11.1.4 文本表示方法
学习目标
完成本节后,你将能够:
- 理解为什么文本必须先表示成数字
- 掌握 one-hot、词袋模型、TF-IDF 的基本思路
- 写出一个简单的文本向量化示例
- 理解传统表示法和 embedding 的差异
这节和前面文本基础主线是怎么接上的
如果你刚看完 NLP 任务地图和预处理,这一节最自然的续接就是:
- 前面已经知道文本要先被切分、清洗、整理
- 这一节开始解决“整理完以后,怎样把文本变成模型能算的数字”
所以这节真正重要的不是几个向量化方法名,而是:
- 表示一旦变了,后面整个任务主线都会跟着变
一、为什么文本必须先数值化?
模型不能直接理解“退款规则”或“我喜欢这门课”这类文字本身。 它只能处理数字。
所以 NLP 里有一个绕不过去的步骤:
把文本变成向量。
这个过程叫:
- 文本表示
- 或向量化
第一次学 NLP 表示,最该先抓住什么?
最该先抓住的不是 one-hot / BoW / TF-IDF 名字,而是这句:
模型最终吃的是数字,而表示方式决定了模型到底能不能看见有用的信息。
一旦这句稳了,后面你看每种表示法时都会自然多问一句:
- 它到底保留了什么?
- 又丢掉了什么?
二、one-hot:最朴素的表示
假设词表只有 4 个词:
vocab = ["i", "love", "nlp", "python"]
print(vocab)
预期输出:
['i', 'love', 'nlp', 'python']
那每个词都可以用一个只有一个位置为 1 的向量表示:
i->[1, 0, 0, 0]love->[0, 1, 0, 0]nlp->[0, 0, 1, 0]python->[0, 0, 0, 1]
one-hot 的优点
- 简单
- 明确
one-hot 的局限
- 维度会很高
- 词和词之间没有语义关系
例如 love 和 like 在 one-hot 空间里并不会更接近。
one-hot 最值得先记住的,不是“简单”,而是“只会区分身份”
也就是说:
- 它能告诉模型“这是不是同一个词”
- 但几乎不告诉模型“这些词彼此关系怎样”
这也是后面为什么会自然走向:
- 词袋
- TF-IDF
- embedding
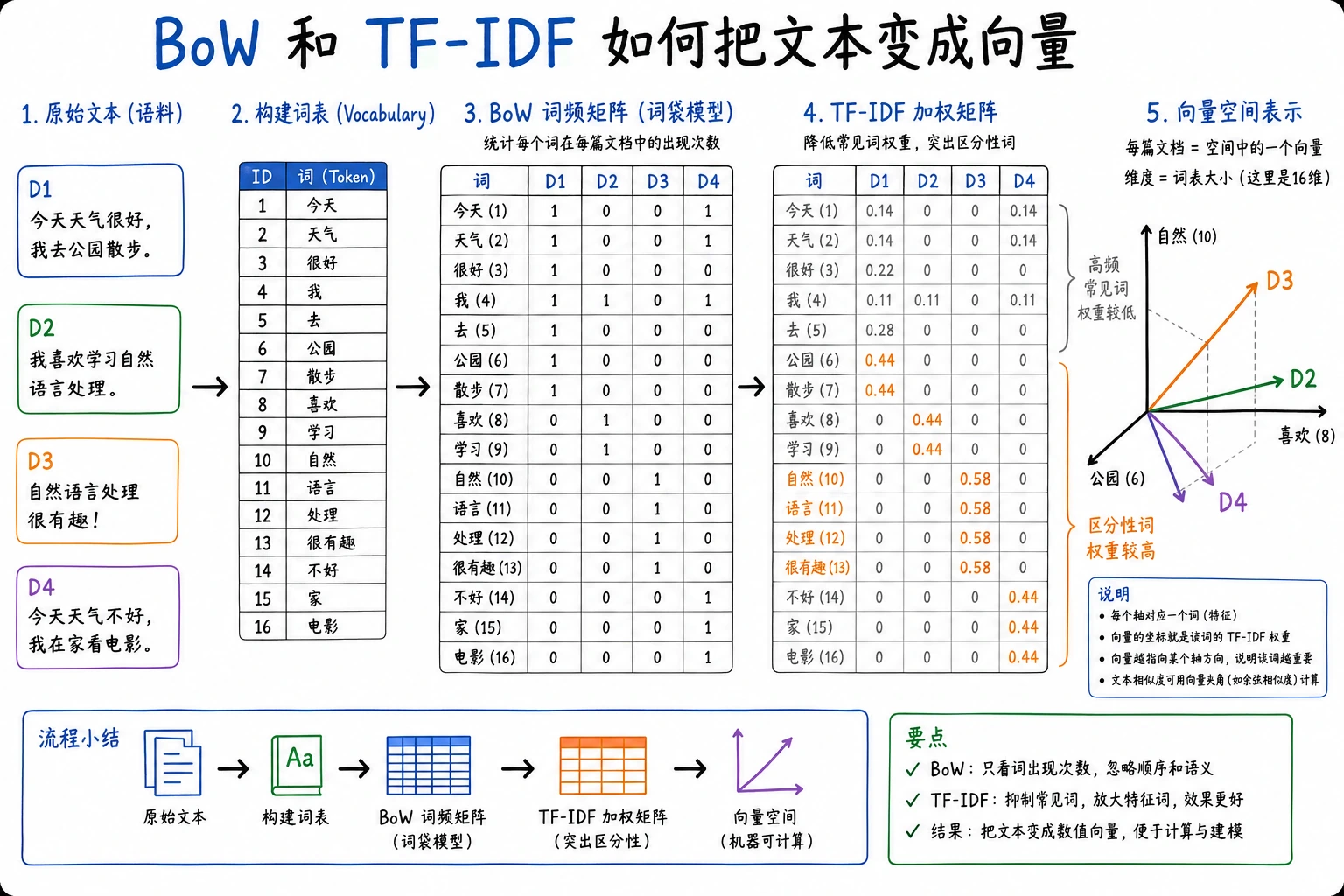
三、词袋模型(Bag of Words)
词袋模型的核心思想很直接:
不看词序,只看每个词出现了多少次。
下面给一个最小示例。
from collections import Counter
docs = [
"i love nlp",
"i love python",
"python love me",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
vocab_index = {word: idx for idx, word in enumerate(vocab)}
def to_bow_vector(tokens):
vector = [0] * len(vocab)
counts = Counter(tokens)
for word, count in counts.items():
vector[vocab_index[word]] = count
return vector
print("词表:", vocab)
for doc, tokens in zip(docs, tokenized_docs):
print(doc, "->", to_bow_vector(tokens))
预期输出:
词表: ['i', 'love', 'me', 'nlp', 'python']
i love nlp -> [1, 1, 0, 1, 0]
i love python -> [1, 1, 0, 0, 1]
python love me -> [0, 1, 1, 0, 1]
向量里的每个位置对应一个词表项,数字表示这个词在当前文档里出现了几次。
