降维算法
真实数据往往有几十甚至上千个特征。降维能减少特征数量,同时保留重要信息——既能加速训练,又能帮助可视化。本节在第 4 站 PCA 基础上深入实战应用。
学习目标
- 深入理解 PCA 的原理与实战应用(与第 4 站衔接)
- 掌握方差解释比分析
- 了解 t-SNE 可视化原理与使用
- 了解 UMAP 降维方法
先说一个很重要的学习预期
这一节很容易让新人一开始就被工具名带偏:
- PCA
- t-SNE
- UMAP
但更适合第一遍先学会的不是背工具差异,而是先分清:
你是在为了建模预处理做降维,还是为了可视化探索做降维。
只要这个目的先分清,后面的方法选择就会顺很多。
先建立一张地图
降维这节很容易被学成“会几个工具名”,但真正重要的是先分清目的。
因为你做降维,可能是在解决完全不同的问题:
- 想压缩特征,加速训练
- 想降低噪声和相关性
- 想把高维数据画出来看看结构
更稳的学习顺序是:
先把“为了建模”和“为了可视化”分开,是这节最重要的第一步。
一、为什么需要降维?
1.1 高维数据的问题
| 问题 | 说明 |
|---|---|
| 维度灾难 | 特征越多,数据越稀疏,模型越难学习 |
| 计算成本 | 特征多 → 训练慢、内存大 |
| 多重共线性 | 很多特征高度相关,是冗余的 |
| 可视化 | 超过 3 维的数据无法直接画图 |
1.2 降维的两种思路
| 思路 | 方法 | 说明 |
|---|---|---|
| 特征选择 | 挑选重要特征 | 保留原始特征的子集 |
| 特征提取 | 生成新特征 | 把原始特征变换成更少的新特征(PCA、t-SNE) |
1.3 第一次学降维,最容易混的点
很多新人会把“降维”和“删特征”混在一起。
其实它们不是一回事:
- 特征选择:保留原始列里的某几列
- 降维:把原始列重新组合成更少的新轴
所以 PCA 之后得到的主成分,�已经不再是原始那几个字段本身,而是它们的线性组合。
1.3.1 一个更适合新人的类比
你可以先把降维想成:
- 把一大包零散信息重新压缩成更少的几条主线
这不是简单地把一些字段删掉,
而更像是把很多原始特征重新拧成几根“信息更浓缩的新轴”。
所以降维最值得先记住的,不是算法名字,而是:
- 它在做信息压缩和表示重组
二、PCA 实战
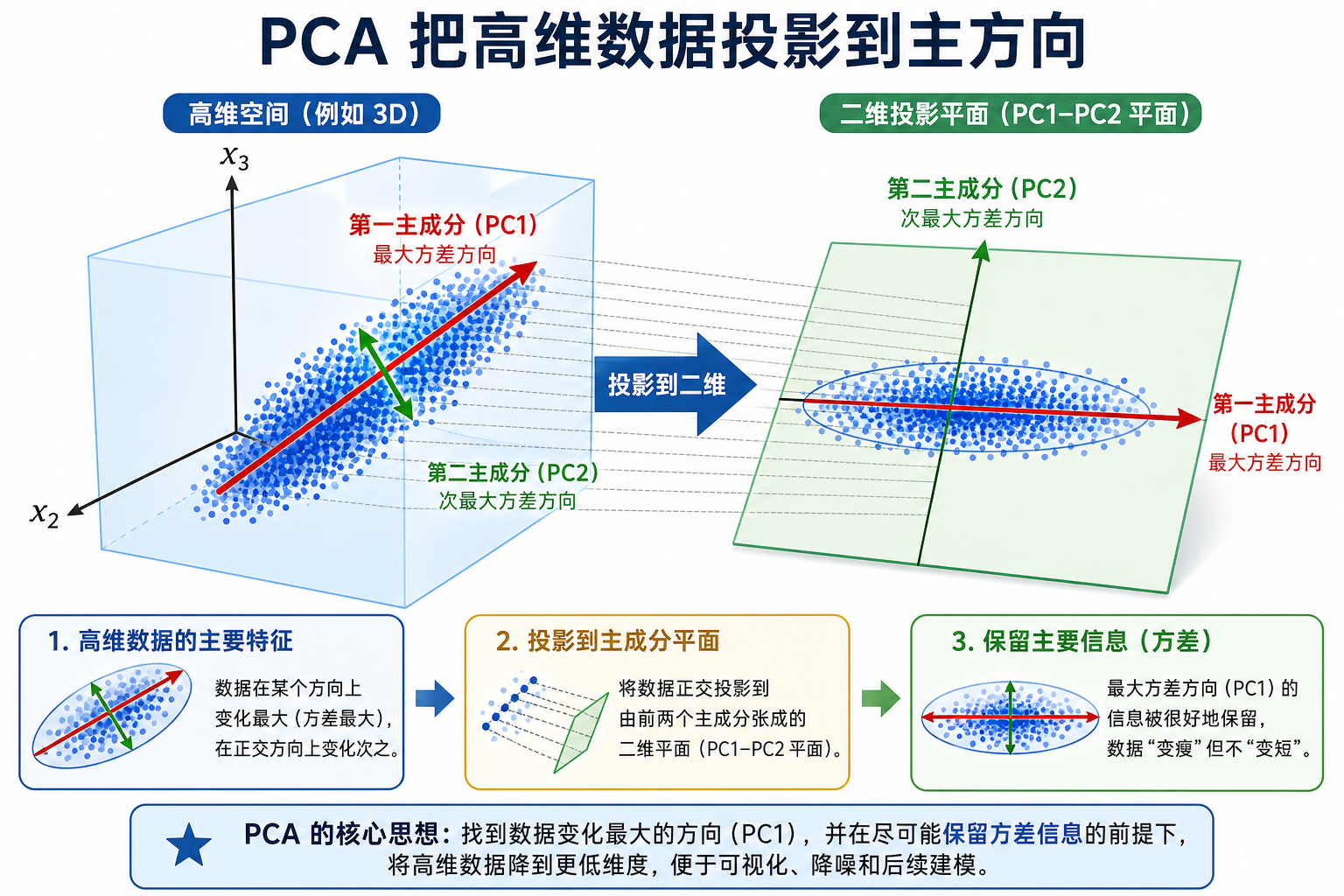
2.1 回顾原理
在第 4 站 1.3 节"特征值与特征向量"中,你已经学过 PCA 的数学原理:
- 计算协方差矩阵
- 求特征值和特征向量
