11 NLP 专题:LLM 之后的文本任务
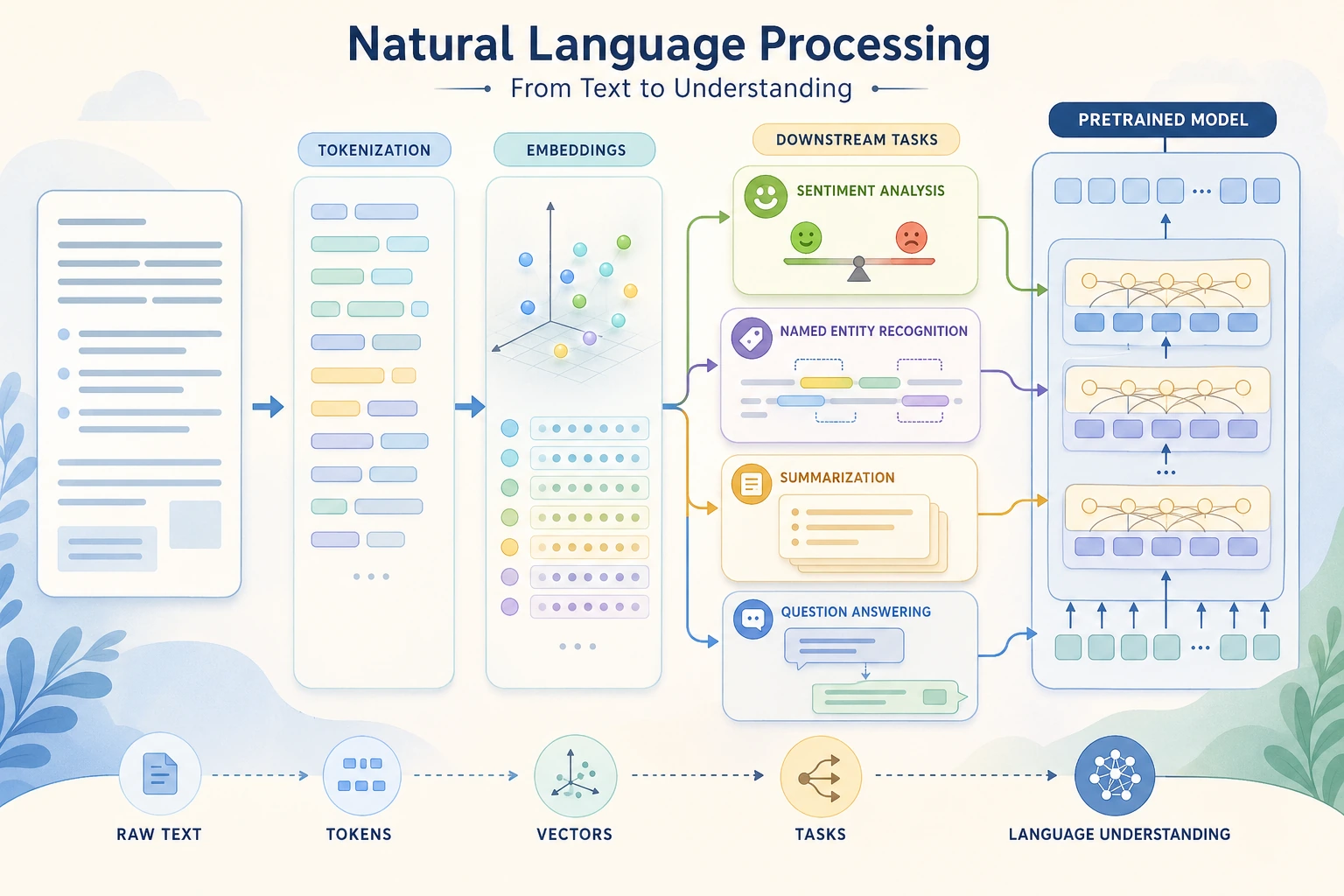
这一专题放在 LLM、RAG、Agent 主线之后。第 7 章已经给了最小 NLP 速通;第 11 章适合在真实产品需要更清楚的标签、更稳定的抽取、更可靠的评估,或一个不能只靠 LLM 硬撑的文本流水线时再回来学习。
本章的核心问题是:原始文本怎样变成模型可以分类、抽取、检索或生成的对象? LLM 把很多 NLP 步骤封装起来了,但 Prompt、RAG、Agent 记忆、检索、评估和信息抽取仍然离不开 NLP 思维。
如果你走最快的新手路线,先完成第 1-9 章,再回来做一个文本方向作品集项目。
先看文本到任务的流水线

整章围绕这张图学习。
| 步骤 | 发生什么 | 实操时检查什么 |
|---|---|---|
| 原始文本 | 用户评论、日志、文档、聊天、合同 | 来源和语言是什么? |
| 清洗 | 统一大小写、标点、特殊字符 | 清洗有没有删掉重要含义? |
| 分词 | 切成词、子词或 token | 领域术语有没有被错误切开? |
| 表示 | BoW、TF-IDF、embedding、上下文向量 | 哪种表示适合任务和数据量? |
| 任务输出 | 标签、实体、摘要、答案、检索结果 | 输出 schema 是否清楚? |
| 评估 | 指标、错例、事实检查 | 失败能不能复盘? |
学习顺序与任务表
先理解文本工作流,再学习模型家族。
| 步骤 | 阅读内容 | 要动手做什么 | 留下什么证据 |
|---|---|---|---|
| 11.1 | 文本基础与预处理 | 清洗、分词、规范化并检查样例 | 清洗脚本和前后对比 |
| 11.2 | Embedding 与语言模型 | 比较 BoW、TF-IDF、embedding、上下文含义 | 表示方法笔记 |
| 11.3 | 文本分类 | 做一个小标签任务 | 标签说明、指标、错例 |
| 11.4 | 序列标注 | 理解 NER 和 token 级字段 | 实体样例和边界案例 |
| 11.5 | Seq2Seq 与注意力 | 理解生成和翻译历史路线 | 摘要或翻译笔记 |
| 11.6 | 预训练模型 | 比较 BERT、GPT、T5、Transformers 用法 | 模型选择说明 |
| 11.7 | 阶段项目 | 运行 11.7.6 实操:构建一个可复现的 NLP 迷你流水线 | 数据文件、指标、抽取结果、失败报告 |
第一个可运行循环:标签、规则和评估
这个零依赖脚本故意很简单。它训练的是 NLP 项目的核心习惯:定义标签、在固定样本上预测,并保存错误。
新建 ch11_text_eval.py,用 Python 3.10 或更新版本运行。
samples = [
{"text": "RAG failed to retrieve the correct document", "expected": "retrieval"},
{"text": "The JSON output is missing a required field", "expected": "format"},
{"text": "The answer sounds fluent but cites no source", "expected": "citation"},
]
rules = {
"retrieval": ["retrieve", "document", "chunk"],
