12 AIGC 与多模态

第 12 章是最后的能力拓展:AI 不再只处理文字。 图片、PDF、语音、视频、截图、图表和生成素材,都可以进入同一条产品工作流。
不要追每一个新 Demo。先学会把非文本输入转成结构化记录,接入 RAG 或 Agent,生成或编辑素材,审核风险,并导出可用结果。
先看多模态工作流
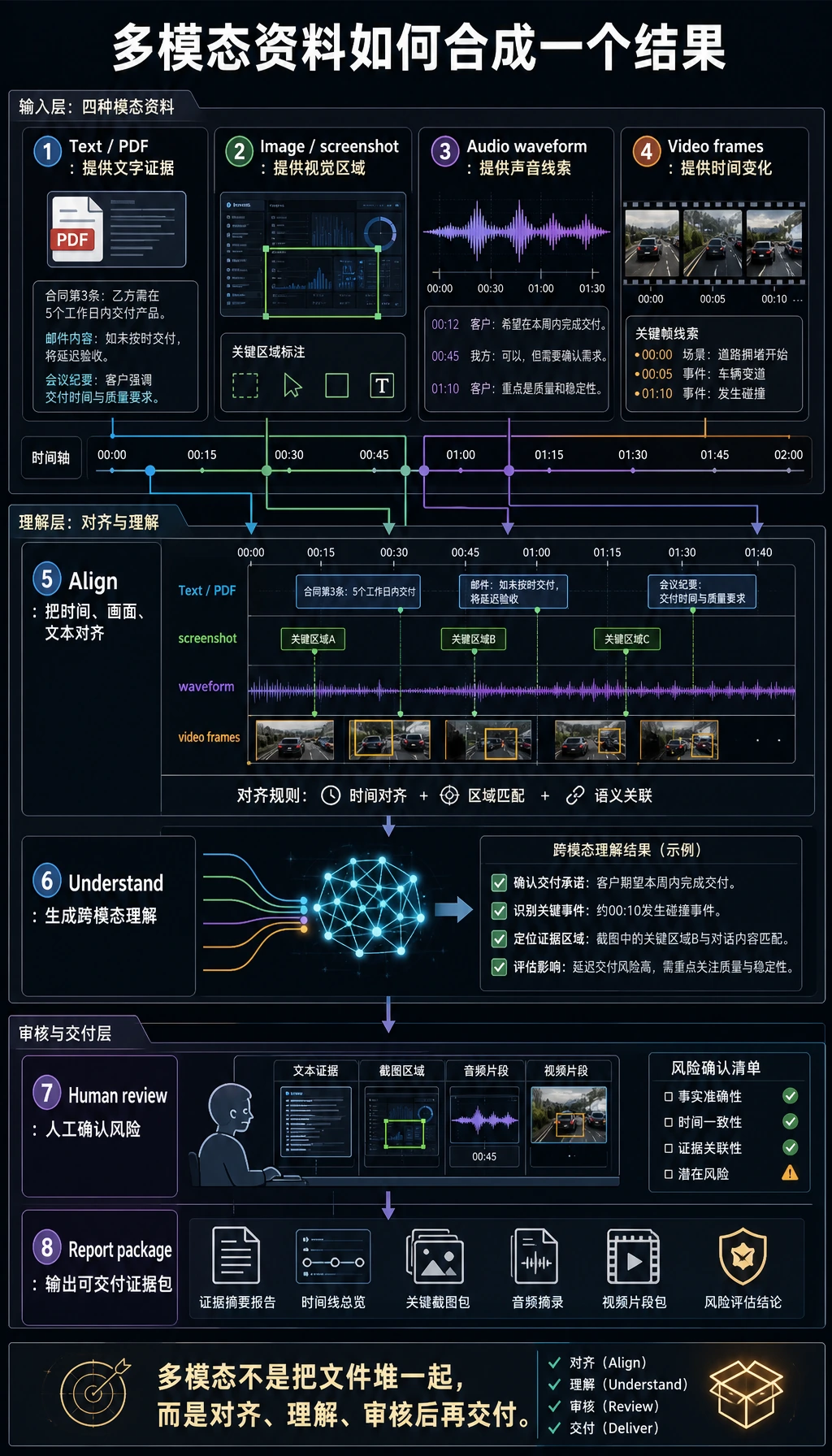
整章围绕这条工作流学习。
| 层 | 发生什么 | 留下什么证据 |
|---|---|---|
| 输入 | 文本、截图、图片、PDF、音频、视频 | 源文件、所有者、授权、版本 |
| 解析 / 对齐 | OCR、版面解析、视觉理解、转写 | 结构化记录、页码/区域/时间引用 |
| 理解 / 生成 | 答案、标题、图片、语音、分镜、视频计划 | Prompt、模型、输出、候选版本 |
| 编辑 / 审核 | 人工选择、事实检查、版权和肖像检查 | 审核清单、被拒版本、原因 |
| 导出 / 集成 | RAG 索引、Agent trace、创意包、Demo | README、导出文件、限制、下一步 |
学习顺序与任务表
先做一个可追踪的小工作流,再挑战视频或完整创意平台。
| 步骤 | 阅读内容 | 要动手做什么 | 留下什么证据 |
|---|---|---|---|
| 12.1 | 多模态基础 | 把一张截图或图片转成结构化记录 | 来源、可见文字、对象、不确定点 |
| 12.2 | 图像生成 | 记录 Prompt、参考、负面要求、选中结果 | Prompt 版本和审核记录 |
| 12.3 | 视频、语音、数字人 | 理解分镜、语音、镜头、字幕、时间线 | 分镜和素材清单 |
| 12.4 | 伦理与合规 | 检查版权、肖像、敏感内容、事实风险 | 安全审核清单 |
| 12.5 | 阶段项目 | 运行 12.5.3 实操:构建一个可复现的多模态创意包 | brief、Prompt、素材、分镜、审核、导出预览 |
第一个可运行循环:结构化视觉输入
这个离线脚本模拟多模态系统的第一步:模型或人工看完图片后,结果必须变成结构化、可检查的记录。
新建 ch12_visual_record.py,用 Python 3.10 或更新版本运行。
visual_record = {
"source": "course-slide-01.png",
"content_type": "course screenshot",
"visible_text": ["RAGOps", "evaluation set", "Trace", "cost monitoring"],
"objects": ["flowchart", "table"],
"uncertainty": ["small text in the lower-right corner is unclear"],
