11.2.3 上下文词嵌入
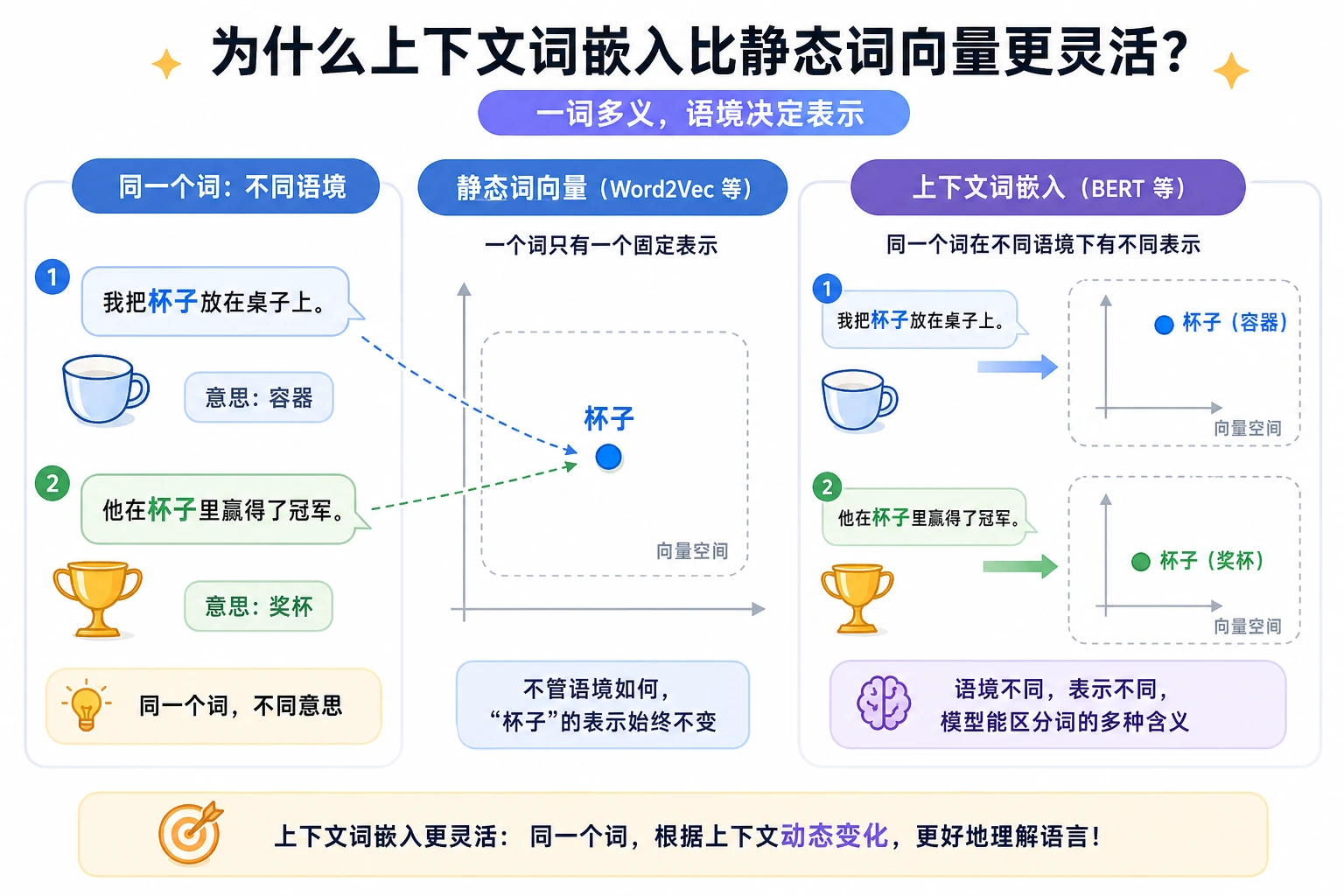
上一节我们讲了词嵌入能把词映射到语义空间。 但它有一个很快就会遇到的大问题:
同一个词,在不同上下文里可能根本不是一个意思。
如果每个词永远只有一个固定向量,这件事就很难处理。
这正是“上下文化表示”出现的原因。
学习目标
- 理解固定词向量为什么不够
- 理解上下文化表示的核心思想
- 通过可运行示例建立“同词不同向量”的直觉
- 理解为什么这一步是从传统 NLP 走向现代预训练模型的关键转折
先建立一张地图
上下文化表示这节最适合新人的理解顺序不是“它只是更强的词向量”,而是先看清:
所以这节真正想解决的是:
- 为什么固定词向量迟早会不够
- 为什么“词义取决于上下文”会改变整个 NLP 主线
一个更适合新人的总类比
你可以把静态词向量和上下文化表示理解成:
- 静态词向量像词典里的“固定头像”
- 上下文化表示像演员在不同剧情里的“角色状态”
同一个演员是同一个人, 但在不同场景里,他的表情、动作、身份角色会不同。 同样地:
- 同一个词在不同句子里
- 也不应该永远长成同一个向量
一、固定词向量的根本局限是什么?
一个词可能有多个义项
经典例子:
bank
它可以指:
- 银行
- 河岸
如果它永远只有一个固定向量, 那这个向量到底该更像哪种含义?
所以固定词向量在多义词上会很吃力
哪怕静态 embedding 再好, 它仍然会把:
- “open a bank account”
- “sit on the river bank”
里的 bank 看成同一个向量。
一个类比
固定词向量像给每个人发一张终身不变的证件照。 上下文化表示更像根据当前场景给出动态工作照:
- 在银行上班时一张
- 在河边散步时一张
二、上下文化表示到底在做什么?
核心思想
不是“每个词对应一个向量”, 而是:
- 每个词在当前句子里对应一个向量
也就是说, 表示不只由词本身决定, 还由它周围的上下文决定。
为什么这很重要?
因为 NLP 真正的难点从来不只是“词是什么”, 而是:
