学前导读:监督学习这一章到底在学什么
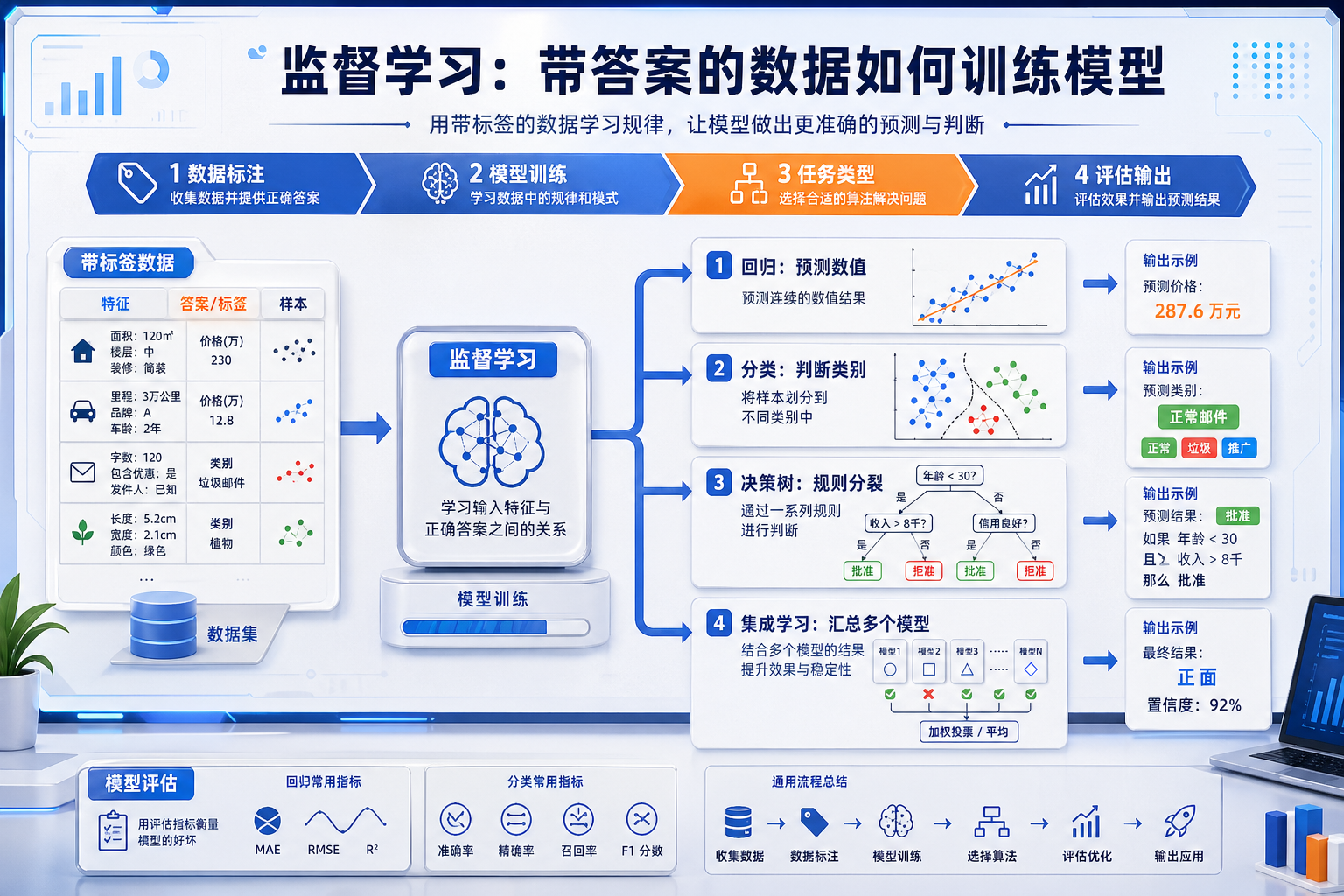
监督学习这一章是 5 机器学习入门到实战的主干,它解决的是:
当我们手上有带标签的数据时,怎样学出一个能做预测的模型。
先建立一张地图
这一章最容易学成“一个模型接一个模型”。
但更稳的理解方式是先把它看成一条渐进主线:
如果你先抓住“从简单到复杂、从单模型到多模型”这条线,这一章就会顺很多。
这一章的学习顺序为什么这样排
这条线是有层次的:
- 线性回归:先学最简单的连续值预测
- 逻辑回归:再学最基础的分类模型
- 决策树:再看非线性和规则划分
- 集成学习:最后看怎样把多个弱模型组合成更强模型
这一章更适合新人的读法
建议不要把它读成“4 篇互相独立的算法说明”,而是读成下面 4 个问题:
- 如果关系大致线性,能不能先用最简单模型解决?
