章时,先抓住主线和最小可运行例子。你不需要一�次理解所有细节,只要能说清楚这一章解决什么问题、输入输出是什么、最小项目怎么跑起来,就可以继续往后走。
有经验的学习者可以把这一章当成查漏补缺和工程化练习:关注边界条件、失败案例、评估方式、代码可复现性,以及它和前后阶段的连接。读完后最好能把本章内容沉淀到自己的作品 README 或实验记录里。
学习时间与难度建议
| 学习方式 | 建议投入 | 目标 |
|---|---|---|
| 快速浏览 | 20~30 分钟 | 看懂本章解决什么问题,知道后面会用到哪里 |
| 最小通关 | 1~2 小时 | 跑通一个最小例子,完成本章小项目出口 |
| 深入练习 | 半天~1 天 | 补充错误分析、对比实验或项目 README 记录 |
本章自测问题
| 自测问题 | 通过标准 |
|---|---|
| 这一章解决什么问题? | 能用一句话说明它在整门课里的位置 |
| 最小输入输出是什么? | 能说清楚例子需要什么输入,会产生什么结果 |
| 常见失败点在哪里? | 能列出至少一个报错、效果差或理解偏差的原因 |
| 学完后能沉淀什么? | 能把本章产出写进项目 README、实验记录或作品集 |
本章小项目出口
学完这一章后,建议完成一个最小练习:选择一个本章最核心的概念或工具,做出一个可以运行、可以截图、可以写进 README 的小成果。它不需要复杂,但要能说明输入是什么、处理过程是什么、输出结果是什么。
过关标准
这一章结束时,你应该能用自己的话说明本章解决什么问题、它和前后学习站有什么关系,并能完成本章小项目出口的最小版本。
如果你还能记录一次常见错误、一次调试过程或一次结果改进,就说明你已经不只是“看过内容”,而是在把这一章变成自己的项目经验。