12.1.1 多模态路线图:编码、对齐、使用
多模态 AI 不是简单地“上传图片聊天”。真正有用的系统会把图片、文本、音频或视频变成结构化观察,再和任务对齐,最后进入检索、审核、创作或自动化流程。
先看流程图


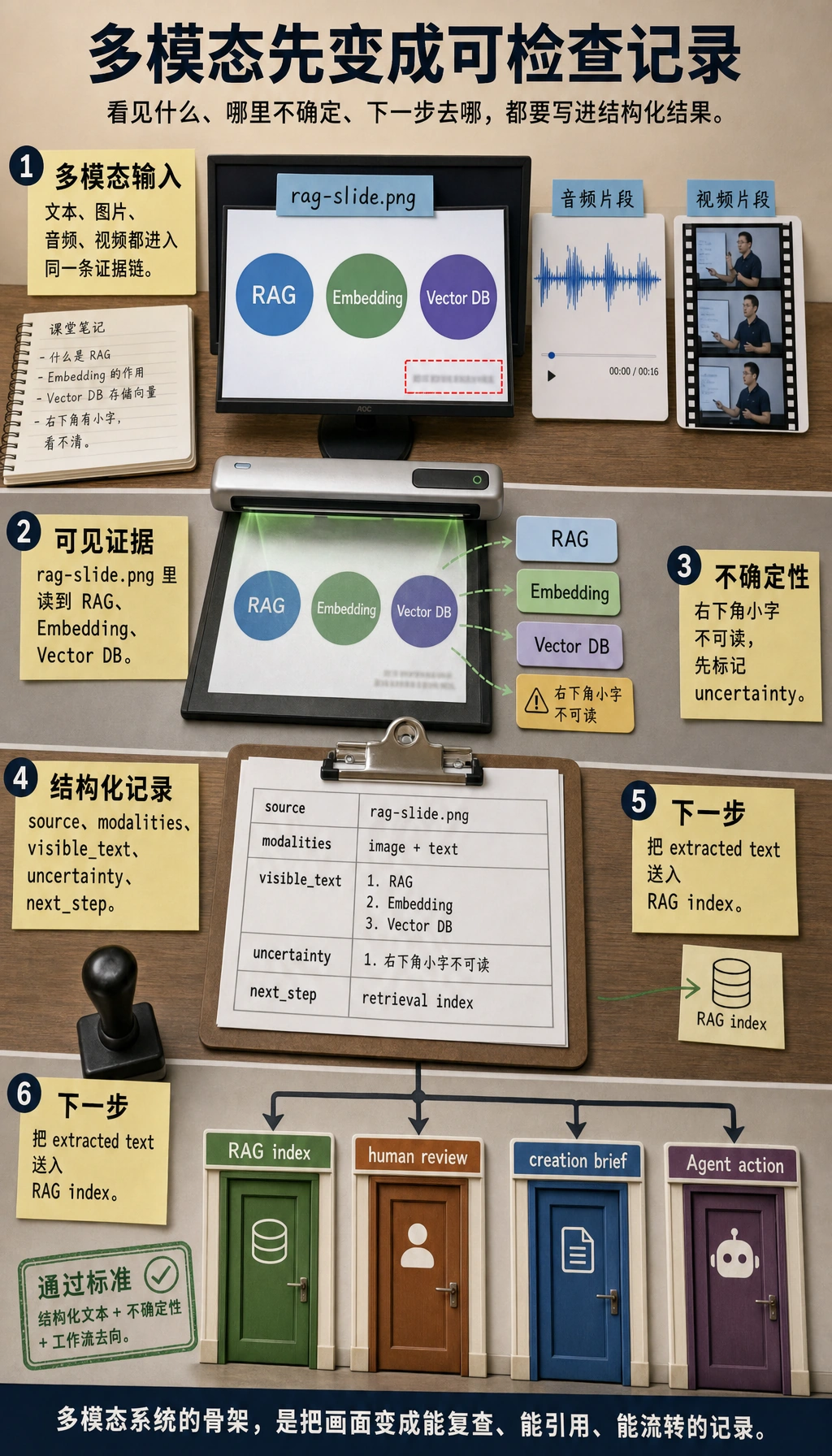
先养成一个习惯:输入是什么模态,看到了哪些证据,哪些地方不确定,结构化结果下一步要去哪里。
跑一个模拟视觉记录
import json
visible_text = ["RAG", "Embedding", "Vector DB"]
record = {
"source": "rag-slide.png",
"modalities": ["image", "text"],
"visible_text": visible_text,
"next_step": "send extracted text to retrieval index",
"uncertainty": ["small footer text is unreadable"],
}
print(json.dumps(record, indent=2))
预期输出:
{
"source": "rag-slide.png",
"modalities": [
"image",
"text"
],
"visible_text": [
"RAG",
"Embedding",
"Vector DB"
],
"next_step": "send extracted text to retrieval index",
"uncertainty": [
"small footer text is unreadable"
]
}
即使还没有接真实视觉模型,这个小记录也足够你先练产品里的数据结构。
按这个顺序学
| 步骤 | 阅读内容 | 练习产物 |
|---|---|---|
| 1 | 模态与表示 | 列出图片、文本、音频、视频输入及其结构化字段 |
| 2 | 对齐与融合 | 解释图片证据如何连接到文本任务 |
| 3 | 多模态应用 | 做一个截图或文档理解记录 |
通过标准
你能把一张图片或截图转成结构化文本,标记不确定性,并解释结果如何进入 RAG、审核或 Agent 工作流,就算通过本章。