"format": ["json", "field", "schema"],
"citation": ["cite", "source", "evidence"],
}
def predict_label(text: str) -> str:
text = text.lower()
scores = {
label: sum(keyword in text for keyword in keywords)
for label, keywords in rules.items()
}
return max(scores, key=scores.get)
correct = 0
for row in samples:
pred = predict_label(row["text"])
ok = pred == row["expected"]
correct += int(ok)
print(f"pred={pred:<9} expected={row['expected']:<9} ok={ok} text={row['text']}")
print(f"accuracy={correct}/{len(samples)}")
预期输出:
pred=retrieval expected=retrieval ok=True text=RAG failed to retrieve the correct document
pred=format expected=format ok=True text=The JSON output is missing a required field
pred=citation expected=citation ok=True text=The answer sounds fluent but cites no source
accuracy=3/3
操作提示:新增一个容易混淆的样本,比如 "the document source field is missing"。如果规则系统失败,就记录问题是标签重叠、关键词覆盖不够,还是任务定义不清。后面换成 BERT、GPT 或 LLM 时,思路仍然一样。
按输出选择 NLP 任务

先确定输出,再选择模型。
| 目标输出 | 任务 | 评估什么 |
|---|---|---|
| 每段文本一个类别 | 分类 | accuracy、F1、混淆矩阵 |
| 实体或字段 | 抽取 / 序列标注 | precision、recall、字段有效性 |
| 基于来源生成新文本 | 摘要 / 生成 | 事实一致性、覆盖率、引用 |
| 从文档回答问题 | QA / 检索 | 命中率、答案质量、来源支撑 |
| 比较模型行为 | 预训练模型实验 | 质量、成本、延迟、数据需求 |
常见错误
- 还没定义标签或字段就直接上 LLM。
- 文本清洗过度,把含义删掉。
- 混淆分类、抽取、检索和生成的输出。
- 只看摘要是否流畅,不查事实一致性。
- 只报指标,不保留错例和边界样本。
通关检查
离开这个选修章前,你应该能做到:
- 解释清洗、分词、表示、任务输出和评估;
- 运行文本评估脚本,并添加至少一个混淆样本;
- 写出标签定义、字段 schema、边界案例和失败样本;
- 按输出类型选择分类、抽取、摘要、问答、检索或预训练模型对比;
- 跑通可复现 NLP 迷你流水线,并保留指标和失败案例。
可打印清单见 11.0 学习检查表。如果想直接做项目,从 11.7.6 实操:构建一个可复现的 NLP 迷你流水线 开始。