- 选最大特征值对应的方向作为主成分
本节重点是实战应用——如何在真实数据上使用 PCA。
PCA 核心思想:找到数据方差最大的方向,投影过去。
2.2 手写数字降维
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
# 加载手写数字数据
digits = load_digits()
X, y = digits.data, digits.target
print(f"原始数据: {X.shape[0]} 样本, {X.shape[1]} 特征")
# 先看几个样本
fig, axes = plt.subplots(2, 10, figsize=(15, 3))
for i, ax in enumerate(axes.ravel()):
ax.imshow(digits.images[i], cmap='gray')
ax.set_title(str(y[i]), fontsize=9)
ax.axis('off')
plt.suptitle('手写数字样本(8×8 = 64 个特征)')
plt.tight_layout()
plt.show()
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA 降到 2 维
pca_2d = PCA(n_components=2)
X_2d = pca_2d.fit_transform(X_scaled)
print(f"降维后: {X_2d.shape}")
print(f"保留方差比: {pca_2d.explained_variance_ratio_.sum():.1%}")
# 可视化
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y, cmap='tab10', s=10, alpha=0.6)
plt.colorbar(scatter, label='数字')
plt.xlabel(f'PC1(方差占比 {pca_2d.explained_variance_ratio_[0]:.1%})')
plt.ylabel(f'PC2(方差占比 {pca_2d.explained_variance_ratio_[1]:.1%})')
plt.title('PCA 降维到 2D(手写数字)')
plt.grid(True, alpha=0.3)
plt.show()
2.3 方差解释比分析
关键问题:保留多少个主成分才够?