- 词在这句话里是什么意思
它改变了什么?
这一步让表示学习从:
- 静态查表
走向了:
- 动态语义编码
这也是现代预训练模型能明显提升很多任务效果的重要原因之一。
三、先跑一个“同词不同向量”的直观示例
下面这个例子不会实现真正的 BERT, 但它会非常清楚地模拟“词向量 + 上下文修正”的过程。
base_embeddings = {
"bank": [0.5, 0.5],
"money": [0.9, 0.1],
"river": [0.1, 0.9],
}
context_shifts = {
"finance": [0.3, -0.2],
"nature": [-0.2, 0.3],
}
def contextualize(word, context_type):
base = base_embeddings[word]
shift = context_shifts[context_type]
return [round(base[0] + shift[0], 3), round(base[1] + shift[1], 3)]
bank_in_finance = contextualize("bank", "finance")
bank_in_nature = contextualize("bank", "nature")
print("bank in finance:", bank_in_finance)
print("bank in nature :", bank_in_nature)
预期输出:
bank in finance: [0.8, 0.3]
bank in nature : [0.3, 0.8]
同一个词从同一个基础向量出发,但金融上下文会把它推向金融语义,自然上下文会把它推向河岸语义。
这段代码当然不是真实上下文模型
但它抓住了最重要的一层直觉:
- 词本体有一个基础表示
- 上下文会把这个表示往不同方向推
为什么这个直觉足够重要?
因为你后面学 BERT、GPT、T5 时, 都会不断看到一个事实:
- token 最终表示取决于整段上下文
第一次学这节最该先记什么?
