12 AIGC とマルチモーダル

第 12 章は最後の能力拡張です。AI はもうテキストだけを扱うものではありません。 画像、PDF、音声、動画、スクリーンショット、図表、生成素材が、同じプロダクトワークフローに入ります。
新しい Demo を追いかけすぎないでください。まず、非テキスト入力を構造化記録に変え、RAG や Agent へ接続し、素材を生成・編集し、リスクをレビューし、使える成果物として export する流れを学びます。
まずマルチモーダルワークフローを見る
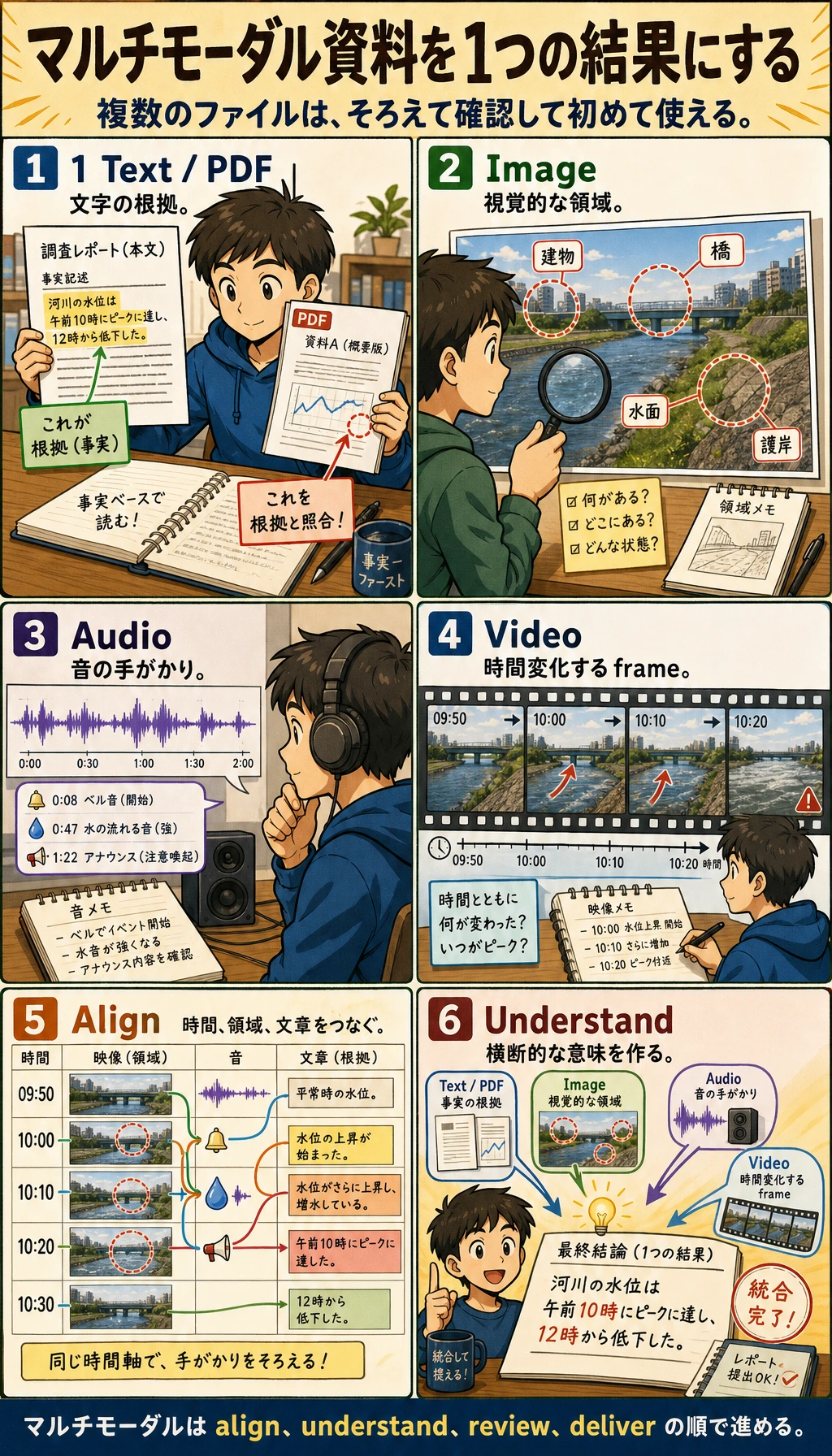
このワークフローを章全体の地図として使います。
| 層 | 何が起きるか | 残す証拠 |
|---|---|---|
| 入力 | text、screenshot、image、PDF、audio、video | source file、owner、license、version |
| 解析 / alignment | OCR、layout parsing、visual understanding、transcript | structured record、page/region/time reference |
| 理解 / 生成 | answer、caption、image、voice、storyboard、video plan | Prompt、model、output、candidate versions |
| 編集 / レビュー | human selection、factual check、copyright / portrait check | review checklist、rejected versions、reason |
| Export / 統合 | RAG index、Agent trace、creative package、Demo | README、export file、limitations、next step |
学習順序とタスク表
動画や完全な創作プラットフォームの前に、小さな追跡可能ワークフローを作ります。
| 手順 | 読む内容 | 手を動かすこと | 残す証拠 |
|---|---|---|---|
| 12.1 | マルチモーダル基礎 | 1枚の screenshot または image を構造化記録にする | source、visible text、objects、uncertainty |
| 12.2 | 画像生成 | Prompt、reference、negative requirements、selected output を記録 | Prompt 版とレビュー記録 |
| 12.3 | 動画、音声、デジタルヒューマン | storyboard、voice、shot、subtitle、timing を理解 | storyboard と asset list |
| 12.4 | 倫理とコンプライアンス | copyright、portrait rights、sensitive content、factual risk を確認 | safety review checklist |
| 12.5 | ステージプロジェクト | 12.5.3 実践:再現可能なマルチモーダル創作パッケージを作る を動かす | brief、Prompt、assets、storyboard、review、export preview |
最初に動かすループ:視覚入力を構造化する
このオフラインスクリプトは、マルチモーダルシステムの最初の工程を模擬します。モデルまたは人が画像を読んだ後、その結果は構造化され、確認できる記録になる必要があります。
ch12_visual_record.py を作成し、Python 3.10 以降で実行してください。
visual_record = {
"source": "course-slide-01.png",
"content_type": "course screenshot",
"visible_text": ["RAGOps", "evaluation set", "Trace", "cost monitoring"],
