11.1.3 テキスト前処理
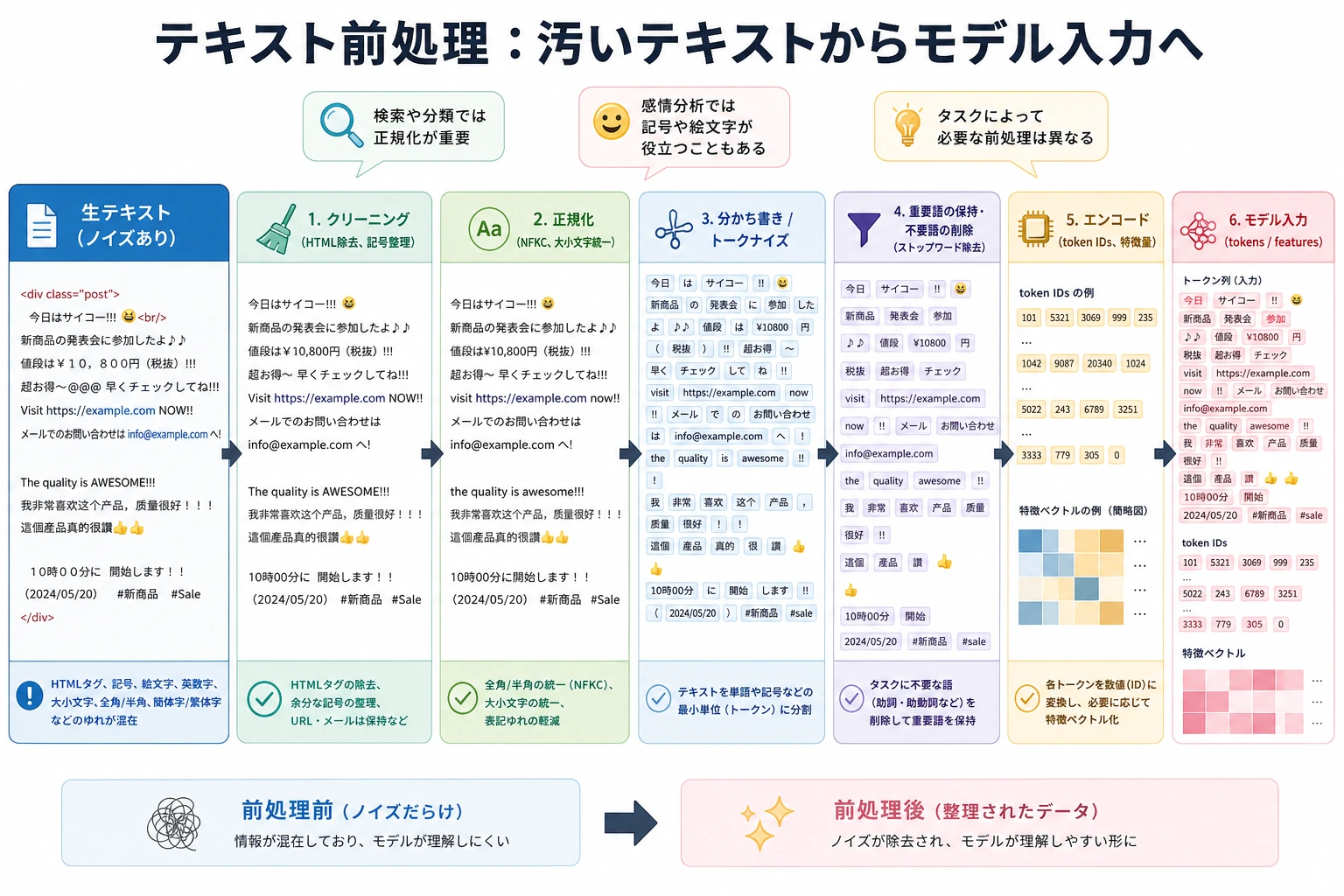
テキスト前処理は、初心者が次のように誤解しやすいです。
- 決まった流れがある
でも、実際はもっと次のイメージに近いです。
- タスクに合わせて選ぶ整理ツールのセット
だからこの節でいちばん大事なのは、手順を暗記することではなく、まず次の判断軸を持つことです。
なぜこの処理をするのか、何を残して何を失うのか。
学習目標
この節を終えると、次のことができるようになります。
- テキスト前処理が何を解決するのか理解する
- クリーニング、正規化、分かち書き、ストップワードなどのよくある手順を理解する
- そのまま実行できる前処理関数を書く
- 前処理は「強ければ強いほど良い」のではなく、タスク駆動で考えると理解する
まず地図を作ろう
テキスト前処理は、「タスク -> 情報 -> 操作」の順で考えると理解しやすいです。
この節で本当に解決したいのは、次の2つです。
- なぜ前処理は強ければ強いほど良いわけではないのか
- 同じテキストでも、タスクが違うと処理方法が変わるのはなぜか
なぜテキストを前処理するのか?
