11.5.3 NLP における注意機構
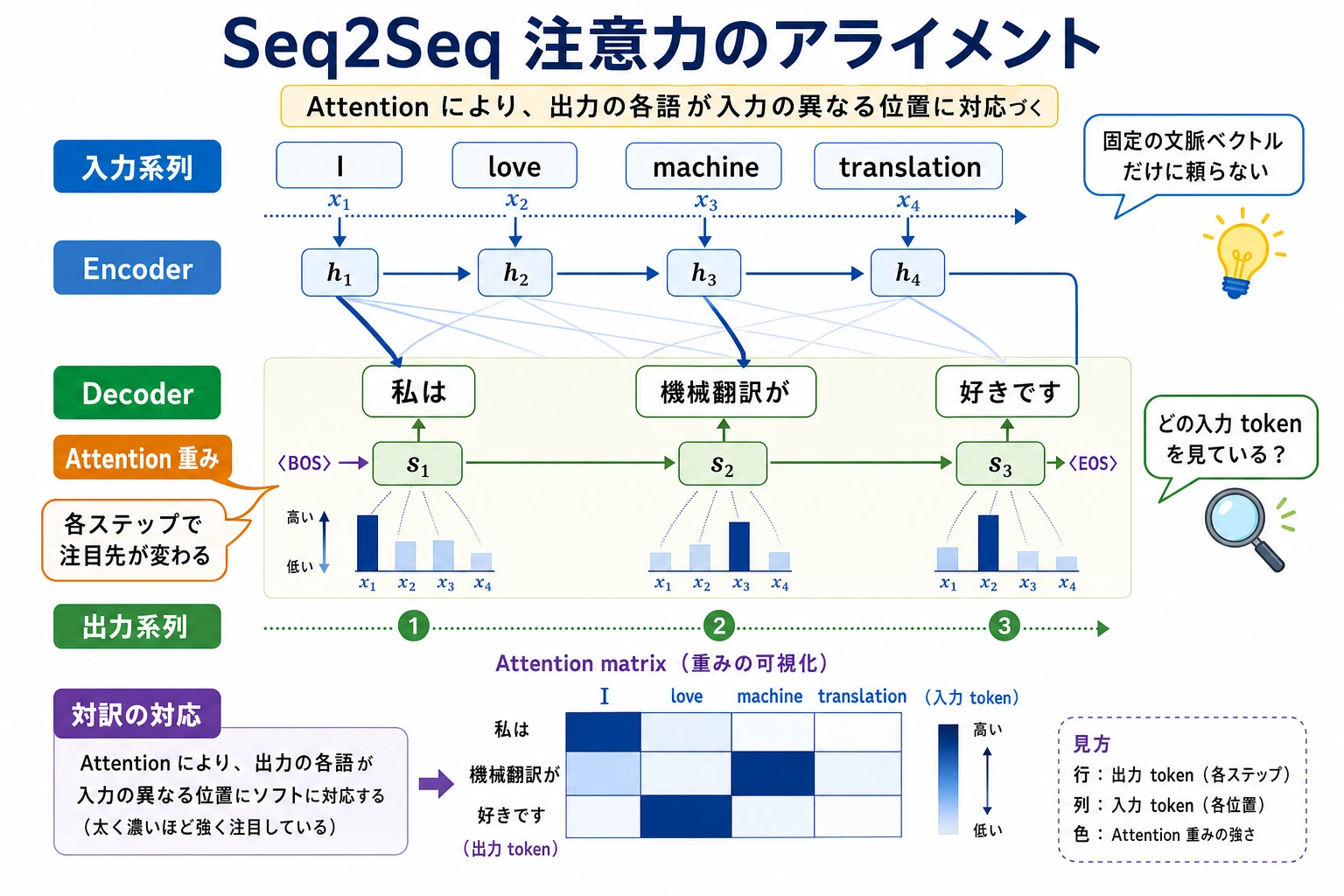
前の節では、Seq2Seq の典型的な問題として次の点を見ました。
- 入力を 1 つの固定ベクトルに圧縮すると、長い文では情報が失われやすい
注意機構が解決するのは、まさにこのボトルネックです。
各出力語を生成するとき、1 つの固定表現だけに頼るのではなく、入力系列の中で最も関連のある位置をもう一度見に行ける。
学習目標
- 注意機構が生まれた背景を理解する
- 「アライメント」と「重み付き集約」の核となる直感を理解する
- 実行できる例を通して、注意重みとコンテキストベクトルを理解する
- 注意機構と後続の Transformer とのつながりをつかむ
まずは地図を描こう
この節は、初心者にとって次の順番で理解するのが最もおすすめです。
つまり、この節が本当に解決したいのは次のことです。
- なぜ固定ベクトルがボトルネックになるのか
- なぜ「動的に入力を見る」ほうが自然なのか
初心者向けの、よりわかりやすいたとえ
注意機構は次のように考えると理解しやすいです。
- 読解問題を解くとき、問題文を見ながら原文に戻って関連する文を探す
注意機構がないと、
全文を読み終えた最後の一瞬で、文章全体をあいまいな印象に圧縮してから答えるようなものです。
これではだんだん苦しくなります。
注意機構があると、モデルはより次のように動けます。
- 今この単語を生成したいが、入力のどこを重点的に見ればいいのか?
一、なぜ Seq2Seq に注意機構が必要なのか?
固定長のエンコードは情報を失いやすい
入力が次のような場合は特に問題になります。
- とても長い文
- 複雑な段落
これを 1 つの固定ベクトルに押し込むと、
後ろ側のデコーダはかなり苦しくなります。
デコーダは時間ステップごとに注目点が違うべき
たとえば翻訳では、
- 1 つ目の単語を出すときは入力の前半に注目する
- 後ろの単語を出すときは入力の別の位置に注目する
そのため、「出力の全過程が同じベクトルだけを見る」のは自然ではありません。
注意機構の核となる直感
出力を 1 つ生成するたびに、
現在のデコード状態に基づいて次のように問いかけます。
- 入力系列の中で、今いちばん関係があるのは誰?
