12.2.1 画像生成ロードマップ:プロンプト、制御、レビュー
画像生成は、1 行のプロンプトで終わる作業ではありません。意図、プロンプト記録、パラメータ、必要な制御、候補比較、レビューまで含むワークフローです。
まずパイプラインを見る



最初の習慣は、何を作りたいか、どのモードを使ったか、どの seed やパラメータが結果を左右したか、出力前に何を確認すべきかを記録することです。
プロンプト記録を作る
import json
brief = {
"topic": "RAG basics",
"audience": "beginners",
"style": "clean editorial cover",
}
prompt = f"{brief['style']} for {brief['topic']}, friendly visual metaphor for {brief['audience']}, clear layout"
record = {
"mode": "text-to-image",
"prompt": prompt,
"negative_prompt": "blurry, watermark, unreadable text",
"seed": 42,
"review": ["legibility", "copyright", "brand safety"],
}
print(json.dumps(record, indent=2))
期待される出力:
{
"mode": "text-to-image",
"prompt": "clean editorial cover for RAG basics, friendly visual metaphor for beginners, clear layout",
"negative_prompt": "blurry, watermark, unreadable text",
"seed": 42,
"review": [
"legibility",
"copyright",
"brand safety"
]
}
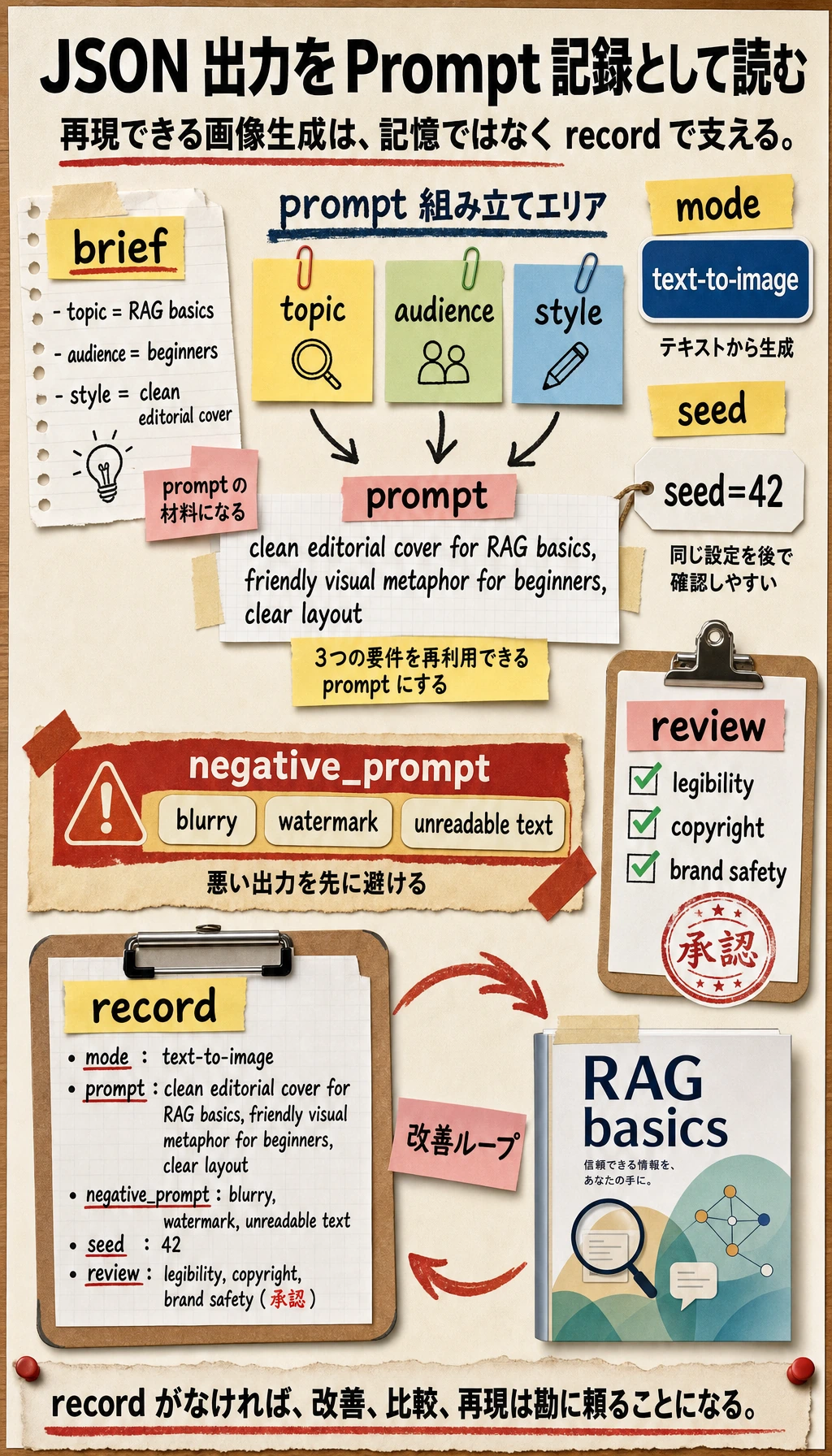
プロンプト記録を再現できなければ、画像を安定して改善することも難しくなります。
この順番で学ぶ
| ステップ | 読む内容 | 練習の成果 |
|---|---|---|
| 1 | 拡散の直感 | ノイズ、デノイズ、seed、サンプリングを説明する |
| 2 | Stable Diffusion の部品 | text encoder、U-Net、VAE、latent space を図にする |
| 3 | 応用と制御 | text-to-image、image-to-image、inpainting、ControlNet、LoRA を比較する |
通過条件
プロンプト記録を書き、選んだ生成モードを説明し、3 つの候補メモを残し、出力前に少なくとも 1 つのレビューリスクを記録できれば、この章は通過です。