11.1.4 テキスト表現方法
学習目標
この節を終えると、次のことができるようになります。
- なぜテキストを先に数字で表す必要があるのかを理解する
- one-hot、Bag of Words、TF-IDF の基本的な考え方を身につける
- 簡単なテキストのベクトル化例を書ける
- 従来の表現方法と embedding の違いを理解する
この節は、前のテキスト基礎の流れとどうつながるのか
NLP タスクマップと前処理を見終わったばかりなら、この節はその自然な続きです。
- 前の節では、テキストを切り分け、きれいにし、整理することを学びました
- この節では、その次にある「整理したあと、どうやってテキストをモデルが扱える数字に変えるか」を考えます
だから、この節で本当に大事なのは、いくつかのベクトル化手法の名前ではなく、次の点です。
- 表現方法が変わると、その後のタスク全体の進み方も変わる
一、なぜテキストは数値化が必要なのか?
モデルは「返金ルール」や「この授業が好きです」といった文字そのものを直接理解できません。
モデルが扱えるのは数字だけです。
そのため、NLP では避けられない手順があります。
テキストをベクトルに変える。
この手順は次のようにも呼ばれます。
- テキスト表現
- ベクトル化
NLP の表現を初めて学ぶとき、まず何をつかむべきか?
まず大事なのは、one-hot / BoW / TF-IDF という名前ではなく、次の一文です。
モデルが最終的に受け取るのは数字であり、表現方法によってモデルが有用な情報を見られるかどうかが決まる。
この感覚がしっかりすると、後でどの表現方法を見るときも、自然に次のことを考えられるようになります。
- 何が残っているのか?
- 何が失われているのか?
二、one-hot:いちばん素朴な表現
たとえば、語彙が 4 語だけだとします。
vocab = ["i", "love", "nlp", "python"]
print(vocab)
実行結果の例:
['i', 'love', 'nlp', 'python']
このとき、それぞれの単語は、1 か所だけが 1 のベクトルで表せます。
i->[1, 0, 0, 0]love->[0, 1, 0, 0]nlp->[0, 0, 1, 0]python->[0, 0, 0, 1]
one-hot のよい点
- シンプル
- わかりやすい
one-hot の限界
- 次元が非常に大きくなりやすい
- 単語どうしの意味的な関係が表せない
たとえば、love と like は one-hot 空間では近くなりません。
one-hot でまず覚えるべきことは、「単純」ではなく「身分しか区別しない」こと
つまり、one-hot ができるのは次のことです。
- 「これは同じ単語かどうか」をモデルに伝える
- でも、「これらの単語がどう関係しているか」はほとんど伝えない
だからこそ、次の表現方法へ自然につながっていきます。
- Bag of Words
- TF-IDF
- embedding
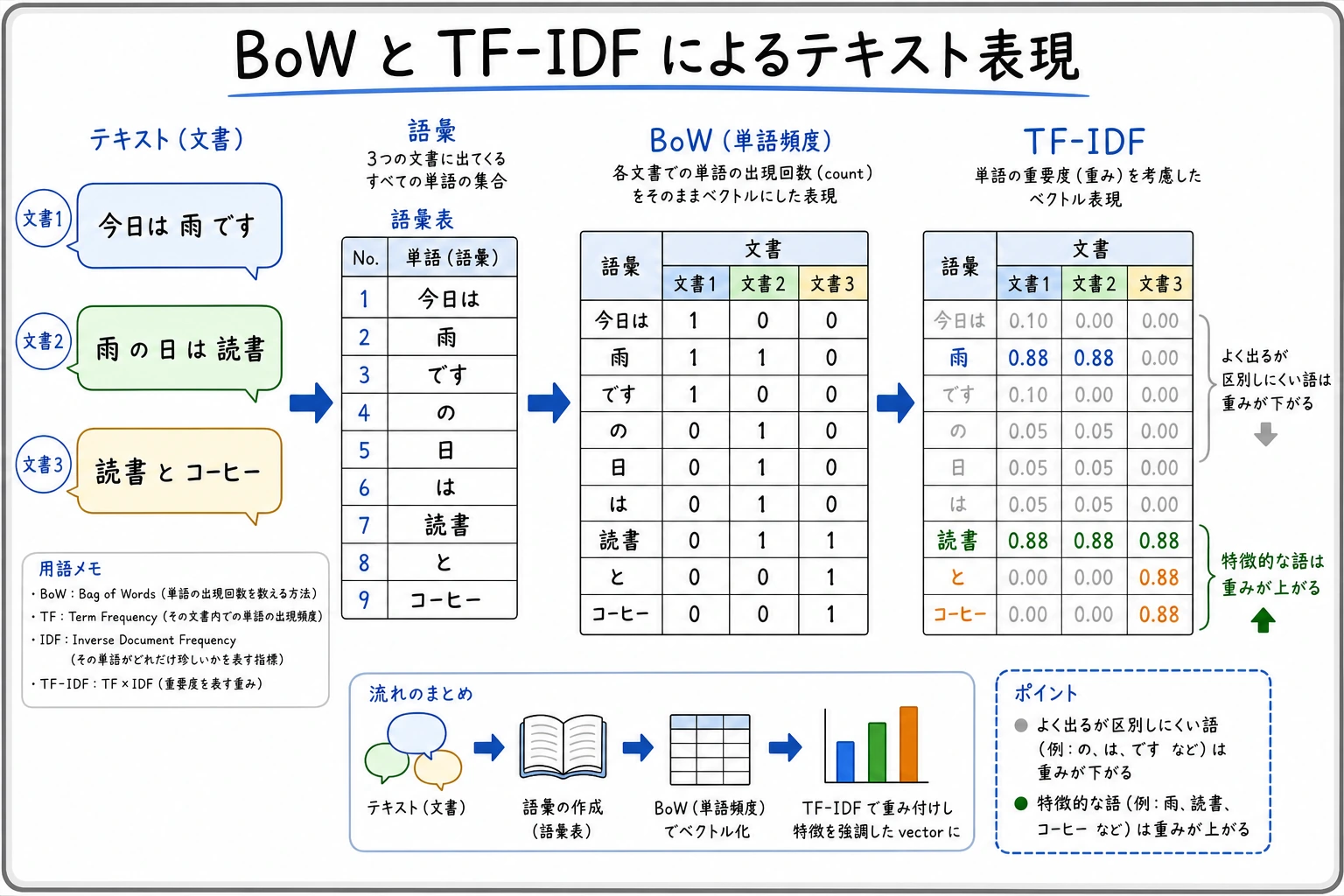
三、Bag of Words(単語の袋)
Bag of Words の核となる考え方は、とてもシンプルです。
語順は見ずに、それぞれの単語が何回出たかだけを見る。
最小の例を見てみましょう。
from collections import Counter
docs = [
"i love nlp",
"i love python",
"python love me",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
vocab_index = {word: idx for idx, word in enumerate(vocab)}
def to_bow_vector(tokens):
vector = [0] * len(vocab)
counts = Counter(tokens)
for word, count in counts.items():
vector[vocab_index[word]] = count
return vector
print("語彙:", vocab)
for doc, tokens in zip(docs, tokenized_docs):
print(doc, "->", to_bow_vector(tokens))
実行結果の例:
語彙: ['i', 'love', 'me', 'nlp', 'python']
i love nlp -> [1, 1, 0, 1, 0]
i love python -> [1, 1, 0, 0, 1]