# 用全部主成分
pca_full = PCA()
pca_full.fit(X_scaled)
# 方差解释比
explained = pca_full.explained_variance_ratio_
cumulative = np.cumsum(explained)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 每个主成分的方差占比
axes[0].bar(range(1, len(explained)+1), explained, color='steelblue', alpha=0.7)
axes[0].set_xlabel('主成分编号')
axes[0].set_ylabel('方差解释比')
axes[0].set_title('各主成分的方差占比')
axes[0].set_xlim(0, 30)
# 累积方差
axes[1].plot(range(1, len(cumulative)+1), cumulative, 'bo-', markersize=3)
axes[1].axhline(y=0.9, color='r', linestyle='--', label='90% 阈值')
axes[1].axhline(y=0.95, color='orange', linestyle='--', label='95% 阈值')
# 标注达到 90% 的点
n_90 = np.argmax(cumulative >= 0.9) + 1
n_95 = np.argmax(cumulative >= 0.95) + 1
axes[1].axvline(x=n_90, color='r', linestyle=':', alpha=0.5)
axes[1].axvline(x=n_95, color='orange', linestyle=':', alpha=0.5)
axes[1].set_xlabel('主成分数量')
axes[1].set_ylabel('累积方差解释比')
axes[1].set_title('累积方差解释比(Scree Plot)')
axes[1].legend()
for ax in axes:
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"保留 90% 方差需要 {n_90} 个主成分(原始 64 个)")
print(f"保留 95% 方差需要 {n_95} 个主成分(原始 64 个)")
2.3.1 保留 90% 还是 95%,怎么判断更稳?
这没有一个永远固定的答案,但新人第一次做项目时可以先这样:
- 如果你更在意训练速度和压缩率,先试 90%
- 如果你更担心信息丢失,先试 95%
- 最后一定用下游模型性能来验证,而不是只看方差解释比
因为“保留了多少方差”不等于“下游任务一定最好”。
2.4 PCA 对模型性能的影响
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
import time
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 对比不同主成分数量
n_components_list = [2, 5, 10, 20, 30, 64]
results = []
for n in n_components_list:
pipe = make_pipeline(
StandardScaler(),
PCA(n_components=n) if n < 64 else PCA(),
LogisticRegression(max_iter=5000, random_state=42)
)
start = time.time()
pipe.fit(X_train, y_train)
train_time = time.time() - start
score = pipe.score(X_test, y_test)
results.append({'n': n, 'score': score, 'time': train_time})
print(f"PC={n:3d} | 准确率: {score:.1%} | 训练时间: {train_time:.3f}s")
# 可视化
fig, ax1 = plt.subplots(figsize=(8, 5))
ax2 = ax1.twinx()
ns = [r['n'] for r in results]
scores = [r['score'] for r in results]
times = [r['time'] for r in results]
ax1.plot(ns, scores, 'bo-', label='准确率')
ax2.plot(ns, times, 'rs-', label='训练时间')
ax1.set_xlabel('主成分数量')
ax1.set_ylabel('准确率', color='blue')
ax2.set_ylabel('训练时间 (s)', color='red')
ax1.set_title('PCA 降维对模型性能与速度的影响')