这个表示法的直觉是什么?
它把句子变成了:
- 一个固定长度的数字向量
这样后面分类器就能处理。
它的局限是什么?
它不看顺序。 例如:
- “狗咬人”
- “人咬狗”
在词袋表示里可能非常接近,但含义完全不同。
为什么词袋虽然“粗”,却依然很重要?
因为它第一次帮你建立了一件很重要的感觉:
- 文本可以先变成固定长度向量
- 然后就能交给传统模型去做分类、检索和聚类
所以词袋模型的教学价值很高,它让你第一次真正看到“文本进模型”的最小入口。
四、TF-IDF:让更有区分度的词权重更高
词袋只管计数, 但很多高频词并没有太强区分力。
例如在英文里:
- the
- is
- and
于是 TF-IDF 的思路就是:
- 当前文档里出现得多的词更重要
- 但如果这个词在所有文档里都很常见,它的重要性要打折
五、一个纯 Python 的简单 TF-IDF 示例
import math
from collections import Counter
docs = [
"python is great for data analysis",
"python is great for machine learning",
"basketball is a great sport",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
def compute_idf(tokenized_docs, vocab):
n_docs = len(tokenized_docs)
idf = {}
for word in vocab:
df = sum(1 for doc in tokenized_docs if word in doc)
idf[word] = math.log((n_docs + 1) / (df + 1)) + 1
return idf
idf = compute_idf(tokenized_docs, vocab)
def to_tfidf(tokens, vocab, idf):
counts = Counter(tokens)
total = len(tokens)
vector = []
for word in vocab:
tf = counts[word] / total
vector.append(round(tf * idf[word], 4))
return vector
print("词表:", vocab)
for doc, tokens in zip(docs, tokenized_docs):
print(doc)
print(to_tfidf(tokens, vocab, idf))
预期输出:
词表: ['a', 'analysis', 'basketball', 'data', 'for', 'great', 'is', 'learning', 'machine', 'python', 'sport']
python is great for data analysis
[0.0, 0.2822, 0.0, 0.2822, 0.2146, 0.1667, 0.1667, 0.0, 0.0, 0.2146, 0.0]
python is great for machine learning
[0.0, 0.0, 0.0, 0.0, 0.2146, 0.1667, 0.1667, 0.2822, 0.2822, 0.2146, 0.0]
basketball is a great sport
[0.3386, 0.0, 0.3386, 0.0, 0.0, 0.2, 0.2, 0.0, 0.0, 0.0, 0.3386]
is、great 这样的常见词仍然会出现,但 basketball、analysis 这类更能区分文档的词,会在各自文档里获得更高权重。
TF-IDF 最重要的直觉
它会压低“到处都常见”的词, 放大“在当前文本里特别有代表性”的词。
第一次学 TF-IDF,最值得先问什么?