最值得先记住的是:
- 静态 embedding 在多义词上天然吃力
- 上下文化表示是在回答“这个词在这句话里是什么意思”
- 这正是现代预训练模型真正变强的关键一步
再看一个最小“上下文窗口影响表示”的示例
sentences = [
("bank", ["open", "account", "money"], "finance"),
("bank", ["river", "water", "shore"], "nature"),
]
def explain_representation(word, context_words, sense):
return {
"word": word,
"context": context_words,
"sense": sense,
}
for word, context_words, sense in sentences:
print(explain_representation(word, context_words, sense))
预期输出:
{'word': 'bank', 'context': ['open', 'account', 'money'], 'sense': 'finance'}
{'word': 'bank', 'context': ['river', 'water', 'shore'], 'sense': 'nature'}
这个输出把隐藏假设显式化了:不能只看 bank 这个词本身就判断含义,还要看周围词。
这个示例当然不是神经网络, 但它能帮助新人先建立一个非常关键的意识:
- 一个词的表示,必须连同周围上下文一起看
否则你很难说清:
- 它现在到底是哪一个义项
四、上下文化表示带来了什么实际变化?
多义词处理更自然
模型可以把同一个词在不同句子里的表示区分开。
句子和段落理解更强
因为词的表示不再孤立,而是已经融合了上下文线索。
迁移学习效果更好
很多下游任务不再需要从头学复杂表示, 而是直接利用上下文化后的隐藏状态。
为什么这一步会直接改变很多任务上限?
因为很多 NLP 任务真正难的不是:
- 这个词大概是什么意思
而是:
- 这个词在当前上下文里到底代表什么角色
一旦表示层就开始区分这件事, 很多分类、抽取和问答任务都会自然变得更稳。
如果把它放进任务里,最值得先想到哪些场景?
上下文化表示最容易在这些场景里让新人感受到价值:
- 多义词分类
- 命名实体识别
- 问答
- 机器翻译
因为这些任务真正难的,往往都不是:
- 词典里这个词大概什么意思
而是:
- 它在这句话里到底扮演什么角色
五、它和静态词向量的关系是什么?
不是完全替代,而是能力升级
静态词向量仍然有教育价值,也在某些轻量任务里有用。 但在现代 NLP 主线上,上下文化表示通常更强。
一个简单总结
- 静态 embedding:词级别固定表示
- 上下文化表示:token 在句子中的动态表示
六、最常见误区
误区一:上下文化表示只是“更大的词向量”
不对。 它的关键变化在于:
- 表示依赖上下文
误区二:同一个词不同向量只是细节优化
不是。 这一步其实改变了很多任务的上限。
误区三:有上下文化表示就不需要更上层建模了
上下文化表示很强, 但仍然要放进具体任务和具体模型里使用。
如果把它做成学习笔记或项目,最值得展示什么
最值得展示的通常不是:
- 一句“BERT 更强”
而是:
- 同一个词在不同句子里的义项对比
- 静态 embedding 和上下文化表示的区别
- 哪类任务会特别依赖这种能力
- 为什么这一步会成为现代 NLP 的分水岭
这样别人一眼就能看出:
- 你理解的是“为什么会变强”
- 不只是记住模型名字
小结
这节最重要的是建立一个判断:
固定词向量只能回答“这个词一般像什么”,上下文化表示则开始回答“这个词在这句话里到底是什么意思”。
这一步,是现代 NLP 真正进入预训练时代的重要门槛。
这节最该带走什么
- 上下文化表示不是“更大的词向量”,而是“会随句子变化的表示”
- 它是从传统 NLP 走向现代预训练模型的关键转折点
- 后面学 BERT、GPT、T5 时,都应该把这条线带进去理解
练习
- 给示例再加一个词
apple,分别模拟它在“水果”和“公司”场景中的表示变化。 - 用自己的话解释:为什么固定词向量处理多义词会吃力?
- 为什么说上下文化表示让很多下游任务更容易做?
- 想一想:如果表示已经依赖上下文,那“词本身”还重要吗?为什么?