python love me -> [0, 1, 1, 0, 1]
ベクトルの各位置は語彙の 1 語に対応し、数字はその単語が文書内に何回出たかを表します。
この表現方法の直感は?
文を次のものに変えています。
- 固定長の数値ベクトル
こうすると、後で分類器が扱えるようになります。
限界は?
語順を見ません。
たとえば、
- 「犬が人をかむ」
- 「人が犬をかむ」
は、Bag of Words ではかなり似た表現になりますが、意味はまったく違います。
Bag of Words は「粗い」のに、なぜ今でも大事なのか?
それは、次の大事な感覚を初めてつかめるからです。
- テキストはまず固定長ベクトルにできる
- そのあとで、従来型のモデルに分類、検索、クラスタリングを任せられる
つまり Bag of Words は、テキストをモデルに入れる最小の入口を、最初に実感させてくれる重要な方法です。
四、TF-IDF:区別に役立つ単語の重みを高くする
Bag of Words は数えるだけですが、
よく出る単語の中には、あまり区別に役立たないものもたくさんあります。
たとえば英語では、
- the
- is
- and
のような単語です。
そこで TF-IDF の考え方はこうです。
- その文書の中でよく出る単語は重要
- ただし、その単語がすべての文書でよく出るなら、重要度を下げる
五、純 Python で書く簡単な TF-IDF の例
import math
from collections import Counter
docs = [
"python is great for data analysis",
"python is great for machine learning",
"basketball is a great sport",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
def compute_idf(tokenized_docs, vocab):
n_docs = len(tokenized_docs)
idf = {}
for word in vocab:
df = sum(1 for doc in tokenized_docs if word in doc)
idf[word] = math.log((n_docs + 1) / (df + 1)) + 1
return idf
idf = compute_idf(tokenized_docs, vocab)
def to_tfidf(tokens, vocab, idf):
counts = Counter(tokens)
total = len(tokens)
vector = []
for word in vocab:
tf = counts[word] / total
vector.append(round(tf * idf[word], 4))
return vector
print("語彙:", vocab)
for doc, tokens in zip(docs, tokenized_docs):
print(doc)
print(to_tfidf(tokens, vocab, idf))
実行結果の例:
語彙: ['a', 'analysis', 'basketball', 'data', 'for', 'great', 'is', 'learning', 'machine', 'python', 'sport']
python is great for data analysis
[0.0, 0.2822, 0.0, 0.2822, 0.2146, 0.1667, 0.1667, 0.0, 0.0, 0.2146, 0.0]
python is great for machine learning
[0.0, 0.0, 0.0, 0.0, 0.2146, 0.1667, 0.1667, 0.2822, 0.2822, 0.2146, 0.0]
basketball is a great sport
[0.3386, 0.0, 0.3386, 0.0, 0.0, 0.2, 0.2, 0.0, 0.0, 0.0, 0.3386]
is や great のような共通語も残りますが、basketball や analysis のように文書を区別しやすい語は、その文書内でより強い重みを持ちます。
TF-IDF でいちばん大事な直感
TF-IDF は、「どこにでもある単語」の重みを下げ、
「その文書にとって特に特徴的な単語」の重みを上げます。
TF-IDF を初めて学ぶとき、まず何を考えるべきか?