最值得先问的是:
- 哪些词只是常见噪声?
- 哪些词对当前文本更有区分力?
这样你就会更容易理解,TF-IDF 真正做的不是“更复杂计数”,而是在做:
- 区分度加权
六、向量化之后,文本就能比较相似度
最常见的是:
- 余弦相似度
可以先简单理解成:
两个向量朝向有多接近。
import math
from collections import Counter
docs = [
"i love python",
"i love coding",
"weather is sunny",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
vocab_index = {word: idx for idx, word in enumerate(vocab)}
def to_bow(tokens):
vector = [0] * len(vocab)
counts = Counter(tokens)
for word, count in counts.items():
vector[vocab_index[word]] = count
return vector
def cosine_similarity(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = math.sqrt(sum(x * x for x in a))
norm_b = math.sqrt(sum(y * y for y in b))
if norm_a == 0 or norm_b == 0:
return 0.0
return dot / (norm_a * norm_b)
vec1 = to_bow(tokenized_docs[0])
vec2 = to_bow(tokenized_docs[1])
vec3 = to_bow(tokenized_docs[2])
print("句子1 vs 句子2:", round(cosine_similarity(vec1, vec2), 4))
print("句子1 vs 句子3:", round(cosine_similarity(vec1, vec3), 4))
预期输出:
句子1 vs 句子2: 0.6667
句子1 vs 句子3: 0.0
前两个句子共享 i 和 love,所以向量方向更接近。天气句子和第一句没有共享词,因此相似度是 0.0。
这个例子通常会得到:
i love python和i love coding更近- 与
weather is sunny更远
七、传统表示法和 embedding 的区别是什么?
传统表示法
例如:
- one-hot
- BoW
- TF-IDF
优点:
- 简单
- 可解释
局限:
- 语义表达能力有限
- 对上下文不敏感
为什么这一节最后一定要把 embedding 拉进来?
因为这正是 11 自然语言处理(方向选修)主线真正开始抬升的地方:
- 传统表示法更像“统计出现”
- embedding 开始真正进入“语义空间”
所以这一节其实是在给后面表示学习一章做桥:
- 先让你看清传统表示的价值
- 再让你自然意识到它们为什么会不够
Embedding
embedding 的核心目标是:
- 让语义相近的词在向量空间里也更接近
所以后面我们才会继续学:
- 词嵌入
- 上下文表示
八、最常见误区
误区一:one-hot 太简单,所以没必要学
它很重要,因为它帮你理解“文本必须先数值化”这件事。
误区二:TF-IDF 一定过时
在很多传统文本分类和检索基线里,它依然很有价值。
误区三:有了向量就等于理解语义
向量化只是开始。 后面还要看:
- 语义表示质量
- 上下文建模
小结
文本表示这一节最重要的是建立一个非常基础但非常关键的判断:
机器不能直接读文本,所以 NLP 必须先把文本变成数字表示;不同表示法的差异,决定了模型后面能利用到多少信息。
这也是为什么从 one-hot、BoW、TF-IDF,一路走向 embedding 和语言模型,实际上是一条非常自然的演进线。
这节最该带走什么
- 表示方法不是小技巧,而是 NLP 的入口层
- one-hot / BoW / TF-IDF 是从“身份”到“统计区分度”的演进
- embedding 会成为后面真正进入语义表示和预训练主线的转折点
练习
- 自己给
docs再加 2 句文本,重新观察 BoW 和 TF-IDF 向量。 - 为什么词袋模型会忽略语序?
- 用自己的话解释:TF-IDF 为什么会压低过于常见的词?
- 想一想:如果任务特别依赖词序,仅靠 BoW 或 TF-IDF 会遇到什么问题?