11.1.1 文本基础路线图:Token、清洗、表示
文本不是天然可计算对象。在分类、抽取、总结或问答之前,需要先把原始文本变成稳定单元和特征。
先看文本流水线
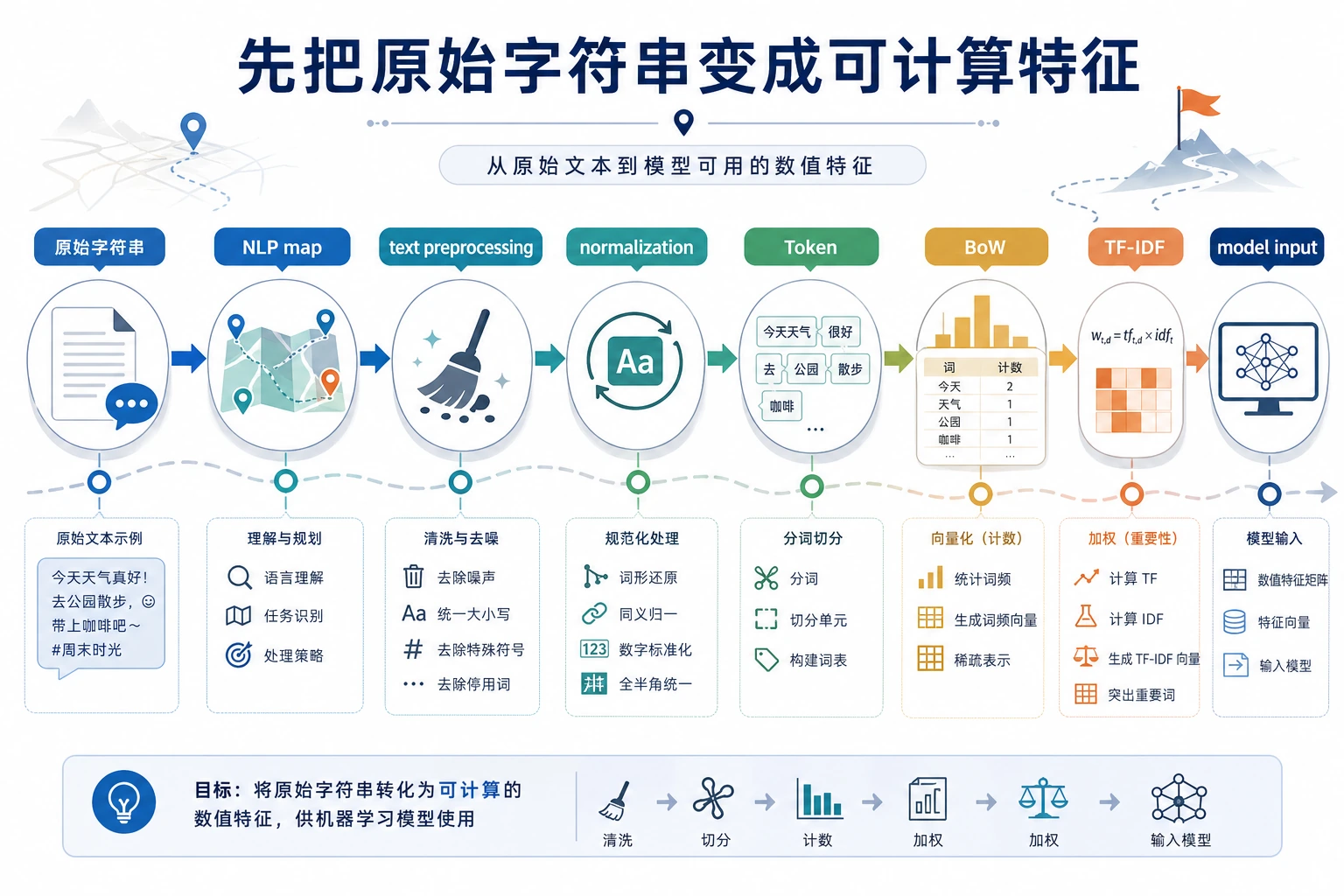


第一个习惯是先问:输入文本是什么、任务是什么、系统应该产生什么输出形态?
跑一个 Token 和词表检查
text = "RAG answers need citations"
tokens = text.lower().split()
vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}
ids = [vocab[token] for token in tokens]
print("tokens:", tokens)
print("ids:", ids)
print("vocab_size:", len(vocab))
预期输出:
tokens: ['rag', 'answers', 'need', 'citations']
ids: [3, 0, 2, 1]
vocab_size: 4
如果分词不稳定,下游任务也会跟着不稳定。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | NLP 任务地图 | 匹配分类、标注、抽取、问答、总结 |
| 2 | 预处理 | 规范化文本、切分 token、处理噪声和边界 |
| 3 | 文本表示 | 构建 tokens、ids、词表、稀疏特征或向量 |
通过标准
如果你能接收原始文本、完成分词、解释任务输出形态,并在项目笔记里保存一个预处理例子,就通过了本章。