"objects": ["flowchart", "table"],
"uncertainty": ["small text in the lower-right corner is unclear"],
"next_step": "write into the multimodal RAG index for the course Q&A assistant to cite",
}
required_fields = {"source", "content_type", "visible_text", "objects", "uncertainty", "next_step"}
missing = required_fields - visual_record.keys()
rag_ready = not missing and bool(visual_record["visible_text"])
print("source:", visual_record["source"])
print("visible_text_count:", len(visual_record["visible_text"]))
print("uncertainty_count:", len(visual_record["uncertainty"]))
print("rag_ready:", rag_ready)
期待される出力:
source: course-slide-01.png
visible_text_count: 4
uncertainty_count: 1
rag_ready: True
操作メモ: page、region、timestamp フィールドを追加してください。あとで引用できる記録なら、マルチモーダル RAG に入れられます。確認や引用ができないものは、レビュー段階に残します。
マルチモーダルを RAG、Agent、創作ワークフローへ接続する

マルチモーダルは主線の外にある孤島ではありません。
| 主線スキル | マルチモーダル拡張 |
|---|---|
| RAG | PDF ページ、スクリーンショット、図表、画像キャプション、テキスト chunk を引用付きで検索 |
| Agent | スクリーンショットや文書を観察し、ツールを選び、追跡可能な action を残す |
| Prompt | 画像、音声、storyboard、review の Prompt を作り、版を残す |
| Engineering | asset、license、review、export file、latency、cost を記録 |
| Capstone | マルチモーダル学習アシスタントまたは創作ワークスペースを作る |
よくある失敗
- AIGC を「きれいな出力1つ」だと思い、ワークフローとして扱わない。
- OCR、PDF parsing、screenshot understanding の後に出典参照を失う。
- Prompt と版記録なしで生成結果を比較する。
- copyright、portrait rights、sensitive content、factual risk の人間レビューを省く。
- storyboard、asset、review rule が曖昧なまま動画生成へ進む。
クリア確認
コースを終える前に、次をできるようにしてください。
- text、image、PDF、audio、video が1つのワークフローに入る流れを説明できる。
- 視覚記録スクリプトを動かし、page、region、timestamp などの出典参照を追加できる。
- Prompt、asset、採用 output、不採用 output、レビュー理由を保存できる。
- マルチモーダル記録を RAG、Agent、または creative package に接続できる。
- マルチモーダルワークショップを動かし、README、review checklist、export preview、failure cases を残せる。
印刷用チェックリストは 12.0 学習チェックリスト を使ってください。卒業プロジェクトから始めたい場合は 12.5.3 実践:再現可能なマルチモーダル創作パッケージを作る へ進みます。