まず考えるべきなのは、次の 2 つです。
- どの単語は、ただのよくあるノイズなのか?
- どの単語が、この文書を見分けるのに役立つのか?
こう考えると、TF-IDF が本当にやっていることは「複雑な数え上げ」ではなく、次のような重み付けだとわかります。
- 区別しやすさに応じた重み付け
六、ベクトル化すると、テキスト同士の類似度を比べられる
よく使われるのは、次の方法です。
- コサイン類似度
まずは、次のようにざっくり理解すれば十分です。
2 つのベクトルが、どれくらい同じ方向を向いているかを測る。
import math
from collections import Counter
docs = [
"i love python",
"i love coding",
"weather is sunny",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
vocab_index = {word: idx for idx, word in enumerate(vocab)}
def to_bow(tokens):
vector = [0] * len(vocab)
counts = Counter(tokens)
for word, count in counts.items():
vector[vocab_index[word]] = count
return vector
def cosine_similarity(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = math.sqrt(sum(x * x for x in a))
norm_b = math.sqrt(sum(y * y for y in b))
if norm_a == 0 or norm_b == 0:
return 0.0
return dot / (norm_a * norm_b)
vec1 = to_bow(tokenized_docs[0])
vec2 = to_bow(tokenized_docs[1])
vec3 = to_bow(tokenized_docs[2])
print("文 1 vs 文 2:", round(cosine_similarity(vec1, vec2), 4))
print("文 1 vs 文 3:", round(cosine_similarity(vec1, vec3), 4))
実行結果の例:
文 1 vs 文 2: 0.6667
文 1 vs 文 3: 0.0
最初の2文は i と love を共有しているため、ベクトルの向きが近くなります。天気の文は最初の文と共通語彙がないため、類似度は 0.0 です。
この例では、たいてい次のようになります。
i love pythonとi love codingは近いweather is sunnyとは遠い
七、従来の表現方法と embedding の違いは何か?
従来の表現方法
たとえば次のものです。
- one-hot
- BoW
- TF-IDF
よい点:
- シンプル
- 解釈しやすい
限界:
- 意味表現が弱い
- 文脈に弱い
この節の最後で embedding を必ず入れるのはなぜか?
それは、11 自然言語処理(選択分野)の流れが、ここから本格的に上がっていくからです。
- 従来の表現方法は、「出現の統計」を見るものに近い
- embedding は、本格的に「意味空間」へ入っていく
だからこの節は、後の表現学習の章への橋渡しになります。
- まず従来の表現の価値を理解する
- そのうえで、なぜそれだけでは足りないのかを自然に感じる
Embedding
embedding の中心的な目的は、次のとおりです。
- 意味の近い単語が、ベクトル空間でも近くなるようにする
だから、後で次の内容を学んでいきます。
- 単語埋め込み
- 文脈表現
八、よくある誤解
誤解その一:one-hot は簡単すぎるから学ぶ必要がない
one-hot はとても重要です。
なぜなら、「テキストをまず数値化する必要がある」という基本を理解する助けになるからです。
誤解その二:TF-IDF はもう古い
多くの従来型のテキスト分類や検索のベースラインでは、今でも十分に価値があります。
誤解その三:ベクトルがあれば意味を理解したことになる
ベクトル化はあくまで出発点です。
その後にさらに見るべきなのは、次の点です。
- 意味表現の質
- 文脈モデリング
まとめ
この節でいちばん大事なのは、とても基本的だけれど、とても重要な判断を持つことです。
機械はテキストをそのまま読むことができない。だから NLP ではまずテキストを数値表現に変える必要がある。どの表現方法を使うかで、後のモデルが使える情報量が決まる。
だからこそ、one-hot、BoW、TF-IDF から embedding、そして言語モデルへ進んでいく流れは、実はとても自然な進化なのです。
この節で必ず持ち帰ってほしいこと
- 表現方法は小技ではなく、NLP の入口
- one-hot / BoW / TF-IDF は、「身分」から「統計的な区別のしやすさ」へ進む流れ
- embedding は、このあと意味表現と事前学習の主流に入るための転換点になる
練習問題
docsにさらに 2 文追加して、BoW と TF-IDF のベクトルをもう一度見てみましょう。- なぜ Bag of Words は語順を無視するのでしょうか?
- 自分の言葉で説明してみましょう。TF-IDF はなぜ、あまりにもよく出る単語の重みを下げるのでしょうか?
- 考えてみましょう。もしタスクが語順に強く依存するなら、BoW や TF-IDF だけではどんな問題が起きるでしょうか?