ax1.legend(loc='lower right')
ax2.legend(loc='center right')
ax1.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
2.4.1 PCA 真正的作用,不只是压缩维度
PCA 在项目里常见的价值有三种:
- 去掉冗余相关信息
- 降低噪声,让模型更稳
- 让后续算法在更紧凑的特征空间里训练
所以你做完 PCA 后,不要只问“维度少了多少”,还要问:
- 模型有没有更快
- 泛化有没有更稳
- 是否更不容易过拟合
三、t-SNE 可视化
3.1 PCA 的局限
PCA 是线性降维——它只能找到线性方向。对于复杂的高维数据,不同类别可能在 PCA 2D 图上重叠。
3.2 t-SNE 原理
t-SNE(t-distributed Stochastic Neighbor Embedding)是专门为可视化设计的非线性降维方法。
核心思想:
- 在高维空间中计算点对之间的"相似度"
- 在低维空间中也计算"相似度"
- 调整低维坐标,使两个空间的相似度分布尽可能一致
| 特点 | 说明 |
|---|---|
| 非线性 | 可以展示复杂的数据结构 |
| 专为可视化 | 通常降到 2D 或 3D |
| 保持局部结构 | 相近的点在低维空间也相近 |
| 随机性 | 每次运行结果可能不同 |
3.3 t-SNE 实战
from sklearn.manifold import TSNE
# t-SNE 降维
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
X_tsne = tsne.fit_transform(X_scaled)
# PCA vs t-SNE 对比
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
axes[0].scatter(X_2d[:, 0], X_2d[:, 1], c=y, cmap='tab10', s=10, alpha=0.6)
axes[0].set_title('PCA 降维到 2D')
axes[0].set_xlabel('PC1')
axes[0].set_ylabel('PC2')
axes[1].scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='tab10', s=10, alpha=0.6)
axes[1].set_title('t-SNE 降维到 2D')
axes[1].set_xlabel('t-SNE 1')
axes[1].set_ylabel('t-SNE 2')
for ax in axes:
ax.grid(True, alpha=0.3)
plt.suptitle('PCA vs t-SNE(手写数字数据)', fontsize=13)
plt.tight_layout()
plt.show()
3.4 perplexity 参数
perplexity 控制 t-SNE 关注的"邻居数量",影响可视化效果:
fig, axes = plt.subplots(1, 4, figsize=(20, 4))
perplexities = [5, 15, 30, 50]
for ax, perp in zip(axes, perplexities):
tsne = TSNE(n_components=2, perplexity=perp, random_state=42)
X_t = tsne.fit_transform(X_scaled)
ax.scatter(X_t[:, 0], X_t[:, 1], c=y, cmap='tab10', s=8, alpha=0.6)
ax.set_title(f'perplexity = {perp}')
ax.grid(True, alpha=0.3)
plt.suptitle('t-SNE perplexity 参数的影响', fontsize=13)
plt.tight_layout()
plt.show()
- 只用于可视化,不要用 t-SNE 做特征提取后再训练模型
- 速度慢,大数据集先用 PCA 降到 50 维再跑 t-SNE
- 距离无意义,不同簇之间的距离不能比较大小
- 每次运行结果不同(设
random_state可固定)
3.5 t-SNE 最容易被误读的地方
t-SNE 图看起来很漂亮,但最容易让新人误以为:
- 簇和簇之间离得更远,就代表原始空间里也更远
- 图上分得越开,模型就一定越好
这两件事都不一定成立。
t-SNE 最该看的,是:
- 局部邻近关系有没有保住
- 同类样本是否更容易聚成团
而不是把整张图当成严格几何地图来解释。
四、UMAP 降维
4.1 UMAP 简介
UMAP(Uniform Manifold Approximation and Projection)是比 t-SNE 更快、更能保持全局结构的降维方法。
| t-SNE | UMAP | |
|---|---|---|
| 速度 | 慢 | 快得多 |
| 全局结构 | 不保持 | 较好保持 |
| 可用于特征提取 | 不推荐 | 可以 |