そして、その関連位置を重み付きで集約して現在のコンテキストを作ります。
二、まずは最小の注意機構の例を動かしてみよう
import math
encoder_states = [
[1.0, 0.0],
[0.5, 0.5],
[0.0, 1.0],
]
query = [0.7, 0.3]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
def softmax(values):
exps = [math.exp(v) for v in values]
total = sum(exps)
return [round(v / total, 4) for v in exps]
scores = [dot(state, query) for state in encoder_states]
weights = softmax(scores)
context = [0.0, 0.0]
for w, state in zip(weights, encoder_states):
context = [context[i] + w * state[i] for i in range(len(context))]
print("scores :", [round(x, 4) for x in scores])
print("weights:", weights)
print("context:", [round(x, 4) for x in context])
実行結果の例:
scores : [0.7, 0.5, 0.3]
weights: [0.4018, 0.3289, 0.2693]
context: [0.5663, 0.4337]
最も高い重みは1つ目の encoder state にありますが、context ベクトルはすべての位置を混ぜています。Attention は固定的な参照ではなく、重み付きで読む仕組みです。
このコードでまず見るべきポイントは?
最も大事なのは 3 ステップです。
queryと各encoder_stateを使ってスコアを計算するsoftmaxで注意重みを得る- 重みを使って encoder states の重み付き平均を取る
なぜこれだけで注意機構の本質が表れているのか?
