11.2.1 表示学习路线图:用向量表达语义
表示学习关心的是:文本如何变成带语义的数字,而不仅仅是编号。
先看表示路径
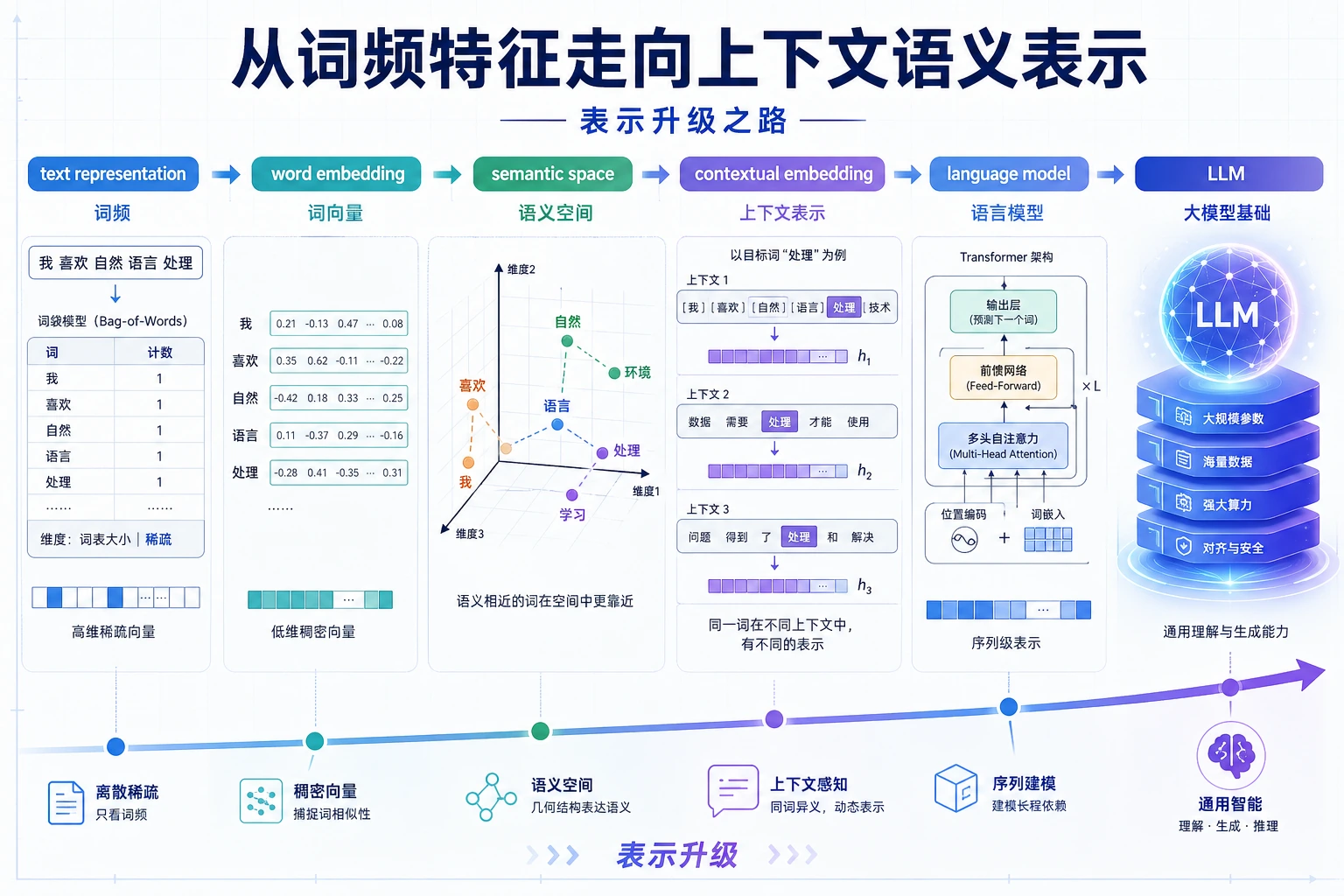
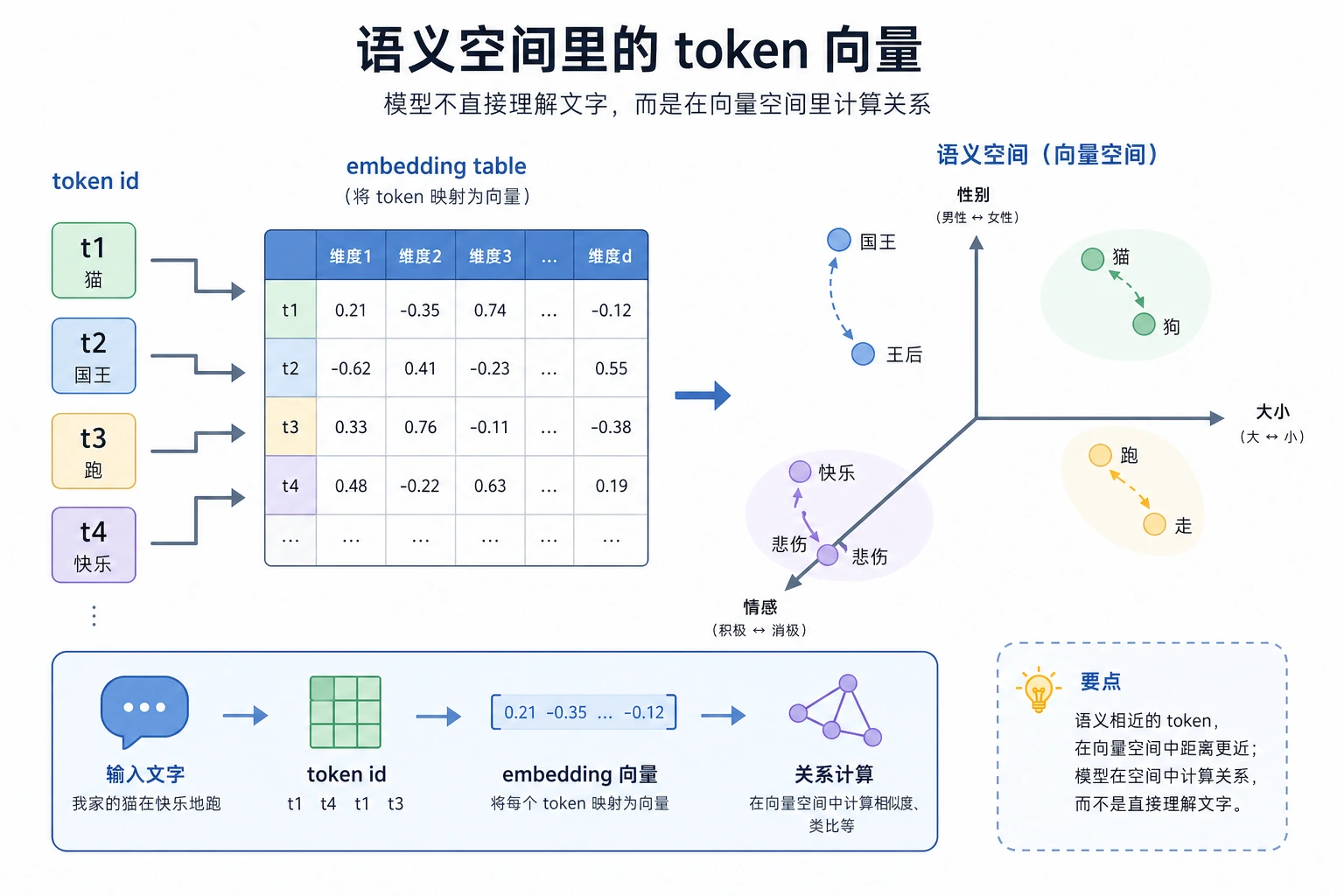
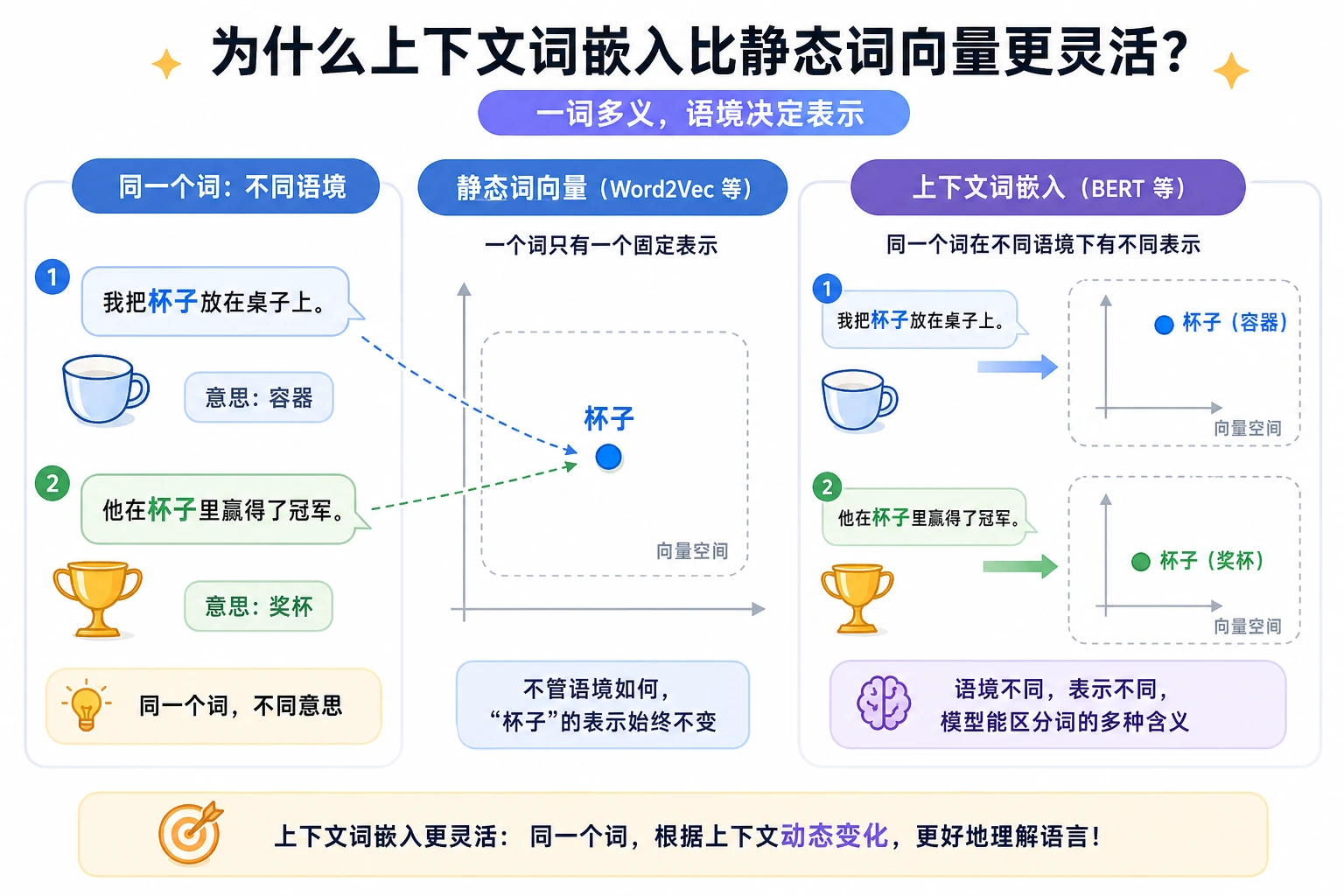
这条路径从稀疏词身份,到词向量,到上下文向量,再到学习更广泛语言模式的语言模型。
跑一个相似度检查
vectors = {
"cat": [1.0, 0.8],
"dog": [0.9, 0.7],
"car": [0.1, 0.2],
}
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
print("cat_dog:", round(dot(vectors["cat"], vectors["dog"]), 2))
print("cat_car:", round(dot(vectors["cat"], vectors["car"]), 2))
预期输出:
cat_dog: 1.46
cat_car: 0.26
这是玩具分数,但体现了核心思想:语义接近的文本,应该更容易被模型比较。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 词向量 | 解释语义接近等于向量接近 |
| 2 | 上下文化表示 | 解释同一个词为什么会有不同含义 |
| 3 | 语言模型 | 把表示学习连接到 next-token 或 masked prediction |
通过标准
如果你能比较稀疏特征、词向量和上下文向量,并解释表示质量为什么影响分类、检索和 RAG,就通过了本章。