| 参数 | perplexity | n_neighbors, min_dist |
4.2 UMAP 实战
pip install umap-learn
# UMAP 需要安装: pip install umap-learn
try:
import umap
reducer = umap.UMAP(n_components=2, random_state=42)
X_umap = reducer.fit_transform(X_scaled)
# 三种方法对比
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
axes[0].scatter(X_2d[:, 0], X_2d[:, 1], c=y, cmap='tab10', s=10, alpha=0.6)
axes[0].set_title('PCA')
axes[1].scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='tab10', s=10, alpha=0.6)
axes[1].set_title('t-SNE')
axes[2].scatter(X_umap[:, 0], X_umap[:, 1], c=y, cmap='tab10', s=10, alpha=0.6)
axes[2].set_title('UMAP')
for ax in axes:
ax.grid(True, alpha=0.3)
plt.suptitle('PCA vs t-SNE vs UMAP(手写数字)', fontsize=13)
plt.tight_layout()
plt.show()
except ImportError:
print("请先安装 umap-learn: pip install umap-learn")
4.3 UMAP 参数
| 参数 | 说明 | 推荐 |
|---|---|---|
n_neighbors | 局部邻居数(类似 perplexity) | 15(默认) |
min_dist | 低维空间中点的最小距离 | 0.1(默认) |
n_components | 降维到的维度 | 2 或 3 |
metric | 距离度量 | 'euclidean'(默认) |
五、降维方法总结
| 方法 | 类型 | 速度 | 适用场景 |
|---|---|---|---|
| PCA | 线性 | 快 | 特征提取、数据压缩、预处理 |
| t-SNE | 非线性 | 慢 | 高维数据可视化(2D/3D) |
| UMAP | 非线性 | 中等 | 可视化 + 特征提取 |
5.1 第一次做项目时,怎么选最稳?
可以直接按下面这个默认顺序:
- 如果目的是建模预处理,先试
PCA - 如果目的是二维可视化,先试
PCA看 baseline,再试t-SNE - 如果数据更大、还想兼顾结构保持,再试
UMAP
这个顺序最稳,因为它先从最容易解释的方法开始。
七、第一次把降维放进项目里,最稳的默认顺序
第一次把降维真正放进项目里,可以先按这个顺序:
- 先明确目的:是提速、降噪,还是做可视化
- 如果是建模预处理,先试 PCA
- 先看保留 90% 和 95% 方差时的下游效果
- 如果是探索可视化,再补 t-SNE 或 UMAP
- 最后一定回到下游任务指标或业务解释来判断值不值得保留
这样你就不会把降维学成“哪个图更好看”,而是更像真实项目里的表示设计。
- 下一节:异常检测——找出数据中的"不正常"
- 第 4 站回顾:PCA 的特征值原理(1.3 节)
小结
| 要点 | 说明 |
|---|---|
| PCA | 线性降维,保留最大方差方向,可用于特征提取 |
| 方差解释比 | 累积达 90%~95% 即可确定保留多少主成分 |
| t-SNE | 非线性,专为可视化,保持局部结构 |
| UMAP | 比 t-SNE 快,能保持全局结构 |
这节最该带走什么
如果只带走一句话,我希望你记住:
降维不是为了把图画得更好看,而是为了在“信息保留”和“表示更紧凑”之间做有目的的取舍。
所以真正重要的是:
- 先分清建模预处理和可视化探索
- 知道 PCA 是默认起点
- 知道 t-SNE 和 UMAP 更偏探索和展示
- 知道最后还是要回到下游任务效果来判断
动手练习
练习 1:Iris PCA 降维
用 load_iris() 做 PCA 降维到 2D 和 3D(用 mpl_toolkits.mplot3d),对比哪种更好地分开了三个品种。
练习 2:方差解释比
用 load_wine() 数据做 PCA,画出 Scree Plot,确定保留多少主成分能达到 95% 的方差解释比。
练习 3:t-SNE vs PCA
用 load_digits() 数据,对比 PCA 和 t-SNE 在 2D 可视化上的效果。尝试不同的 perplexity 值(5, 15, 30, 50, 100),观察哪个效果最好。
练习 4:降维 + 分类
在 load_digits() 上,先用 PCA 降维到不同维度(5, 10, 20, 30, 50),再用逻辑回归分类,画出"维度 vs 准确率"曲线,找到最优维度。