- 如果任务变成分类,线性思路还能不能继续用?
- 如果关系明显非线性,能不能改成规则切分?
- 如果单个模型不够稳或不够强,能不能组合很多模型?
这会比单纯记模型名字更容易形成完整理解。
学这一章时最该养成什么习惯
- 每学一个模型,都问它更适合什么任务
- 每学一个模型,都问它最容易在哪种数据上吃亏
- 每学一个模型,都问它和前一个模型相比到底解决了什么新问题
这样你学到的就不是“工具列表”,而是“模型选择的判断链”。
新人这一章最该带走什么
- 知道回归和分类是两类不同任务
- 知道线性模型和树模型的差异
- 知道集成学习为什么常常更强
- 知道模型效果差时,不一定是算法太弱,也可能是数据和特征没处理好
学完这一章后,你应该能自己回答什么
- 为什么线性回归是起点
- 为什么逻辑回归虽然叫“回归”,却是分类模型
- 为什么树模型会更灵活,也更容易过拟合
- 为什么表格数据任务里,集成树模型常常特别强
新人和进阶学习者怎么读
新人第一次学这一章时,先抓住主线和最小可运行例子。你不需要一次理解所有细节,只要能说清楚这一章解决什么问题、输入输出是什么、最小项目怎么跑起来,就可以继续往后走。
有经验的学习者可以把这一章当成查漏补缺和工�程化练习:关注边界条件、失败案例、评估方式、代码可复现性,以及它和前后阶段的连接。读完后最好能把本章内容沉淀到自己的作品 README 或实验记录里。
学习时间与难度建议
| 学习方式 | 建议投入 | 目标 |
|---|---|---|
| 快速浏览 | 20~30 分钟 | 看懂本章解决什么问题,知道后面会用到哪里 |
| 最小通关 | 1~2 小时 | 跑通一个最小例子,完成本章小项目出口 |
| 深入练习 | 半天~1 天 | 补充错误分析、对比实验或项目 README 记录 |
本章自测问题
| 自测问题 | 通过标准 |
|---|---|
| 这一章解决什么问题? | 能用一句话说明它在整门课里的位置 |
| 最小输入输出是什么? | 能说清楚例子需要什么输入,会产生什么结果 |
| 常见失败点在哪里? | 能列出至少一个报错、效果差或理解偏差的原因 |
| 学完后能沉淀什么? | 能把本章产出写进项目 README、实验记录或作品集 |
本章小项目出口
学完这一章后,建议完成一个最小练习:选择一个本章最核心的概念或工具,做出一个可以运行、可以截图、可以写进 README 的小成果。它不需要复杂,但要能说明输入是什么、处理过程是什么、输出结果是什么。
过关标准
这一章结束时,你应该能用自己的话说明本章解决什么问题、它和前后学习站有什么关系,并能完成本章小项目出口的最小版本。
如果你还能记录一次常见错误、一次调试过程或一次结果改进,就说明你已经不只是“看过内容”,而是在把这一章变成自己的项目经验。