元のテキストは、たいていかなり「汚れています」。
- 大文字・小文字が揃っていない
- 句読点が多い
- リンク、数字、絵文字が混ざっている
- 同じ意味でも書き方がたくさんある
テキスト前処理は、「野菜を洗う」ことに似ています。
- 洗わないと、モデルはそのまま料理しにくい
- 洗いすぎると、栄養まで流れてしまうかもしれない
だから前処理の核心は、「できるだけきれいにする」ことではなく、次のように考えることです。
今のタスクに合う形に整える。
初心者向けの、よりわかりやすい比喩
テキスト前処理は、次のようにも考えられます。
- 出かける前にカバンを整理する
登山に行くのと、会社に行くのでは、持っていく物が違います。
同じように、
- 感情分析では、否定語がとても重要
- 検索では、キーワードのカバー範囲が重要
- 固有表現認識では、大文字・小文字や書式情報が重要なことがある
つまり前処理は、
- いつも同じ作業をするもの
ではなく、
- 何をしたいかに合わせて選ぶもの
です。
前処理でよくある手順
| 手順 | よくある役割 |
|---|---|
| 小文字化 | 英字の大文字・小文字を統一する |
| リンク / 特殊記号の削除 | 意味の少ないノイズを減らす |
| 余分な空白の削除 | 形式を統一する |
| 分かち書き | より小さな処理単位に分ける |
| ストップワード処理 | 頻出するが情報量の少ない語を除く |
| 数字 / 特殊パターンの正規化 | ある種のルールパターンを統一する |
ただし、覚えておいてください。
- これらを毎回全部やるわけではない
- 多くやれば多いほど良いわけでもない
初心者がまず覚えるとよい判断表
| タスク | 特に優先して残したい情報 |
|---|---|
| 感情分析 | 否定語、感情語、程度を表す語 |
| 検索 / RAG | キーワード、専門用語、数字、固有名詞 |
| NER | 大文字・小文字、書式、固有名詞の境界 |
| 伝統的なテキスト分類 | やや強めのクリーニングがよく使われる |
この表は絶対ルールではありませんが、初心者がまず大事な直感を作るのに役立ちます。
- 前処理が適切かどうかは、必ずタスクに戻って考える
まずは最小の前処理関数を動かしてみよう
ここでは、英語の例で説明します。英語のほうが標準ライブラリだけで簡単に示しやすいからです。
考え方は日本語にも同じように当てはまりますが、日本語では通常、より専門的な分かち書きツールが必要です。
import re
stopwords = {"the", "is", "a", "an", "and", "to", "of", "in"}
def preprocess(text):
text = text.lower() # 1. 小文字化
text = re.sub(r"http\\S+", " ", text) # 2. リンク削除
text = re.sub(r"[^a-z0-9\\s]", " ", text) # 3. 特殊記号を削除
text = re.sub(r"\\s+", " ", text).strip() # 4. 余分な空白をまとめる
tokens = text.split() # 5. 簡単な分割
tokens = [t for t in tokens if t not in stopwords] # 6. ストップワード削除
return tokens
sample = "The movie is AMAZING, and the ending is full of surprises!"
print(preprocess(sample))
実行結果の例:
['movie', 'amazing', 'ending', 'full', 'surprises']
大文字小文字、句読点、一般的なストップワード、余分な記号が取り除かれ、感情やトピックを持つ単語が残ります。
この例でいちばん見てほしいことは?