"next_step": "write into the multimodal RAG index for the course Q&A assistant to cite",
}
required_fields = {"source", "content_type", "visible_text", "objects", "uncertainty", "next_step"}
missing = required_fields - visual_record.keys()
rag_ready = not missing and bool(visual_record["visible_text"])
print("source:", visual_record["source"])
print("visible_text_count:", len(visual_record["visible_text"]))
print("uncertainty_count:", len(visual_record["uncertainty"]))
print("rag_ready:", rag_ready)
预期输出:
source: course-slide-01.png
visible_text_count: 4
uncertainty_count: 1
rag_ready: True
操作提示:增加 page、region 或 timestamp 字段。如果这条记录之后能被引用,就可以进入多模态 RAG;如果无法检查或引用,就应该留在审核阶段。
把多模态接到 RAG、Agent 和创意工作流

多模态不是主线之外的孤岛。
| 主线能力 | 多模态扩展 |
|---|---|
| RAG | 检索 PDF 页、截图、图表、图片描述和文本片段,并保留引用 |
| Agent | 观察截图或文档,选择工具,并留下可复盘动作 |
| Prompt | 为图片、语音、分镜和审核生成提示词,并保留版本 |
| 工程 | 记录素材、授权、审核、导出文件、延迟和成本 |
| 收官项目 | 构建多模态学习助手或创意工作台 |
常见错误
- 把 AIGC 当成“一张好看的结果”,而不是工作流。
- OCR、PDF 解析或截图理解后丢失来源引用。
- 没有 Prompt 和版本记录,就比较生成结果。
- 跳过版权、肖像、敏感内容或事实风险的人工审核。
- 分镜、素材和审核规则没清楚,就直接做视频生成。
通关检查
完成整门课程前,你应该能做到:
- 解释文本、图片、PDF、语音和视频如何进入同一条工作流;
- 运行视觉记录脚本,并增加页码、区域或时间戳等来源引用;
- 保留 Prompt、素材、选中输出、被拒输出和审核原因;
- 把多模态记录接入 RAG、Agent 或创意包;
- 跑通多模态工作坊,并保留 README、审核清单、导出预览和失败样本。
可打印清单见 12.0 学习检查表。如果想做收官项目,从 12.5.3 实操:构建一个可复现的多模态创意包 开始。