次の 2 つに答えているからです。
- どこを見るか
- どれくらい見るか
これが注意機構の最も大事な直感です。
初心者が最初に覚えるべき 3 つは?
queryは「今なにを探しているか」を表すscoreは「各入力位置が今の要求とどれだけ関係があるか」を表すweightsは softmax を通して、「各位置をどれくらい見るか」を決める
もう 1 つ、最小の「出力語と入力語のアライメント」の例を見よう
source_tokens = ["i", "love", "nlp"]
attention_weights = [0.1, 0.2, 0.7]
for token, weight in zip(source_tokens, attention_weights):
print({"source_token": token, "weight": weight})
実行結果の例:
{'source_token': 'i', 'weight': 0.1}
{'source_token': 'love', 'weight': 0.2}
{'source_token': 'nlp', 'weight': 0.7}
この出力ステップでは、モデルが主に nlp の位置を見ていると読めます。
この例は実際のモデルよりずっと単純ですが、
初心者がまずイメージをつかむのにとても役立ちます。
- 今の出力語を生成するとき
- モデルは入力全体を均等に見るのではなく
- より関連の高い位置に、より強く注意を向ける
三、注意機構はなぜ Seq2Seq を大きく改善するのか?
情報ボトルネックを和らげるから
入力は、もはや 1 つの固定ベクトルだけを通してデコーダに渡されるわけではありません。
入力と出力のアライメントが自然になるから
翻訳ではもともと、「ある出力語が入力のどの語に対応するか」という構造があります。
注意機構は、この対応関係を学びやすくします。
これが古典的な Seq2Seq から Transformer への橋渡しになる
後で学ぶ Transformer では、注意機構がさらに広く使われます。
ただし、この節で学ぶ直感の土台は同じです。
初めて学ぶときは、数式よりもまず流れを見るのが大事
理解しやすい順番は、だいたい次の通りです。
- まず、固定エンコードがなぜ詰まりやすいかを見る
- 次に、
queryが何を尋ねているかを見る - その後、
scoreとweightがどう注意を配るかを見る - 最後に、コンテキストベクトルがどう計算されるかを見る
この順番なら、最初から行列の式だけを追うより、ずっと安定して理解できます。
四、つまずきやすいポイント
誤解 1:注意機構はただの重み付き平均の小技
それだけではありません。
モデルが入力情報へアクセスする方法そのものを変えています。
誤解 2:注意機構があればもう情報は失われない
そうではありません。
長い系列には依然として難しさがありますが、ボトルネックはかなり和らぎます。
誤解 3:注意機構 = Transformer
注意機構はもっと大きな概念です。Transformer は、それを土台に発展した完全なアーキテクチャです。
これをノートやプロジェクトにするなら、何を見せるとよいか
よく見せると効果的なのは、次のようなものです。
- 「attention を使いました」という 1 行だけ
ではなく、
- 入力系列
- 現在の出力位置
- 各入力位置の重み
- どの位置に重点を置いたか
これを見せると、見る人はすぐに次のことを理解できます。
- あなたが理解しているのは、注意機構が「入力をどうアライメントするか」
- 単に流行の用語を知っているだけではない
まとめ
この節で一番大事なのは、次の橋渡しの直感を作ることです。
注意機構は、デコーダが各ステップを生成するときに、入力系列の中で最も関連のある位置をもう一度見られるようにし、固定エンコードベクトルの情報ボトルネックを和らげる。
ここがしっかり理解できれば、次に Transformer の self-attention を学ぶとき、かなり楽になります。
この節で一番持ち帰るべきこと
- 注意機構は小技ではなく、モデルが入力情報へアクセスする方法を変えるもの
- もっとも重要な価値は、固定エンコードのボトルネックを和らげること
- この節がわかれば、後の Transformer はかなりスムーズに理解できる
練習
queryを少し変えて、注意重みがどう変わるか見てみましょう。- 自分の言葉で説明してみましょう。なぜ Seq2Seq では、固定ベクトルだけを見るのではなく「動的に入力を見る」必要があるのでしょうか?
weightsはなぜ softmax を通す必要があるのでしょうか?- この節の注意機構と、後で学ぶ Transformer の self-attention の共通点は何か、考えてみましょう。