テキスト前処理は、ふしぎなブラックボックスではなく、
とても素朴な小さな処理の連なりです。
本当に大事なのは、
- それぞれの処理がなぜあるのか
- 今のタスクに本当に合っているのか
です。
「否定語を残す」小さな比較
import re
stopwords_keep_not = {"the", "is", "a", "an", "and", "to", "of", "in"}
stopwords_drop_not = {"the", "is", "a", "an", "and", "to", "of", "in", "not"}
def preprocess_with_stopwords(text, stopwords):
text = text.lower()
text = re.sub(r"[^a-z0-9\\s]", " ", text)
text = re.sub(r"\\s+", " ", text).strip()
tokens = text.split()
return [t for t in tokens if t not in stopwords]
sample = "This movie is not good"
print("keep_not :", preprocess_with_stopwords(sample, stopwords_keep_not))
print("drop_not :", preprocess_with_stopwords(sample, stopwords_drop_not))
実行結果の例:
keep_not : ['this', 'movie', 'not', 'good']
drop_not : ['this', 'movie', 'good']
2つ目の結果では not が消え、意味が静かに反転します。だから、ストップワードのルールはタスクに合わせて選ぶ必要があります。
この例は初心者にとても向いています。なぜなら、
- 一見すると「大事ではなさそう」な語
- 実は意味の方向を決める重要な語
があることを、はっきり見せてくれるからです。
なぜ小文字化はよく使われるのか?
形を統一するため
英語では、
AppleappleAPPLE
を、多くのタスクで同じ語として扱いたいことがあります。
でも、いつもやるべきとは限らない
たとえば、
- NER
- ブランド名の認識
では、大文字・小文字そのものが重要な情報になることがあります。
だから覚えておきたいのは、
- 前処理は必ずタスクとセットで考える
ということです。
なぜ分かち書きはそんなに重要なのか?
モデルは文をそのまま直接扱うわけではないから
モデルはふつう、もっと小さな単位を使います。
- 単語
- サブワード
- 文字
英語と日本語では事情が違う
英語はスペースがあるので、
簡単な場面では split() で分けられます。
日本語には自然なスペースがないので、
分かち書きの問題はもっと難しくなります。
たとえば、
- 「自然言語処理」
をどう区切るかは、
- 自然言語処理
なのか
- 自然 / 言語 / 処理
なのかで、後の表現やモデルの性能に直接影響します。
日本語の分かち書きでまず持っておきたい感覚
専門ツールをまだ使わないとしても、まず次の感覚を持ってください。
日本語テキストには、もともと単語の境界がはっきり書かれていない。
ストップワードはなぜ役に立つのに、なぜ危険なのか?
役に立つ場面
次のような、高頻度だけど区別力の弱い語は、
- the
- is
- and
伝統的なモデルではノイズになりやすいです。
危険な場面
一見すると目立たない語が、とても重要な意味を持つことがあります。
たとえば、
not good
から not を消すと、意味が逆になります。
だからストップワードは「必ず消すもの」ではない
より自然な考え方は、
- これは選択肢のひとつ
- 使うかどうかはタスク次第
です。
もう少しだけまとまった練習
import re
stopwords = {"the", "is", "a", "an", "and", "to", "of", "in", "this"}
def preprocess(text):
text = text.lower()
text = re.sub(r"http\\S+", " ", text)
text = re.sub(r"[^a-z0-9\\s]", " ", text)
text = re.sub(r"\\s+", " ", text).strip()
tokens = text.split()
tokens = [t for t in tokens if t not in stopwords]
return tokens
texts = [
"This course is easy to follow!",
"The examples are clear and practical.",
"I love the hands-on exercises in this class.",
]
for text in texts:
print("原文 :", text)
print("処理後 :", preprocess(text))
print("-" * 30)
実行結果の例:
原文 : This course is easy to follow!
