11.7.1 プロジェクトロードマップ:評価できる NLP パイプラインを作る
この章の目的は、モデル名を増やすことではありません。テキストタスクを定義し、入力と出力を固定し、baseline を作り、評価と失敗分析まで残すことです。
先に全体像を見る
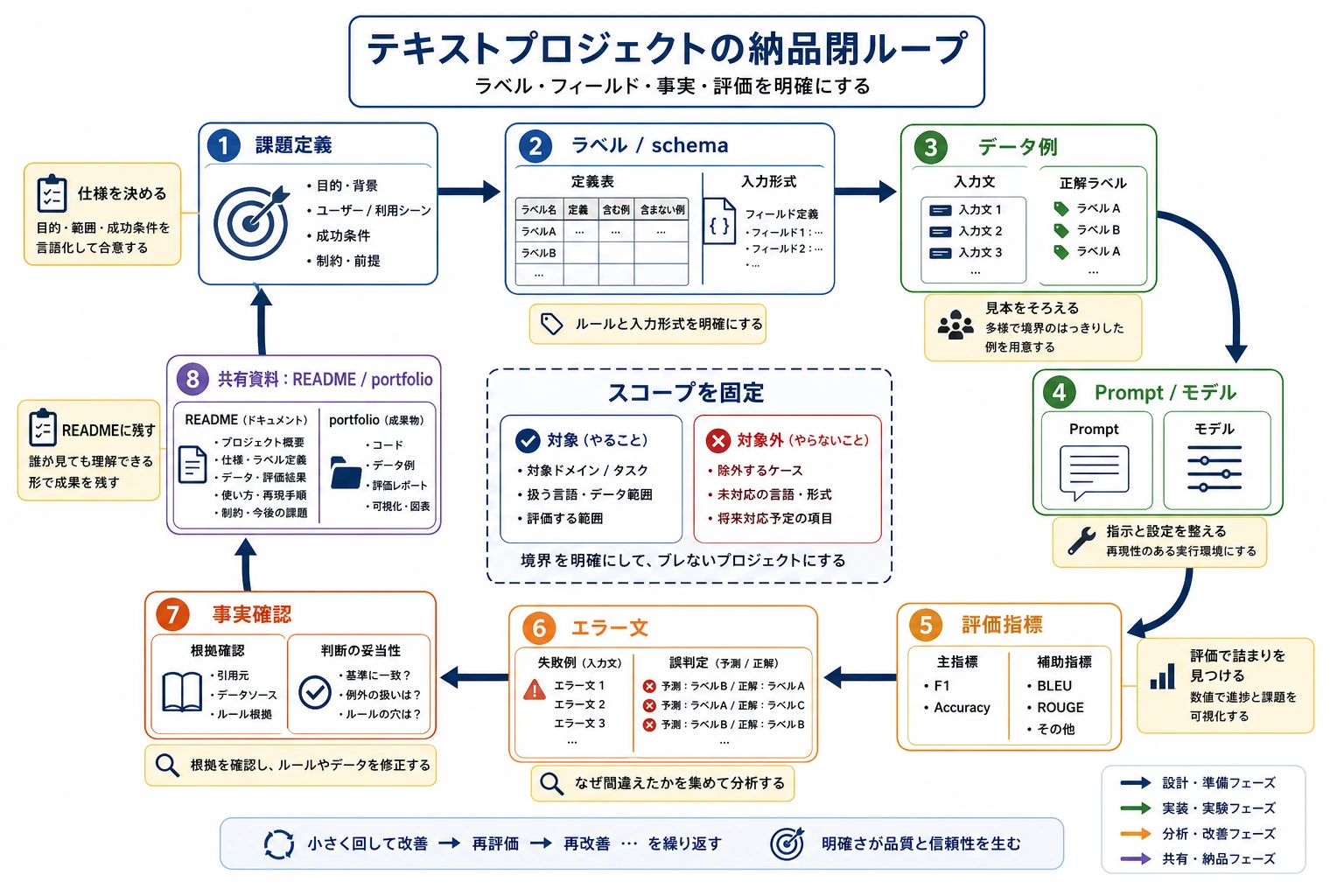
| 順番 | 作業 | 成果物 |
|---|---|---|
| 1 | タスク定義 | 分類、抽出、要約、QA のどれかを決める |
| 2 | baseline | 最小コードで入出力を固定する |
| 3 | 評価 | 成功例と失敗例を同じ形式で見る |
| 4 | 納品 | README、サンプル、指標、改善案を残す |
作品集に残す証拠
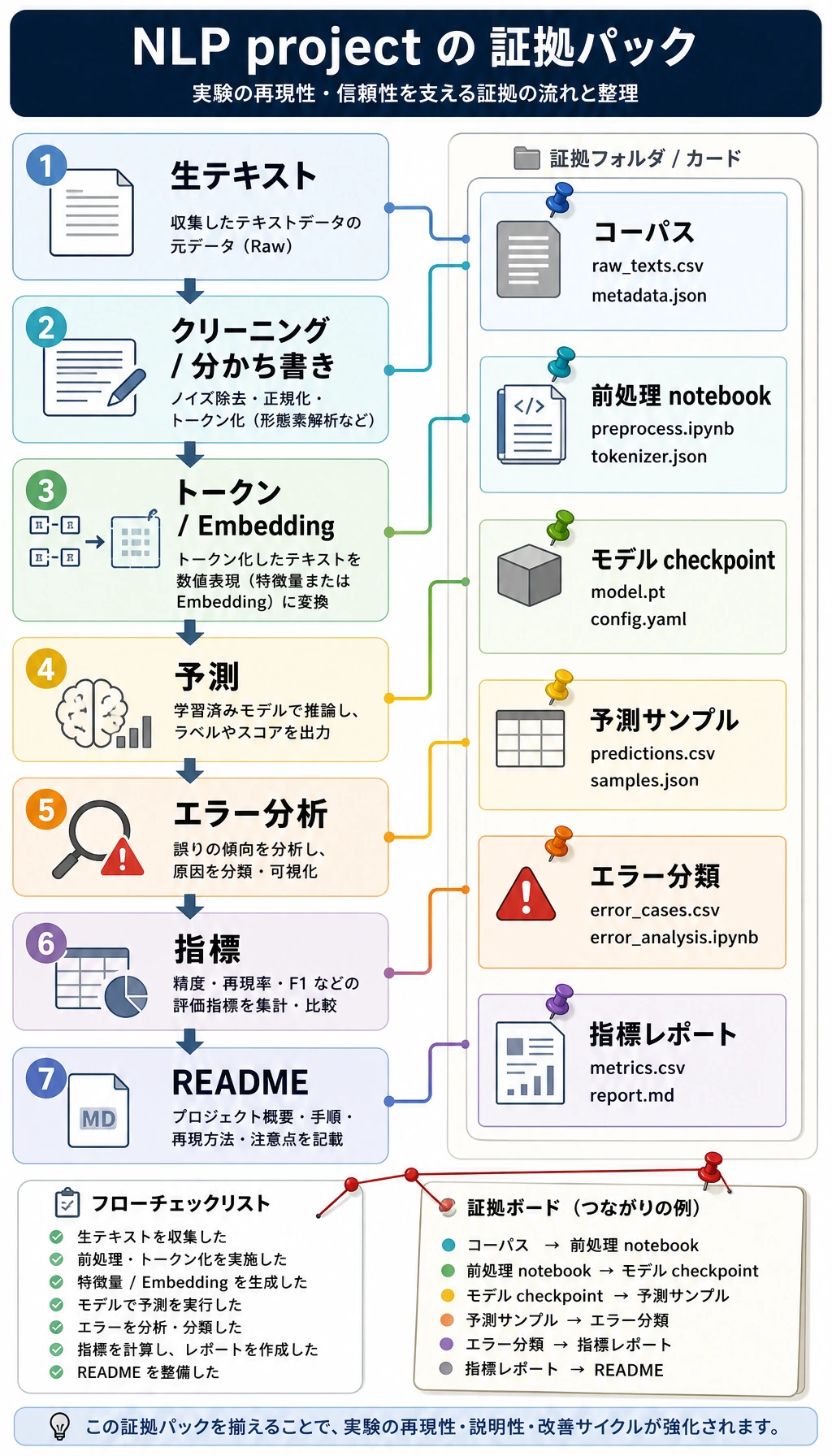
よい NLP プロジェクトは、自然な出力を 1 つ見せるだけでは足りません。なぜそのタスクなのか、何を入力し、何を出力し、どう評価したのかを残します。
project = {
"task": "information extraction",
"has_schema": True,
"has_baseline": True,
"has_eval_cases": True,
"has_failure_case": True,
}
ready = all(project[key] for key in ["has_schema", "has_baseline", "has_eval_cases", "has_failure_case"])
print("task:", project["task"])
print("portfolio_ready:", ready)
期待される出力:
task: information extraction
portfolio_ready: True
操作のコツ:schema は、抽出したいフィールドの設計図です。情報抽出なら、名前、日付、金額、根拠文などをあらかじめ決めておきます。
ワークショップへ進む

大きなプロジェクトに入る前に、11.7.6 実践:再現可能な NLP ミニパイプラインを作る を先に動かすのがおすすめです。tokenization、TF-IDF、分類、検索 QA、要約、抽出、評価、失敗分析を 1 本の小さな流れで確認できます。
プロジェクト納品物の基準
| 納品物 | 最低要件 |
|---|---|
| README | 目的、実行方法、依存関係、サンプルを書く |
| 入出力サンプル | 成功例と失敗例を少なくとも 1 つずつ残す |
| 評価記録 | 精度、再現率、F1、または人手評価を書く |
| ラベル / schema | ラベルや抽出フィールドの意味を説明する |
| 改善案 | 次に直すべき失敗を 1 つ書く |
通過条件
| チェック | 合格ライン |
|---|---|
| タスク境界 | 分類、抽出、要約、QA の違いを説明できる |
| baseline | 最小コードで入出力を確認できる |
| 評価 | 成功例だけでなく失敗例も記録できる |
| 納品 | README とサンプルで再現できる形にできる |