処理後 : ['course', 'easy', 'follow']
------------------------------
原文 : The examples are clear and practical.
処理後 : ['examples', 'are', 'clear', 'practical']
------------------------------
原文 : I love the hands-on exercises in this class.
処理後 : ['i', 'love', 'hands', 'on', 'exercises', 'class']
------------------------------
この前後比較を習慣にしてください。重要な語が消えていたら、モデルを学習する前にルールを直します。
この例で本当に見るべきことは?
見るべきなのは、
- 何が残ったか
- 何が消えたか
- その削除がタスクに合っているか
です。
これは、単に「前処理の手順を覚える」よりずっと大事です。
伝統的なモデルと事前学習済みモデルでは、なぜ前処理の考え方が違うのか?
伝統的な機械学習
モデルが浅めなので、
ノイズの影響を受けやすく、手作業の前処理に強く依存しがちです。
事前学習済みモデル / 大規模モデル
多くの場合、モデル自身の tokenizer にかなり頼ります。
そのため、外側で過度にクリーニングすると、逆に次のようなことが起こりえます。
- 元の構造が壊れる
- モデルが使える情報を失う
とても重要な判断
すべての NLP で、同じ前処理戦略を使うわけではありません。
初めて NLP プロジェクトを作るときの、いちばん安全な順番
より安全なのは、たいてい次の順番です。
- まずタスクをはっきりさせる
- まず軽い baseline の前処理を書く
- 出力でどんな情報が消えたかを見る
- そのあとで、ルールを増やすか決める
こうすると、最初からたくさんの正規表現やルールを積むより、問題を見つけやすくなります。
初心者がよくやる間違い
前処理は多いほど高度だと思う
違います。
情報を消しすぎると、かえって性能が悪くなることがあります。
タスクを区別せず、同じルールを使う
テキスト分類、検索、NER、RAG では、前処理の方針が違うことがよくあります。
日本語でもそのまま split() する
多くのタスクでは、それだけでは不十分なことが多いです。
これをプロジェクトにするなら、何を見せるとよいか
見せる価値が高いのは、次のような点です。
- どれだけ正規表現を書いたか
ではなく、
- 元のテキストがどうなっていたか
- 処理後のテキストがどうなったか
- 何が残ったか
- 何が消えたか
- なぜこの処理が今のタスクに合うのか
こうすると、見る人にも次が伝わりやすくなります。
- あなたはタスク要求を理解している
- 単に機械的にテキストをきれいにしているだけではない
まとめ
テキスト前処理でいちばん大事なのは、「きれいに洗う」ことではなく、
タスクに合わせて、テキストをモデルが扱いやすい形に整えること。
次の節では、さらに先に進んで、次の重要な問いを扱います。
テキストをどうやって数字で表すのか?
この節でいちばん持ち帰ってほしいこと
- テキスト前処理は固定テンプレートではなく、タスク駆動で選ぶ
- 消す情報と残す情報は、どちらも同じくらい重要
- 最初のプロジェクトでは、軽い baseline から始めるほうが、たいてい安定している
練習
preprocess()に数字の置換ロジックを追加して、すべての数字を<num>に置き換えてみましょう。notをストップワードに追加して、感情文でどんな問題が起こるか観察してみましょう。- 自分で短いコメントを 5 件集めて前処理をかけ、どの情報が残って、どれが消えたか確認してみましょう。
- 考えてみましょう: NER の場面で、小文字化が逆に有害になるのはなぜでしょうか。